前言
前面的博客中,我们介绍了windows平台下caffe的安装,并使用mnist进行了测试。为了巩固和熟练caffe的使用,我们本节使用数据库CIFAR-10再次练习caffe的使用。
1、数据库CIFAR-10的下载与介绍
进入caffe目录下的data/cifar10目录下,有个get_cifar10.sh文件是用来下载和解压数据的,只不过是Linux的shell脚本。我们打开这个文件,将下载链接http://www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz复制到浏览器地址栏手动下载数据集。
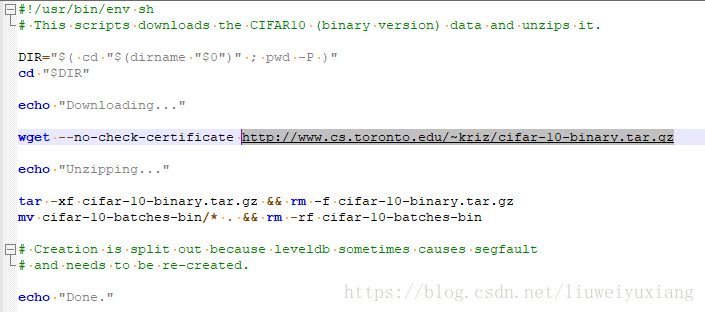
2.将数据集解压到相应目录
CIFAR-10数据库: 60000张32*32大小的彩色图像共计10类(airplane、automobile、 bird、cat 、deer、dog、frog、 horse、ship、truck)。每一类6000张,其中50000张用于训练,10000张用于测试。
将下载后的数据集解压到data/cifar10目录下。解压得到data_batch_1.bin、data_batch_2.bin、data_batch_3.bin、data_batch_4.bin,data_batch_5.bin,test_batch_.bin。data_batch_1.bin、data_batch_2.bin、data_batch_3.bin、data_batch_4.bin和data_batch_5.bin包含了该数据库中的50000张共10类(每类5000张)彩色图像,是用于训练的,而test_batch_.bin中包含了10000张共10类(每类1000张)是用于测试的。
3.转换数据集为lmdb格式
caffe为什么采用LEVELDB格式或LMDB格式,而不是直接读取原始数据?原因有二:一是数据类型多种多样,转换为统一格式可以简化数据读取层的实现;二是使用LEVELDB格式或LMDB格式可以提高磁盘IO利用率。
若是在linux下,进入…/caffe-master/examples/cidar10/路径下,则直接执行./create_cifar10.sh即可完成数据格式转换。
在windows环境下编译好caffe后在Build\x64\Release下会生成convert_cifar_data.exe,可以将cifar10转换为lmdb数据库。
打开cmd进入caffe根目录,输入如下dos命令:
Build\x64\Release\convert_cifar_data.exe data\cifar10\ examples\cifar10 lmdb命令执行完后可以在…/caffe/examples/cifar10/路径下面看到生成的两个文件夹cifar10_test_lmdb和cifar10_train_lmdb,它们分别是测试数据库和训练数据库对应的转换后的数据库。
接着,将db格式的训练图像进行求平均值,输入如下dos命令:
Build\x64\Release\compute_image_mean.exe -backend=lmdb examples/cifar10/cifar10_train_lmdb examples/cifar10/mean.binaryproto命令执行完后可以在…/caffe/examples/cifar10/路径下面看到生成的mean.binaryproto。
4.模型配置与说明
我们可以看到,在…/caffe/examples/cifar10/路径下有一堆*.prototxt,它们均是用来配置模型的。
由于我的电脑没有GPU,只能采用CPU进行训练,所以将cifar10_quick_solver.prototxt和cifar10_quick_solver_lr1.prototxt中的solver_mode:GPU均改为solver_mode:CPU。这两个参数配置文件是用来协调模型的优化的,例如学习因子(learning rate)。另外为了节省时间,我将cifar10_quick_solver.prototxt中的max_iter: 4000改成了 max_iter: 1000,cifar10_quick_solver_lr1.prototxt 中的max_iter: 5000改成了max_iter: 2000。
5.训练
训练或者测试时都要采用Release模式下的caffe.exe,进入…/caffe/Build/x64/Release/路径下,采用dos命令行,也就是执行cmd,执行下列命令:
Build\x64\Release\caffe train --solver=examples\cifar10\cifar10_quick_solver.prototxt
上述命令执行完毕后会生成cifar10_quick_iter_1000.caffemodel.h5以及cifar10_quick_iter_1000.solverstate.h5两个文件,其中cifar10_quick_iter_1000.solverstate.h5将在进一步的训练中使用到,而cifar10_quick_iter_1000.caffemodel.h5模型权值文件可用于数据集的测试(此处可不用,因为下面还有更深层的训练,会生成更深层的模型权值文件cifar10_quick_iter_2000.caffemodel.h5)。
接下来执行如下命令:
Build\x64\Release\caffe train --solver=examples\cifar10\cifar10_quick_solver_lr1.prototxt --snapshot=examples\cifar10\cifar10_quick_iter_1000.solverstate.h5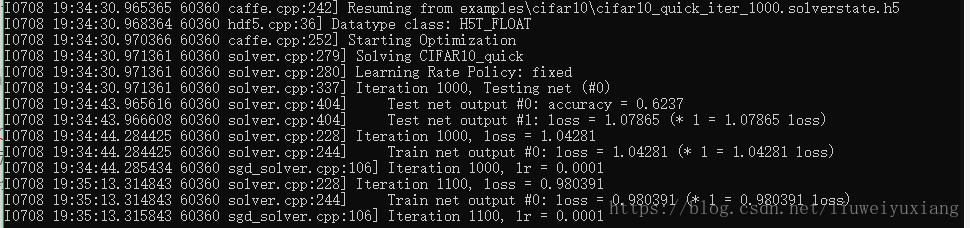
本次训练是在上次训练1000次的基础上训练的。cifar10_quick_iter_1000.solverstate.h5保存了上次训练的状态。

上述命令执行完毕后会生成cifar10_quick_iter_2000.caffemodel.h5以及cifar10_quick_iter_2000.solverstate.h5两个文件,在此例子中,接下来就是用cifar10_quick_iter_2000.caffemodel.h5模型权值文件进行预测的。
6.用训练好的模型进行预测
其实,预测就是用训练好的模型进行预测,对于此例子来说,就是使用cifar10_quick_iter_5000.caffemodel.h5模型权值文件进行预测的。
同理,对于windows平台,进入caffe根目录,采用dos命令行,也就是执行cmd,执行下列命令:
Build\x64\Release\caffe test -model examples\cifar10\cifar10_quick_train_test.prototxt -weights examples\cifar10\cifar10_quick_iter_1000.caffemodel.h5 -iterations 100其中:
test :表示只做预测(前向传播计算),不进行参数更新(后向传播计算)
-model examples/cifar10/cifar10_quick_train_test.prototxt:指定模型描述文本文件
-weights examples/cifar10/cifar10_quick_iter_2000.caffemodel.h5 :指定模型权值文件,也就是预先训练出来的模型或者说权值文件
-iterations 100:指定迭代的次数,iterations*batch_size也就是参与测试的样本数目。

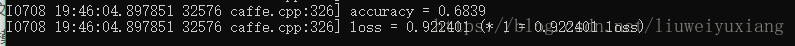
根据测试结果,可以看出,采用cifar10_quick_iter_1000.caffemodel.h5模型权值文件进行预测时,准确率为0.6237,采用cifar10_quick_iter_2000.caffemodel.h5模型权值文件进行预测时,准确率为0.6839,说明训练样本的多少与训练出来的模型还是有很大关系,这一点非常好理解,学得越多懂得也就越多,碰到新问题解决问题的能力就越强,与人一样。