
强化学习来自于心理学里的行为主义理论,是在环境给予的奖励或惩罚信号的反馈下,逐步形成能获得最大利益的行为策略。与监督学习相比,强化学习不需要事先准备样本集,而是通过不断尝试,发现不同动作产生的反馈,来指导策略的学习。与无监督学习相比,强化学习不只是探索事物的特征,而是通过与环境交互建立输入与输出之间的映射关系,得到最优策略。
强化学习的特点:
- 试错学习:智能体与环境交互,每一步通过试错的方式学习最佳策略,没有任何的指导。
- 延迟反馈:智能体的试错获得环境的反馈,可能需要等到过程结束才会得到一个反馈。‘
- 过程性学习:强化学习的训练过程是一个随着时间变化的过程。
- 环节之间的行为相关性:当前的行为影响后续的状态和行为。
- 探索和利用的综合:强化学习开始时,智能体更偏向于探索,行为具有一定的随机性,尝试多种可能性,训练很多轮后再降低探索的比例。
强化学习的基本概念
- 智能体(agent)
不可避免的要与环境进行交互,必须了解环境将如何响应所采取的操作,这是一种多次试验的试错学习方法。
在强化学习的概念中,状态表示智能体的当前状态。智能体执行动作以探索环境。
- 策略(policy)
定义了智能体在给定状态下的行为准则。
策略函数(可以是连续的也可以是离散的)是从智能体的状态到其在该状态下要采取的行为映射。通常表示为\(π(a_t|s_t)\),表示在给定状态\(s_t\)中采取动作\(a_t\)的条件概率分布。
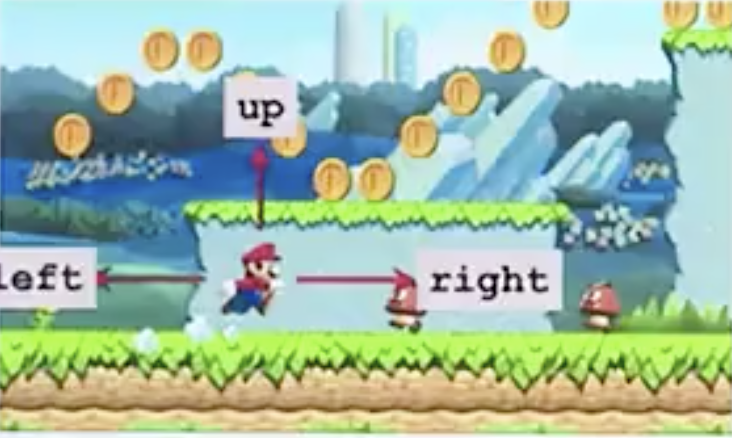
比如在上图中,马里奥的任务为拿到更多的金币,并且躲避障碍。策略函数π:(s,t)的结果是一个概率,处于[0,1]之间。
\(π(a|s)=p(A=a|S=s)\)
马里奥有三个方向可以行动,那么为了达到更好效果,他向三个方向行动的概率为
- π(left | s)=0.2
- π(right | s)=0.1
- π(up | s)=0.7
{{o.name}}
{{m.name}}