绪论
强化学习(增强学习)是一种人工智能在训练中得到策略的训练过程。强化学习是希望让机器人(不管是人形机器人还是非人形机器人,总之是带有策略指导输出类型的机器人)有学习功能的一种学习方式。
11.1 模型核心
几个概念:
Agent 智能体(主体):可以粗略地理解成机器人,就是要训练他的行为策略。
Environment 环境:智能体所处的当时的情形
Action 动作:机器人做出的反应或输出。
Reward 奖励:正值是奖励,负值是惩罚。
State 状态:智能体根据状态做出决策,以获得最大的奖励。
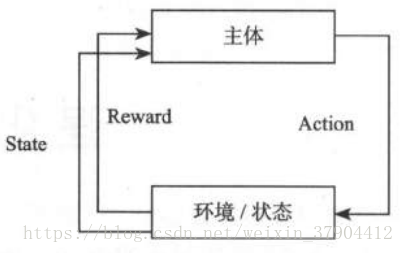
智能体存在于环境中,并会在环境中做出一些动作。这些动作会使得智能体获得一些奖励。这些奖励有可能正,也有可能负。强化学习的目标是学习一个策略,使得智能体可以在合适的时候做出合适的动作,以获得最大的奖励。智能体一般以当前的状态作为决策依据,做出决策后,智能体的行为又会引起状态的改变。人需要做的工作只有两个:
1.把奖励和损失定义好,让环境中产生的奖励和损失能够顺利有效地量化反馈给智能体。
2.让智能体以较低的成本快速地不断尝试,以总结出在不同的状态情形下奖励较大的方式。
11.2 马尔可夫决策过程(MDP)
用类似隐马尔科夫链的方式来做训练,统计一下状态转换的概率和得到Reward的数学期望值,然后寻找一条获取最大Reward的路径。
这个决策的过程是个只和当前状态有关,和以前状态无关的决策过程 。
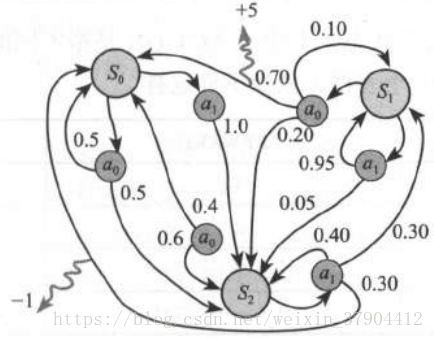
从思路上来说基本上只看一种情形就可以了,在一个状态下(就是图中的
、
、
),会有多大的概率选择某一种动作(就是图中的
或
),以及每一次状态的迁移会获得多大一个奖励(就是上图中曲里拐弯的箭头上面带着
和
的那种) 。整个这个过程是从大量的样本学习中得到的,用表达式来表示这个模型通常写作:
这样一个四元组 。
表示状态 State,
表示动作 Action,
表示前后两种状态
和
之间的转化概率,
表示前后两种状态
和
之间的转化所获得的奖励 Reward。
对于 MDP 来说,把这 4 个要素描述清楚了,就算是把整个模型描述清楚了 。
上面所说的这一切都是基于一系列观测的统计结果,例如你可以观测在象棋博弈中的众多的棋局来得到这样一个统计结果,其中的 S 就是描述棋局盘面的向量(一个 9 × 9 的向量,每个维度表示一个交叉点,每个维度上有一个棋子的描述信息), A 是描述某个棋子动作的向量(例如车六平二 ,炮三进一), R 是描述这次状态转化的得失(可以简单用棋子的得失来描述,例如吃掉对方一个车,得 10 分,被对方吃掉一个卒得-2 分) 。 最后基于大量的观测统计出来的结果就是一个马尔可夫决策过程的模型 。如果把这个过程描述成一个类似查表过程的方式的话,可以把刚刚这个模型转化一下得到这样一个表格:

每一行代表一个状态,每一列代表一个行为,中间交叉的方格中填写的内容请注意还是一个表格,就像下面这样 。

这个表格就嵌套这么两层 。 总结的时候就用统计的方法算出具体的数值填入表格;用的时候就用查表的方式,在第一个表格中用当前的 STATE 找到对应的 STATE行,在第二个表格中找到概率大而且奖励值高的那个状态,根据这个状态作出决策 。 如果不是在特殊场景中进行具体讨论,而是单纯从刚刚第一个表上来看的话,这个表一定是描述在某个 STATE 下做了某个 ACTION之后获得的一个统计结果 。 这个 ACTION 到底靠不靠谱就看第二个表中统计出来的值是不是有着足够好的REWARD。 例如对于某一个
状态,采取了某一个
,从第一个表中找到对应的格子
,然后找到第二个表中,光看这三行可以得到一个 REWARD 的期望值,用 0.35 × 3+0.12 × 2 + 0.05 × 7……来得到一个期望值,算出来应该是 1.64 。
不过聪明的读者朋友一定是可以推断出来的,既然是一个概率问题,那么 Possibility的这一列相加之和一定是 1 或 100%一一是的,这个结论是正确的 。 那么最后在第一个表格里去做决策的时候就好办了,就是去比较在当前的 STATE 下 用哪个 ACTION 会得到更为“靠谱”的结果一一也就是哪个 ACTION 下面的那个表格(第二个表格)里出现比较大的REWARD 值。 这个思路应该还是比较好获得的,而且定性去看的话肯定是大概率得到大REWARD 值的那个 ACTION 会更有吸引力 一些 。 这就是整个隐马尔可夫决策过程的叙述了,也并不复杂 。 从这个过程中也可以看出来,如果第 2 个表格能够退化成为一个只有一行的数据那是最好,也就是说一个 STATE 经过某一个 ACTION 只能变化成为某一个 STATE ,而不是以一定的概率转化成众多 STATE 中的一个,那么情况就会简化得多 。
除了用在棋局的例子上之外,其他的各种决策只要能够把 STATE 向量化,把ACTION 向量化,把 REWARD 数值化,就都可以使用马尔可夫决策过程来学习,并得到一
个从统计角度来看最为有吸引力的决策表。 最终让机器人用查表的办法找到当前状态下做什么动作最靠谱来决定下一步的举动,这个思路是不是顺其自然呢?
11.2.1 用游戏开刀
为了让这个训练过程有点具象性,我们还是要找一个假想敌来做说明 。
游戏可能是一种再合适不过的场景了,不管是什么类型的游戏理论上都是可以的 。 由于整个过程中遍布着试错的基因,所以如果试错给我们带来的成本太高那将是一场非常不划算的实验,但是游戏中基本不存在这个问题,只要不是付费的 。 此外,游戏中带有比较明显的对抗、策略、博弈的特点,适合作为强化学习的环境,并在最终得出一个相对可行的策略。
我们要训练的机器人,不论你怎么设计它,它只是一个地地道道的白痴 。 它在整个过程中根本不知道自己在玩什么,更别说玩游戏玩得开心不开心了,它能理解的只是在一系列和一个环境互动的过程中输入向量的变化,以及自己得到的 Reward 变量值变大变小而已 。 它自己只能通过一系列的调整去归纳什么情况下做什么动作会得到比较大的 Reward值,仅此而已 。
11.2.2 准备工作
准备工具:沙罗曼蛇游戏
准备工具:State生成器
作为要训练的主体来说, State 是一个描述环境的向量,既然是向量就需要做出某种转化来得到 。 在游戏场景中,我们当然是希望以最原始的画面屏幕作为 State 的描述方式 。
准备工具:模拟手柄
你可能还需要一个模拟的手柄来记录输入的 Action。 这个手柄可以是购买的一个 USB的手柄,也可以是键盘模拟的 。 但不论是其中的哪一种,都要能够保证通过一个适配器工具把这种按键的记录捕捉到,并传递给主体。 而且机器人自己玩耍的过程中,需要极其频繁地与环境交互,这时不得不使用模拟手柄了,例如用 Python 对模拟器发出一个按键动作 。
准备工具:评价器
评价器的功能很单纯,就是根据当时的 State 所作出的一种评分函数 。 将当时捕捉到的State 通过一定的特征提取,无论是画面,还是声音,或者是从游戏某个接口获取到的具体的一个分数或者表示玩家血量的 HP 值等 。 总之最后当环境当时的状态传输到评价器的时候,评价器能够根据这个状态给出一个比较合适的评价值,或正或负,来评价当前这个状态对玩家的不利或者有利的量化程度 。
11.2.3 训练过程
当这一切都完成后就可以考虑开始训练了,一旦开始训练,整个系统的各个部分就开始这样运作起来 。
在主体中有刚刚我们设计的那个表。

在主体中有刚刚我们设计的那个表。
它是用来表示这样一个含义
,也就是一个评价表(注:
的值是在
状态执行了
行为后的期望奖励数值,只要得到了正确的Q函数,就可以在每个状态做出合适的决策)。最终将在一个状态 State 下通过查表的办法找到当前最有利的回应动作 Action 。
然后当游戏开始后,我们就可以开始填充这个表了。
以每秒钟捕捉 5 次屏幕并对应做出 5 次反应, 一次 0.2 秒的周期去做反应 。 那么在一个时刻主体会收到一个 State 和一个 Action (即便没输入也应该算一种 Action ,或者成为空操作 Action ),同时应该还会得到一个 Reward ,或者从时间连贯性上来看,应该是 3 个序列 。
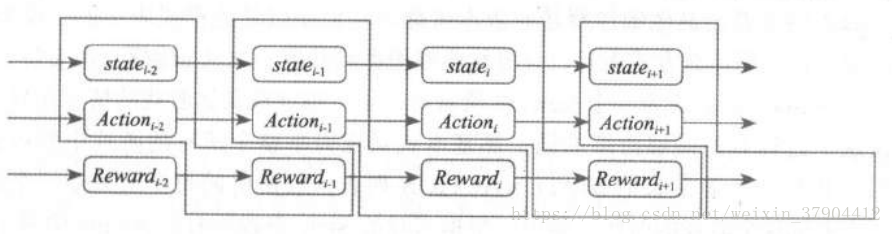
注意一点,当时输入的
可不是“一起”的 。 这个
,其实是
及之前的一系列相互作用产生的回报值,所以记录的时候其对应关系应该是如上图所示的逻辑 。
这里的 Action 理论上讲应该都是由机器人自己去玩比较好 。 如果是人玩一些游戏,把人玩的过程加以记录,让机器来学习这个过程也未尝不可,当然玩得好的一些人会帮助机器人在学习中快速收敛,但是这多少有点录像或者模仿的意味,自我尝试和修正的逻辑比较少 。 而如果由机器人从头开始玩的话,一开始就面临“冷启动”的问题,也就是一开始大脑一片空白的机器人根本不知道应该怎么做,那就……没错,你说对了,只能瞎试。 可以用这种模型来进行尝试:
一个 Action 的输出将有一定概率是由随机函数生成的,还有一定的概率是由已经学习到的
函数生成的,也就是那个矩阵查找得出的 。 这个概率可以由我们人来控制,总体原则就是最开始
函数里面还什么都没有的时候让随机函数多产生一些比例的 Action ,而当
逐渐有一些积累以后就可以考虑由
来生成较大比例的 Action一一这算是经验与教训的结晶 。 如果这个函数已经总结出很多State 情况下较大的 Reward 值,那么就说明这个算法已经使机器人足够进化,多采用这些已经进化的内容会让它生存得更长久 。
最后是这个 Reward 怎么办的问题。 Reward 就是一种奖励或者回报,在沙罗曼蛇这种游戏里面,什么是奖励或回报呢?或者说什么会对机器人更有利呢?简单说,只有一个因素一一生存,能活到最后就算通关胜利 。 为了达成这样一个因素,需要哪些因素支持呢?①不被击中,②歼灭敌人,③火力增强 。 这种游戏好就好在逻辑相对比较简单,要么打怪,要么被怪打 。 所以呢,评价器的功能只要能根据游戏界面上的一些东西判断出当前的状态,并反馈一个分数,那就很好了 。 有这样的东西吗?有的 。
在屏幕的左下角已经有一个类似仪表盘一样的反馈示数了,左下的 02 表示当前玩家的生命数,死亡就减 1 ,加命就加 1 ;右下的这个条表示火力;上面的数字是得分,基本可以反映歼灭敌人的收益 。 其他的沙罗曼蛇版本可能这些值是以其他形式表示的,没关系,不管什么游戏,不管用什么方式表示,只要你能够用类似截屏 、 OCR 识别 、 声音特征识别等方式把当前的 State 映射成为一个 Reward 值就可以了,难度视具体游戏的情况而异 。
假设这个过程真的能够持续的话,那基本就是在穷举整个所有的游戏中的可能性了 。最后我们会得到一个非常长的 STATE x ACTION 列表表格里的每个值就是一个回报值。等机器人再来玩这个游戏的时候,就可以根据当时的 State 查找所有的 Action 中哪个获利最高,然后直接采用就可以了 。 嗯,不过看上去好像有点问题……
11.2.4 问题
1. 空间存储问题
State 就是游戏输出画面的完整信息,例如笔者使用的 FC 模拟器默认分辨率就是256×225 ,也就是 57600 个像素,用 RGB 表示则每个像素需要 3Byte 空间,也就是 172800 字节,也就是 168.75KB 来表示一个 State 。
Action 对于 FC 模拟器来说也是比较有限的,大致上就是“上”、“下”、“左”、“右”、“左上”、“左下”、“右上” 、 “右下” 、“空方向”这样 9 个方向状态,以及“ A ” 、“ B ”、“ AB ” 、“空发射” 4 个状态 。 所以所有的可能性相加就是 36 个状态,也就是它们的乘积 。 换句话说,上面 ACTION一共也就是 36 列 。 千万别忘了,方向键和 AB 键是可以一起按下去的 。
左边的 STATE 大概有多少行呢,以每秒钟捕捉 5 次屏幕并对应做出 5 次反应的情况下, 一次 0.2 秒的周期计算,整个“沙罗曼蛇”通关需要 27 分钟, 27 × 60 × 5=8100 ,从头到尾演练一遍都需要 8100 个 STATE ,即 1 366 875KB ,大约1.3GB 的样子,这仅仅是前面的状态描述所需要占有的空间大小 。 还要算一下 36 列乘以一个 1 字节的大小,再乘以 8100个State ,大约 284.7KB 。 你可能觉得这个数字并不大,反正对于一个 2TB 大小的主流硬盘来说算是九牛一毛。可是你别忘了一点哦,这些 STATE 都是以像素为单位做记录的,也就是说两个状态中哪怕就是一个像素不同都不能算作同一个 STATE。这么算起来可就太可怕了,在不同次玩沙罗曼蛇的时候,同一次序的帧( 0.2 秒)都远远不止一种可能性,这个数量就很难估计了,恐怕几万种都不止 。 哪怕就是 1 万种,都会使得 STATE 的存储空间陡增至 12.7TB ,这连保存都是问题,就别提什么训练了 。
2.查找问题
按照刚刚的假设,这么大的 STATE 的描述向量( 172800 字节一个)当然可以考虑先做一个有损压缩,只要不是用哈希的方法,做了有损压缩对于查找就是有利的 。
哈希肯定是万万不可取的,虽然看上去用 MD5 和 SHA-1 这类算法可以把这么长的一个字符串压缩到只有几十个字节 。 但是一旦用了这样的方法后,原本非常接近的两种 State就会出现两个完全不一样的哈希值 。

看两个数字“ 1234567890”和“ 1234567891 ”,虽然我们知道这两个数在数值上的差距非常小,但取过 MD5 后不论是 16 字节的还是 32 字节的,都完全看不出两者有什么关系 。这样在 State 的泛化性会非常不好,本来非常相近的 State 应该可以采取类似的 Action 就可以了,但是现在却是以两个完全不同的 State 出现,完全没办法互相“借鉴”,这本身就带来了相当多的“ State 冗余” 。
当然这么大的数据集进行查找也同样需要使用诸如索引一类的东西来快速找到 State 所在的行,可是普通的针对字符串和数字的 B-Tree 索引、 Hash 索引以及针对枚举的 Bitmap索引都不能用上 。顺序查找理论上可行,但是时间上实际上是不允许的 。所以还是要开发一种基于向量相似度的索引结构才行,如果开发不出来也是个问题。
3.短视问题
这种问题在这种方式的一开始几乎就奠定了不可改变的基因 。一个 State 当时所作出的Action 很可能就是一种应激反应式的 Action ,虽然在这一 瞬间感觉是不错,但是时间稍微一长就会发现这一步 Action 可能会导致下面更不利的局面 。 而这个问题在刚才我们提供的这种模型中显然并没有解决,所以这种模型只适合那种盘面变化比较简单,前后逻辑关联相对较弱的情况 。
那是不是刚才我们模型整体都有问题呢?
其实也不是,这个模型是有一些问题,但是模型考虑的核心元素没有错,问题在于如何总结和归纳一个空间占用小、查找迅速、眼光长远的算法呢?我们一个一个来解决,先解决其中最为关键性的问题一一短视问题,因为除了这个问题以外,其他几乎都是工程性问题而非探索性数据研究问题。 看看一种叫做 Q-Learning 算法的东西会为我们带来什么 。
11.2.5 Q-Learning算法
Q-Learning算法的思路很简单,概括起来也很简洁,就看这样一个表达式即可 。
听听白话解释一下思路就好了 。
首先我们还是像原来一样,得到了在时间序列上的
三个序列,等接收完毕后把它们按时间顺序排好。 然后从头到尾一个一个按照这个逻辑去处理。 在一个时刻
,看看这一刻输入的
和
,如果此时
和
没有对应的Reward 值(也就是说第一次出现)那就直接把这个
和
填入表中 。
如果下面你按部就班地按照统计的方法去做,那么就是前面的马尔科夫决策过程 。 不过下面步骤的不同是关键,请注意 。
如果当你发现在
的情形下,
所有的可能性中有一个比较大的值,即在
的情况下找到那个最大的 Reward 值并乘以一个在 0 和 1 之间的系数
,用这个值加上
和
这一步本应得到的 Reward 值
,同时减去前一步的
值来更新
。这个逻辑其实就是为了避免短视现象的发生 。
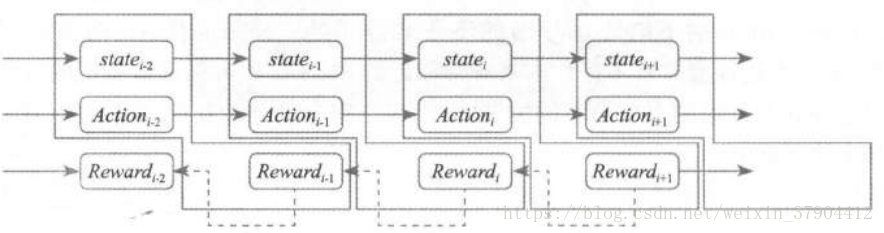
当迭代计算的时候,后面一个
下,一个有着更多回报 Reward 的
会把它的回报值 Reward 向前传,传给前一个
,并作为由这个
下通过该
转移到
的这个行为的回报值的一部分 。
请注意,由于你是在大量的游戏局中获得的 State 和 Action 的序列,并把它们做以记录,所以不太可能形成一个像上图那样的独立的链条。 而你发现,哪怕从最开始在一个相同 State 的情况下,都会由于 Action 转化到不同的 State 上去,而每个新的 State 具有同样的特性一一它也能由于不同的 Action 转化到不同的 State 上去 。
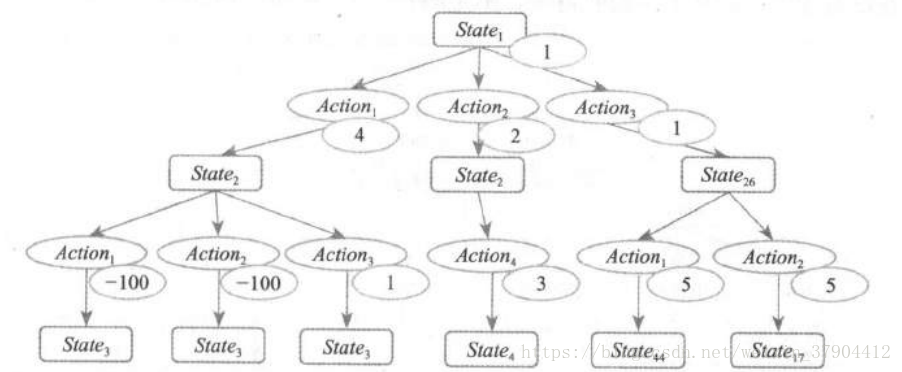
所以整个模型就好像是这样一个棵树, 一棵极宽极深的树,学习象棋和围棋的模型在这点上尤为明显。一个 State 就是这样一个树上的节点,当做了一个 Action 后,状态就转移了,就等于从上向下开始进入这棵树,椭圆圈中的数字代表 Reward 。 当我得到这样一棵树的时候,我当然是期望看到在这个 Action 下面的那些状态中,哪个回报最大我就选择哪个Action一一这个判断逻辑非常的自然 。 但是由于一个转移样本而做出的 Reward 值其实描述非常片面,简单说就是,你在玩沙罗曼蛇的过程中这一步为了吃个枪而导致下一步撞死的话,这个枪的意义就不存在了一一例如左边这两个分支就是类似的情形,最后
代表一个严重的惩戒 。 所以下一步产生的奖励值或者惩罚值应该顺着这棵树向上回溯往根部靠拢,因为我们要让整个一条“ Action 链”看上去更靠谱的话,那就是寻找靠近根部的点更靠谱的情况,而为了修正这个评价才引入的这样一个机制 。 不然用类似贪心法的方式去做的话,会走
这样一个路径,而这样似乎不是收益最好的途径,我们用肉眼看都知道最右侧的两条路径比它要强 。 注意,这里的
或
这类不见得是第 3 个或者第 26 个出现的状态,这只是代表一个 State 的标号值 。
展开后可以写作:
比较明显地可以看 出来,
这个系数代表了对远期收益的重视程度,如果取得小一些,相当于比较注重当前的收益值。 取0那么就会仅仅看到从一个转移中获得的 Reward,而完全忽视远期传播过来的 Reward;取1则完全没有重视当前已经获得的收益效果,而完全采纳了后面
的内容 。
表示对远期 Reward 的重视程度,理论上说
大一些会使得复杂的局势演化中远期 Reward 向树根部集中的趋势会明显 。 后面的
的含义就是找到这个 State 下可能取得的最大的 Reward 值,比如
下面虽然两个状态都得到了非常严重的惩戒(
),但是一息尚存啊一一右边还有个
,也就是说,转化到
这个状态产生的 Reward 其实是可以采纳
带来的1 。 收益看最大的那一项,而不是最小的,因为在众多的选择中还有机会不选那个最小的,能有更好的收益没有理由去选那个小的收益项,不是吗?
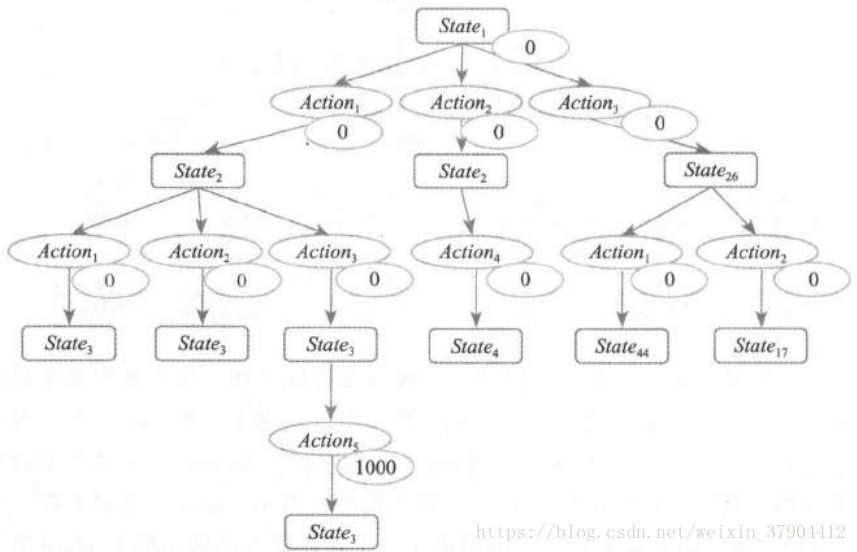
注意这里有个现象,如果在这个过程中,即便我无法获得实时性的 Reward一一也就是如果没办法做到每次做一个 Action 就获得一个 Reward ,在这种情况下,在最终结束游戏的时候,只要把一个较大的正值 Reward 放在最后一个状态作为 Reward 时,理论上讲整个
树也能够通过迭代一步一步把这个 Action 链学习出来 。 反正就是通过一轮一轮的学习把这个 Reward 值向上传递就可以了,那当然能够找到这条最合适的路径 。 例如上图也能够通过Q-Leaming 算法找到
这样一条路径的,回溯会把 Reward 值向上传递,使得在前面碰到的 State 在 Q-Learning 算法的学习下会让那些最终只能引导到获得较大回报路径的 State 看上去更为“靠谱” 一些,而最终引导获得较大惩戒的 State 看上去更为“不靠谱”一些,通过这样的比较可以让机器人按照更靠近树的根部的一些 State 就已经能够看出来哪条路径在远期更容易获得较大的Reward 。 这个 Reward 在这里我示意性地给了一个1000 ,但是不是说必须要给一个这么悬殊的值才能训练出来,其他的中间过程已经都给了0了,其实这个地方给一个1都可以训练得到结果,因为哪怕 Reward 就差零点几也是可以在
这个部分比出大小并进行传递的 。
回看整个训练过程,你会发现套路也非常清晰。在某一步获得的Reward 比较大,那么就推断它的前一步的那个 State 和 Action 比较靠谱,从而提高对前一步 State 的 Reward 评价 。 在大量的样本训练下,那些经常反复出现的有着高的 Reward 的状态会被大量验证和强化,从而学出一些靠谱的路径来 。 这些路径由一系列的 State 和 Action 构成,形成一套复杂
的决策程序 。
整个这个部分讨论的内容都属于动态规划( dynamic programming)的范畴,这种树也有个学名,叫做蒙特卡洛树( monte carlo tree ) 。 大家感兴趣的话可以去找一下相关的教科书,推导比这个要严谨,也更为复杂一些。