1. 流水线(Pipeline)
MCU/CUP的设计都会涉及到流水线,此处主要介绍AMD/Inter的PC计算机CPU的流水线。
所有的X86处理器都按照相同的模式运行。首先,根据指令指针指向的地址取得下一条即将运行的指令并解析该指令(译码)。在译码完成后,会有一个指令的执行阶段。有些指令用来从内存读取数据或者向内存写数据,有些指令用来执行计算或者比较等工作。当指令执行完成后,这条指令会通过退出(retire)阶段并将指令指针修改为下一条指令。译码,执行和退出三级流水线组成了X86处理器指令执行的基本模式。从最初的8086处理器到最新的酷睿i7处理器都基本遵循了这样的过程。虽然更新的处理器增加了更多的流水级,但基本的模式没有改变。
我们可以把一条指令的执行周期分为五个单独的过程,取指,译指,执行,访存,回写。

这样的单级流水线,会面临一个重大的问题,即五个单独的过程中,有一个过程如果耗时太长,会导致个流水线堵塞,非常影响效率。因为如此,CPU设计引入了多级流水线,不会因为一级堵塞,导致整个流水线堵塞。下面是586的五级流水线:

随着CPU技术的发展,流水线级数最大已经有31级
2. 分支预测(Branch Prediction)
随着流水线级数的增加,对流水线代码执行的优化变得可能了。
2.1. 分支判断
虽然同一时间,流水线中执行了多条指令,但是分支判断带来的跳转,导致无法正确顺序地载入对应的跳转代码进流水线。必须当判断代码执行之后,才知道加载哪处的跳转指令。然后才能将对应的跳转代码加载进流水线,这个非常影响流水线并行执行的效率。也就是说在分支(Branch)判断执行完之后,才能引入新的指令进入流水线,在执行这个判断的过程,整个流水线都是等待的。
2.2. 分支预测器(Branch Predictor)
为了解决上述问题,流水线中引入了分支预测器来完成分支预测机制。分支预测就是通过预测,把接下来最有可能执行的分支获取进入流水线,就像不存在对比较结果的依赖那样直接执行,这么一来就保持了指令的流畅执行,这也被称为Speculative Execution。不过这种通过预测获取进入pipeline的分支终究只是预测分支,实际上不一定是执行这一分支,因此这部分指令的执行结果不应该从pipeline中输出,即不应该执行retirement这一步骤。在得到比较结果后,就能知道预测的分支是否为实际应该执行的分支,如果是,pipeline中的预测分支指令就能继续执行下去,否则就需要把预测分支的指令排空,重新获取正确分支的指令进入pipeline继续执行。
分支预测,可能的方法有很多种。如:分支判断可能的结果是A和B,最差的情况是永远将分支判断的A指令加入流水线,如果真实判断时是A,那就直接执行,如果是B那么再重新加入B也可以,效率能够提高。实际的分支预测中,可能存入很多种方法,也会有固件的模式(Pattern)来适应。如改进上术的分支预判,当有一次实际判断为B时,后面的全部就预判断为B。上面只是简单的介绍一下分支预测的最简单模式,实际现在CPU的分支预测越来越强大,适应的模式越来越多。像AMD的新款Ryzen处理器,已经使用神经网络的机器学习来强化分支预测了。
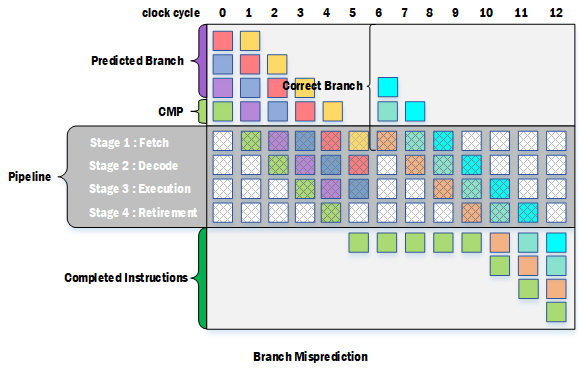
3. 实际应用
3.1. 测试代码
void TestBranchPrediction()
{
const int ARRAY_SIZE = 32768;
int data[ARRAY_SIZE] = {0};
for (int nIdx = 0; nIdx < ARRAY_SIZE; ++nIdx)
data[nIdx] = std::rand() % 256;
/********************************Mode 1**************************************/
long long sum = 0;
DWORD dwStart = GetTickCount();
for (int nCycle = 0; nCycle < 10000; ++nCycle)
{
for (int nIdx = 0; nIdx < ARRAY_SIZE; ++nIdx)
{
if (data[nIdx] >= 128)
sum += data[nIdx];
}
}
DWORD dwEnd = GetTickCount();
std::cout<<"Mode 1 Elapsed Time:"<<dwEnd-dwStart<<"-Sum:"<<sum<<std::endl;
/********************************Mode 2**************************************/
sum = 0;
DWORD dwStart2 = GetTickCount();
for (int nCycle = 0; nCycle < 10000; ++nCycle)
{
for (int nIdx = 0; nIdx < ARRAY_SIZE; ++nIdx)
{
int nTemp = (data[nIdx] - 128) >> 31;
sum += (~nTemp & data[nIdx]);
}
}
DWORD dwEnd2 = GetTickCount();
std::cout<<"Mode 2 Elapsed Time:"<<dwEnd2-dwStart2<<"-Sum:"<<sum<<std::endl;
/********************************Mode 3**************************************/
std::sort(data, data + ARRAY_SIZE);
sum = 0;
DWORD dwStart3 = GetTickCount();
for (int nCycle = 0; nCycle < 10000; ++nCycle)
{
for (int nIdx = 0; nIdx < ARRAY_SIZE; ++nIdx)
{
if (data[nIdx] >= 128)
sum += data[nIdx];
}
}
DWORD dwEnd3 = GetTickCount();
std::cout<<"Mode 3 Elapsed Time:"<<dwEnd3-dwStart3<<"-Sum:"<<sum<<std::endl;
}3.2. 测试结果
测试环境:VS2010,64Bit,i5-4590
Mode 1 Elapsed Time:998-Sum:31227540000
Mode 2 Elapsed Time:344-Sum:31227540000
Mode 3 Elapsed Time:156-Sum:31227540000
3.3. 分析
Mode1
data是乱序的,那么作为分支判断的if (data[nIdx] >= 128)语句的判断也会是乱序的。那么在CPU的分支预判断时,会有近关的概念是判断错误的,而判断分支预测的错误,直接导致流水线执行效率的降低。因为每次错误的预测而加入流水线的指令,其实是错误的,必须在真实判断时,重新将正确的指令加入流水线。Mode2
下面两行指令,相当于将分支判断语句转换成直接移位加计算语句了,虽然增加了实际的机器指令数,但是消除了分支判断。int nTemp = (data[nIdx] - 128) >> 31; sum += (~nTemp & data[nIdx]);因为消除了分支判断,能够提升流水线并行执行代码的效率,所以此种方式的实际结果也是优于乱序流水线分支判断的。
Mode3
此模式下,加入了std::sort(data, data + ARRAY_SIZE);排序语句将
data变为有序的了,这样在分支预测时,分支预测器就能够比较好的对进入流水线的指令进行优化了。分支判断的实际跳转的代码结果为A处和B处。分支判断第一次判断为A之后,分支预测器就不再等等分支判断的实际结果出来了再将指令取入流水线,而是在分支判断进入流水线之后,直接代跳转地址A处的指令取入流水线,这样就能够让流水线并行执行,提高效率。直到下次实际判断的改变,分支预测器又将预测的结果设定为B,然后直接将B处的跳转指令和分支指令一起移入流水线。这样一个简单的分支预测Patten,就能够让流水线并行执行而不因为分支判断被打断。实际测试的结果也是如此。4. 结论
- 在效率不是关键瓶颈时,不必过于花时间去优化分支判断,交给CPU去智能分支判断即可。
- 在效率是关键瓶颈时,在大量循环语句里,需要优化分支判断,让判断是有规律的,可以是有序的,也可以是其他规律,这样CPU的分支预测才会找到适应的Pattern。
- 如果无法去优化分支判断,如果可以代码运算来避免分支判断,也可以达到消除无序分支判断给流水线带来的妨碍。
5. 引用参考
- Branch predictor
- Why is it faster to process a sorted array than an unsorted array?