集群环境可能出现的问题
在上一篇博客我们介绍了如何在自己的项目中从无到有的添加了Quartz定时调度引擎,其实就是一个Quartz 和Spring的整合过程,很容易实现,但是我们现在企业中项目通常都是部署在集群环境中的,这样我们之前的定时调度就会出现问题了,因为我们的定时任务都加载在内存中的,每个集群节点中的调度器都会去执行,这就会存在重复执行和资源竞争的问题,那么如何来解决这样的问题呢,往下面看吧...
解决方案
在一般的企业中解决类似的问题一般都是在一个note上部署Quartz其他note不部署(或者是在其他几个机器加IP地址过滤),但是这样集群对于定时任务来说就没有什么意义了,而且存在着单点故障的隐患,也就是这台部署着Quartz的机器一旦挂了,我们的定时任务就停止服务了,这绝对不是我们想要的。
Quartz本身是支持集群的,我们通过Quartz的集群方式来解决这样的问题。
Quartz集群
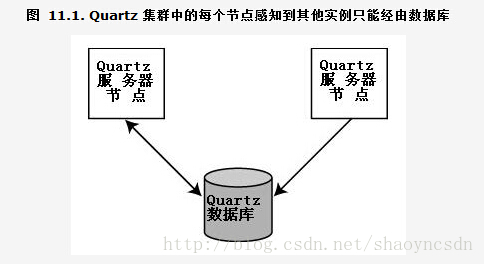
虽然单个 Quartz 实例能给予你很好的 Job调度能力,但它不能令典型的企业需求,如可伸缩性、高可靠性满足。假如你需要故障转移的能力并能运行日益增多的 Job,Quartz 集群势必成为你方言的一部分了,并且即使是其中一台机器在最糟的时间崩溃了也能确保所有的 Job 得到执行。 QuartzJob Scheduling Framework
了解了Quartz集群的好处,接下来就对我们之前的工程进行改造,增加Quartz集群特性。
Quartz集群中节点依赖于数据库来传播 Scheduler 实例的状态,你只能在使用 JDBC JobStore 时应用 Quartz 集群
所以我们集群的第一步就是建立Quartz所需要的12张表:
1、建表
在quartz核心包里面通过quartz提供的建表语句建立相关表结构
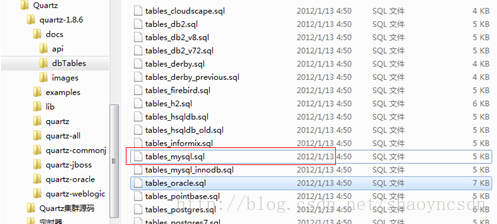
生成的表结构如下
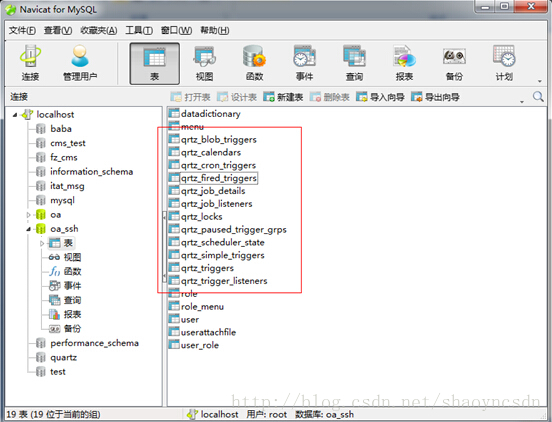
这几张表是用于存储任务信息,触发器,调度器,集群节点等信息
详细解释:
QRTZ_CRON_TRIGGERS 存储Cron Trigger,包括Cron 表达式和时区信息
QRTZ_PAUSED_TRIGGER_GRPS 存储已暂停的Trigger 组的信息
QRTZ_LOCKS 存储程序的非观锁的信息(假如使用了悲观锁)
QRTZ_JOB_LISTENERS 存储有关已配置的JobListener 的信息
QRTZ_BLOG_TRIGGERS Trigger 作为Blob 类型存储(用于Quartz 用户用JDBC 创建他们自己定制的Trigger 类型,JobStore并不知道如何存储实例的时候)
QRTZ_TRIGGERS 存储已配置的Trigger 的信息
所有的表默认以前缀QRTZ_开始。可以通过在quartz.properties配置修改(org.quartz.jobStore.tablePrefix= QRTZ_)。
2、编写quartz.properties文件
建立 quartz.properties文件把它放在工程的 src 目录下,内容如下:

1 #============================================================================ 2 3 # Configure Main Scheduler Properties 4 5 #============================================================================ 6 7 8 9 org.quartz.scheduler.instanceName = Mscheduler 10 11 org.quartz.scheduler.instanceId = AUTO 12 13 org.quartz.jobStore.clusterCheckinInterval=20000 14 15 16 17 #============================================================================ 18 19 # Configure ThreadPool 20 21 #============================================================================ 22 23 24 25 org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool 26 27 org.quartz.threadPool.threadCount = 3 28 29 org.quartz.threadPool.threadPriority = 5 30 31 32 33 #============================================================================ 34 35 # Configure JobStore 36 37 #============================================================================ 38 39 40 41 #org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore 42 43 44 45 org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX 46 47 #org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate 48 49 org.quartz.jobStore.useProperties = true 50 51 #org.quartz.jobStore.dataSource = myDS 52 53 org.quartz.jobStore.tablePrefix = QRTZ_ 54 55 org.quartz.jobStore.isClustered = true 56 57 org.quartz.jobStore.maxMisfiresToHandleAtATime=1 58 59 #============================================================================ 60 61 # Configure Datasources 62 63 #============================================================================ 64 65 66 67 #mysql 68 69 #org.quartz.dataSource.myDS.driver = com.ibm.db2.jcc.DB2Driver 70 71 #org.quartz.dataSource.myDS.URL = jdbc:db2://localhost:50000/db 72 73 #org.quartz.dataSource.myDS.user = db2 74 75 #org.quartz.dataSource.myDS.password = db2 76 77 #org.quartz.dataSource.myDS.maxConnections = 5 78 79 80 81 #oracle 82 83 #org.quartz.dataSource.myDS.driver = oracle.jdbc.driver.OracleDriver 84 85 #org.quartz.dataSource.myDS.URL = jdbc:oracle:thin:@localhost:1521:orcl 86 87 #org.quartz.dataSource.myDS.user = scott 88 89 #org.quartz.dataSource.myDS.password = shao 90 91 #org.quartz.dataSource.myDS.maxConnections = 5 92 93 94 95 #For Tomcat 96 97 org.quartz.jobStore.driverDelegateClass =org.quartz.impl.jdbcjobstore.oracle.OracleDelegate 98 99 #For Weblogic & Websphere 100 101 #org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.WebLogicDelegate 102 103 org.quartz.jobStore.useProperties = false 104 105 org.quartz.jobStore.dataSource = myDS 106 107 108 109 110 111 #JNDI MODE 112 113 #For Tomcat 114 115 org.quartz.dataSource.myDS.jndiURL=java:comp/env/jdbc/oracle 116 117 #For Weblogic & Websphere 118 119 #org.quartz.dataSource.myDS.jndiURL=jdbc/oracle 120 121 122 123 124 125 #============================================================================ 126 127 # Configure Plugins 128 129 #============================================================================ 130 131 132 133 #org.quartz.plugin.triggHistory.class = org.quartz.plugins.history.LoggingJobHistoryPlugin 134 135 136 137 #org.quartz.plugin.jobInitializer.class = org.quartz.plugins.xml.JobInitializationPlugin 138 139 #org.quartz.plugin.jobInitializer.fileNames = jobs.xml 140 141 #org.quartz.plugin.jobInitializer.overWriteExistingJobs = true 142 143 #org.quartz.plugin.jobInitializer.failOnFileNotFound = true 144 145 #org.quartz.plugin.jobInitializer.scanInterval = 10 146 147 #org.quartz.plugin.jobInitializer.wrapInUserTransaction = false
红色加粗部分是集群需要的配置
核心配置解释如下:
org.quartz.jobStore.class 属性为JobStoreTX,
将任务持久化到数据中。因为集群中节点依赖于数据库来传播Scheduler实例的状态,你只能在使用JDBC JobStore 时应用Quartz 集群。
org.quartz.jobStore.isClustered 属性为true,通知Scheduler实例要它参与到一个集群当中。
org.quartz.jobStore.clusterCheckinInterval
属性定义了Scheduler实例检入到数据库中的频率(单位:毫秒)。
Scheduler 检查是否其他的实例到了它们应当检入的时候未检入;
这能指出一个失败的Scheduler 实例,且当前Scheduler 会以此来接管任何执行失败并可恢复的Job。
通过检入操作,Scheduler也会更新自身的状态记录。clusterChedkinInterval越小,Scheduler节点检查失败的Scheduler 实例就越频繁。默认值是 20000 (即20 秒)
3、修改spring-time.xml文件
1 <?xmlversion="1.0"encoding="UTF-8"?> 2 <!DOCTYPEbeansPUBLIC"-//SPRING//DTD BEAN//EN" 3 "http://www.springframework.org/dtd/spring-beans.dtd"> 4 <beans> 5 6 <!-- 调度器lazy-init='false'那么容器启动就会执行调度程序 --> 7 <beanid="startQuertz"lazy-init="false"autowire="no"class="org.springframework.scheduling.quartz.SchedulerFactoryBean"> 8 <property name="dataSource" ref="dataSource"/> 9 <property name="configLocation" value="classpath:quartz.properties" /> 10 <propertyname="triggers"> 11 <list> 12 <refbean="doTime"/> 13 </list> 14 </property> 15 <!-- 允许在Quartz上下文中使用Spring实例工厂 --> 16 <propertyname="applicationContextSchedulerContextKey"value="applicationContext"/> 17 </bean> 18 19 <!-- 触发器 --> 20 <beanid="doTime"class="org.springframework.scheduling.quartz.CronTriggerBean"> 21 <propertyname="jobDetail"ref="jobtask"></property> 22 <!-- cron表达式 --> 23 <propertyname="cronExpression"value="10,15,20,25,30,35,40,45,50,55 * * * * ?"></property> 24 </bean> 25 26 <!-- 任务 --> 27 <beanid="jobtask"class="org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean"> 28 <propertyname="targetObject"ref="synUsersJob"></property> 29 <propertyname="targetMethod"value="execute"></property> 30 </bean> 31 32 <!-- 要调用的工作类 --> 33 <beanid="synUsersJob"class="org.leopard.core.quartz.job.SynUsersJob"></bean> 34 35 </beans>
增加红色加粗部分代码,注入数据源和加载quartz.properties文件
OK Quartz集群的配置只有这几步,我们来启动项目。。。
我们启着启着….报错了!
| 17:00:59,718 ERROR ContextLoader:215 - Context initialization failed org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'startQuertz' defined in class path resource [config/spring/spring-time.xml]: Invocation of init method failed; nested exception is org.quartz.JobPersistenceException:Couldn't store job: Unable to serialize JobDataMap for insertion into database because the value of property 'methodInvoker' is not serializable: org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean [See nested exception: java.io.NotSerializableException: Unable to serialize JobDataMap for insertion into database because the value of property 'methodInvoker' is not serializable: org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean] |
我们主要来看红色部分,主要原因就是这个MethodInvokingJobDetailFactoryBean 类中的 methodInvoking 方法,是不支持序列化的,因此在把 quartz 的 task 序列化进入数据库时就会抛这个serializable的错误
4、解决serializable错误解决方案
网上查了一下,解决这个问题,目前主要有两种方案:
4.1.修改Spring的源码
博客地址:http://jira.springframework.org/browse/SPR-3797
作者重写了MethodInvokingJobDetailFactoryBean
4.2.通过AOP反射对Spring源码进行切面重构
博客地址:http://blog.csdn.net/lifetragedy/article/details/6212831
根据 QuartzJobBean 来重写一个自己的类,然后使用 SPRING 把这个重写的类(我们就名命它为: MyDetailQuartzJobBean )注入 appContext 中后,再使用 AOP 技术反射出原有的 quartzJobx( 就是开发人员原来已经做好的用于执行 QUARTZ 的 JOB 的执行类 ) 。
两种方式我都进行了测试,都可以解决问题,我们这里先通过第二种方式解决这个bug,没有修改任何Spring的源码
4.2.1、增加MyDetailQuartzJobBean.Java
1 package org.leopard.core.quartz;
2
3 import java.lang.reflect.Method;
4
5 import org.apache.commons.logging.Log;
6 import org.apache.commons.logging.LogFactory;
7 import org.quartz.JobExecutionContext;
8 import org.quartz.JobExecutionException;
9 import org.springframework.context.ApplicationContext;
10 import org.springframework.scheduling.quartz.QuartzJobBean;
11
12 /**
13 * 解决Spring和Quartz整合bug
14 *
15 */
16 public class MyDetailQuartzJobBean extends QuartzJobBean {
17 protected final Log logger = LogFactory.getLog(getClass());
18
19 private String targetObject;
20 private String targetMethod;
21 private ApplicationContext ctx;
22
23 protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
24 try {
25
26 logger.info("execute [" + targetObject + "] at once>>>>>>");
27 Object otargetObject = ctx.getBean(targetObject);
28 Method m = null;
29 try {
30 m = otargetObject.getClass().getMethod(targetMethod, new Class[] {});
31
32 m.invoke(otargetObject, new Object[] {});
33 } catch (SecurityException e) {
34 logger.error(e);
35 } catch (NoSuchMethodException e) {
36 logger.error(e);
37 }
38
39 } catch (Exception e) {
40 throw new JobExecutionException(e);
41 }
42
43 }
44
45 public void setApplicationContext(ApplicationContext applicationContext) {
46 this.ctx = applicationContext;
47 }
48
49 public void setTargetObject(String targetObject) {
50 this.targetObject = targetObject;
51 }
52
53 public void setTargetMethod(String targetMethod) {
54 this.targetMethod = targetMethod;
55 }
56
57 }
5、再次修改spring-time.xml文件解决serializable问题
修改后的spring-time.xml文件内容如下:
1 <?xmlversion="1.0"encoding="UTF-8"?> 2 <!DOCTYPEbeansPUBLIC"-//SPRING//DTD BEAN//EN" 3 "http://www.springframework.org/dtd/spring-beans.dtd"> 4 <beans> 5 6 <!-- 调度器lazy-init='false'那么容器启动就会执行调度程序 --> 7 <beanid="startQuertz"lazy-init="false"autowire="no"class="org.springframework.scheduling.quartz.SchedulerFactoryBean"> 8 <propertyname="dataSource"ref="dataSource"/> 9 <propertyname="configLocation"value="classpath:quartz.properties"/> 10 <propertyname="triggers"> 11 <list> 12 <refbean="doTime"/> 13 </list> 14 </property> 15 <!--这个是必须的,QuartzScheduler延时启动,应用启动完后 QuartzScheduler再启动--> 16 <propertyname="startupDelay"value="30"/> 17 <!--这个是可选,QuartzScheduler启动时更新己存在的Job,这样就不用每次修改targetObject后删除qrtz_job_details表对应记录了--> 18 <propertyname="overwriteExistingJobs"value="true"/> 19 <!-- 允许在Quartz上下文中使用Spring实例工厂 --> 20 <propertyname="applicationContextSchedulerContextKey"value="applicationContext"/> 21 </bean> 22 23 <!-- 触发器 --> 24 <beanid="doTime"class="org.springframework.scheduling.quartz.CronTriggerBean"> 25 <propertyname="jobDetail"ref="jobtask"></property> 26 <!-- cron表达式 --> 27 <propertyname="cronExpression"value="10,15,20,25,30,35,40,45,50,55 * * * * ?"></property> 28 </bean> 29 30 <!-- 任务 --> 31 <beanid="jobtask"class="org.springframework.scheduling.quartz.JobDetailBean"> 32 <propertyname="jobClass"> 33 <value>org.leopard.core.quartz.MyDetailQuartzJobBean</value> 34 </property> 35 <propertyname="jobDataAsMap"> 36 <map> 37 <entrykey="targetObject"value="synUsersJob"/> 38 <entrykey="targetMethod"value="execute"/> 39 </map> 40 </property> 41 </bean> 42 43 <!-- 要调用的工作类 --> 44 <beanid="synUsersJob"class="org.leopard.core.quartz.job.SynUsersJob"></bean> 45 46 </beans>
主要看红色加粗部分...
测试
Ok 配置完成,我们把oa_ssh部署到两台tomcat上面,分别启动。
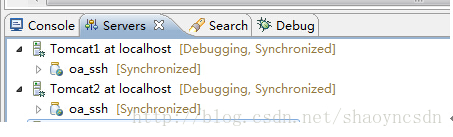
可以看到我们先启动的tomcat控制台打印出日志
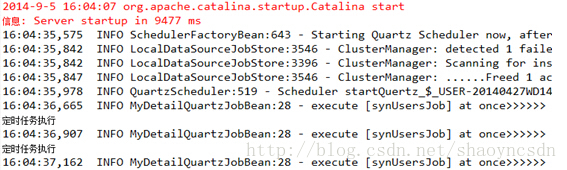
另外一台没有打印日志
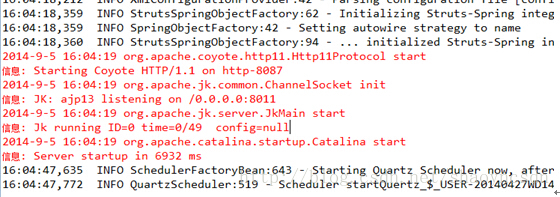
这时我们把执行定时任务的那台tomcat停止,可以看到等了一会之后,我们的另外一台tomcat会把之前tomcat执行的定时任务接管过来继续执行,我们的集群是成功的。