论文:PixelLink: Detecting Scene Text via Instance Segmentation
Github:https://github.com/ZJULearning/pixel_link
整体框架:
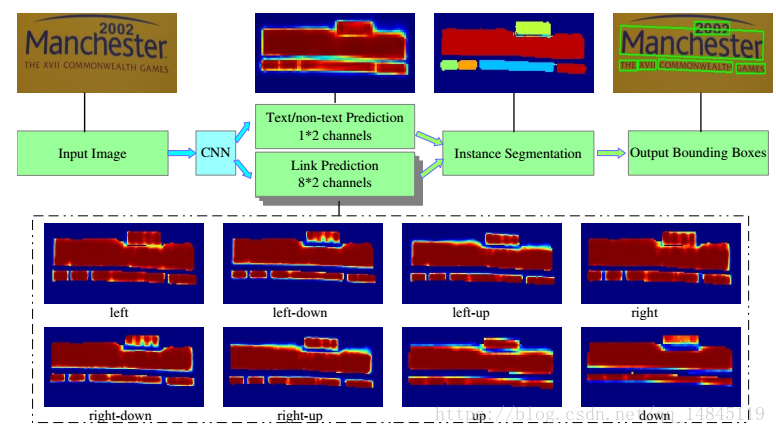
PixelLink主要基于CNN网络,分别做文本,非文本分类预测和像素的8个方向是否连接预测这2个任务。然后基于Opencv的minAreaRect这种基于连通域的操作,可以获得不同大小的文本连通域。然后通过噪声滤除操作。最后通过并查集合并出最终的文本框。并查集可以参考本人这篇,https://blog.csdn.net/qq_14845119/article/details/52087475
网络结构:
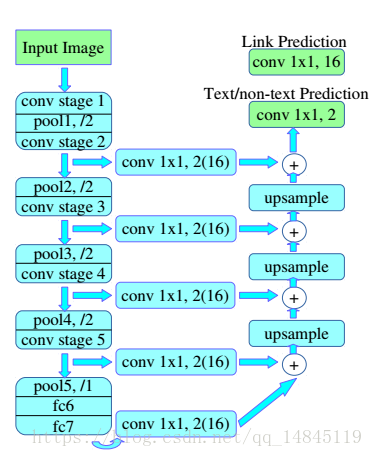
网络结构采用VGG16基础框架。文章提出了1/2下采样,1/4下采样两种结构。分别表示为,1/2下采样结构最多unsample到conv2_2,相当于只有一个pooling操作,输出featuremap为原图的1/2。
1/4下采样结构最多unsample到conv3_3,相当于2个pooling操作,输出featuremap为原图的1/4。
1/2下采样结构(PixelLink+VGG16 2s ):conv2_2, conv3_3, conv4_3, conv5_3, fc_7
1/4下采样结构(PixelLink+VGG16 4s ):conv3_3, conv4_3, conv5_3, fc_7
从结构整体来看还是基于FPN的思想。和EAST中的Resnet50基础结构,CTPN中的VGG16结构思想都很像。
网络主要包含2个任务,文本/非文本2分类预测,需要2个featuremap,一个像素周围的8个像素的是否连接预测,需要8*2(文本/非文本)个featuremap。所以最终输出18个featuremap。
连接像素提取文本框操作:
首先对网络预测的pixel分类和link分类分别使用2个不同的阈值进行阈值化操作。然后基于link分类的预测,可以将像素连接为Connected Components (CC) ,然后使用opencv的连通域方法minAreaRect 可以获得最终的连通域,此时每个连通域都有自己的最小外接矩。最后使用disjoint-set 形成最终的文本框。
后处理去除噪声操作:
这里主要由于使用了基于连通域的方法进行文本像素汇聚,而该方法对噪声比较敏感,最终就会产生一些比较小的false positive。论文基于长度,宽度,面积,长宽比等信息对false positive连通域进行了去除。主要方法就是,短边小于10个像素,或者面积小于300就会当做错误的连通域进行去除。
损失函数:
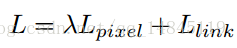
整体损失函数分为pixel分类的损失和link分类的损失。由于pixel分类任务更重要,这里λ =2.0。
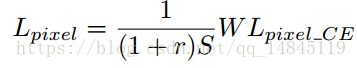
Pixel分类的损失如上面式子所示,L表示softmax_cross_entrop,W表示预测的pixel分类的权值矩阵,r表示负正样本比例,论文中r=3,S表示每个文本实例的面积。最终,当文本实例的面积比较大,占的loss损失就会被相对拉小,文本实例的面积比较小,占的loss损失就会被相对拉大。这样做的好处就是使得小的文本实例不会被大的文本实例的loss掩盖掉,也可以有loss回传。
同时pixel分类任务还使用了OHEM策略,每次回传S(正样本实例像素和)+r*S(负样本像素和)的loss,更加有利于分类任务的学习。这点改进比EAST中所有像素的loss都回传可以得到更好的分类结果,而不是像EAST那样,一个实例中间的像素分类的好,边缘的像素分类的差的情况。
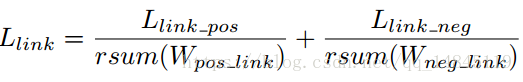
Link分类的损失如上图所示。其中r表示负正样本比例,
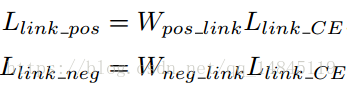
L表示正负实例的分类损失。具体的表示为实例的pixel分类权值矩阵和
link的分类softmax_cross_entrop的乘积,W表示正负实例的pixel分类权值矩阵。
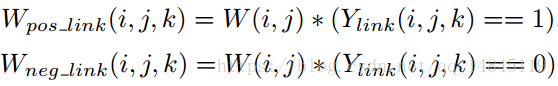
具体的W的计算表示为pixel分类权值矩阵和link分类矩阵基于每个通道的element_wise乘积。
模型分析:
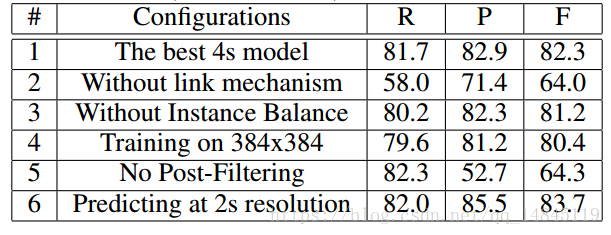
上图R表示recall,P表示precision,F表示F1 score。
(1)link的思想是非常重要的,可以极大的提升准确性。直接预测score map可能会不准确,但是预测link会比较准确,可以根据link来提升score map。
(2)实例平衡OHEM有助于学习到更好的模型
(3)将训练图片从512*512减少到384*384会使得模型精度降低。
(4)不做false postive的过滤,会使得准确性大大降低,当然召回率会有提升,也符合PR曲线的性质
(5)2S的分辨率比4S的分辨率可以得到更好的结果。上采样到更低一层可以获得更大的感受野,可以利用更多的卷积特征。
总结:
(1)PixelLink和EAST,CTPN的整体结构都大同小异,本质都是一个RPN网络。网络的区别就是EAST去掉了anchor,CTPN加入了lstm。
本质原因就在于对于传统的VOC 21分类任务,各种类别的aspect ratio不会很大,因此anchor是可以覆盖到的。而文本检测的特殊之处就在于没有一个anchor可以覆盖到这么长的文本ground truth。虽然,EAST中对每个像素都进行回归,但是每个像素回归的结果都不会是准确的,因此EAST使用了locality_aware_nms进行了合并。而CTPN的思想在于,CTPN知道anchor不会有ground truth那么大的感受野,因此直接回归宽度固定为16,不同高度的框,然后再基于NMS将其合并。
其实,文本检测最主要的还是pixel分类任务,而pixelLink将这个做到了极致。PixelLink引入了link分类任务是一个很好的创新。
(2)一般来说分类任务是比回归任务更容易学,可以得到更好结果的一个任务。
EAST和CTPN都有边框回归的操作,区别在于EAST回归距离ground truth的上下左右边的距离和角度,ctpn回归中心点的偏移和高度的尺度。而PixelLink都是分类任务,没有回归任务。带来的优势就是,训练更容易学习,训练速度更快,效果更好。甚至都不需要使用ImagnetNet的权值进行微调。