现代计算机和编译器的结构更加智能化,会想尽办法去把CPU所有部件全部利用起来,不想让CPU的任何区域出现空闲
我前面的文章提到过simd优化,将CPU的数据位宽利用起来,CPU累加器在单个时钟周期里并行完成数据位宽/数据类型大小的计算,对32位操作系统而言,32位的宽度能放下4个float类型的数据,也就能一次完成一个四维向量的累加计算,大大利用了总线的宽度
下面将介绍另一种能“压榨”计算机性能的优化手段
分支预测
分支预测(Branch Prediction)是从Pentium5代开始的一种先进的,解决处理分支指令(if-then-else)导致流水线失败的数据处理方法,由CPU来判断程序分支的进行方向,能够加快运算速度。
先看个程序
写一个程序,产生32768个从0到256的随机数,然后依次判断是否大于128,如果大于则累计
重复这个过程100000次,将最后的时间统计出来
首先是没有排序的数组:
#include <algorithm>
#include <ctime>
#include <iostream>
#define ARRAYSIZE 32768
int main()
{
// 产生数组
int data[ARRAYSIZE] ;
// 将数组1到1024之间的随机数填充
for (int i = 0; i < ARRAYSIZE; ++i)
{
data[i] = std::rand() % 256;
}
//排序函数,一会将比较它开没有开启的时间
//std::sort(data, data + ARRAYSIZE);
//记录开始时间
clock_t start_time = clock();
//循环求和
long long sum = 0;
//将主要计算部分执行100000次,减少误差
for (int i = 0; i < 100000; ++i)
{
// 主要计算部分,选大于128的数字累加,即中间大小的数字
for (int j = 0; j < ARRAYSIZE; ++j)
{
if (data[j] >= 128)
{
sum += data[j];
}
}
}
//记录结束时间
clock_t end_time = clock();
//计算出累加部分花费的时间
double ElapsedTime = static_cast<double>(end_time - start_time) / CLOCKS_PER_SEC;
//打印累加时间
std::cout << "ElapsedTime:" << ElapsedTime << std::endl;
}注意,排序注释掉了
//std::sort(data, data + ARRAYSIZE);运行结果:

将排序打开:
std::sort(data, data + ARRAYSIZE);运行结果:

可见对随机数组排序前和排序后的结果性能差距大于三倍
在java下的运行结果
import java.util.Arrays;
import java.util.Random;
public class Main
{
public static void main(String[] args)
{
int ArraySize = 32768;
// 产生数组
int data[] = new int[ArraySize];
// 将数组1到1024之间的随机数填充
Random rnd = new Random(0);
for (int i = 0; i < ArraySize; ++i)
data[i] = rnd.nextInt() % 256;
//排序函数,一会将比较它开没有开启的时间
//Arrays.sort(data);
//记录开始时间
long start_time = System.nanoTime();
//循环求和
long sum = 0;
//将主要计算部分执行100000次,减少误差
for (int i = 0; i < 100000; ++i)
{
// 主要计算部分,选大于128的数字累加,即中间大小的数字
for (int j = 0; j < ArraySize; ++j)
{
if (data[j] >= 128)
sum += data[j];
}
}
//记录结束时间
long end_time = System.nanoTime();
//计算出累加时间
System.out.println("ElapsedTime:"+(end_time - start_time) / 1000000000.0);
}
}在有没有开启Arrays.sort(data)的条件下
Arrays.sort(data);结果为:
没有开启排序

开启排序后

性能差距也在三倍以上
而且java比C++的运行的效率更高,可能做了其他优化,这里以后再找原因
对于data[j] >= 128
每回判断的时候需要暂停下来,等判断完成再进入到后面,那是不是可以预测它的结果,然后可以直接进入下一步,然后在进行下一步的同时进行判断,实际上程序就是这么做的,下面将展开介绍这种原因出现的原因
关于CPU流水线
cpu流水线技术是一种将指令分解为多步,并让不同指令的各步操作重叠,从而实现几条指令并行处理,以加速程序运行过程的技术。 指令的每步有各自独立的电路来处理,每完成一步,就进到下一步,而前一步则处理后续指令。
对于CPU的管线里面,存在以下四个步骤:
- 读取指令(Fetch)
- 指令解码(Decode)
- 运行指令(Execute)
- 回写(Write-back)
对于一条指令会分别在四个区域执行,那么如果要等一条指令执行的时候,才开始执行后一条指令的,那么就会有三个区域是空闲的

那么可不可以在第一条指令进行到后面步骤的时候,再载入后面的指令那,答案是可以的,那么就会变成下图所示:

那么一条流水线就会同时运行四条指令
但是,条件跳转指令,只要当前面的指令运行到执行阶段,才能知道要选择的分支
当遇到判断的时候,就会造成流水线冒泡(bubbling),造成流水线利用率降低

分支预测
结合上面的问题,那么就可以提前预测结果,然后让流水线保持运载运行,然后同时判断预测结果是否正确
如果预测正确,那就继续执行
如果预测失败,那就冲刷流水线,重新获取指令、译码
那么对于下面程序来说
// 主要计算部分,选大于128的数字累加,即中间大小的数字
for (int j = 0; j < ARRAYSIZE; ++j)
{
if (data[j] >= 128)
{
sum += data[j];
}
}给分支走向给下面两个标记
T = 分支命中
N = 分支没有命中
如果分支排序过,就会有下面的branch:
data[] = 226, 185, 125, 158, 198, 144, 217, 79, 202, 118, 14, 150, 177, 182, 133, ...
branch = T, T, N, T, T, T, T, N, T, N, N, T, T, T, N ...完全不可预测
如果数组没有排序过,就会有下面的branch:
data[] = 0, 1, 2, 3, 4, ... 126, 127, 128, 129, 130, ... 250, 251, 252, ...
branch = N N N N N ... N N T T T ... T T T ...前面全是false,后面全是true
很显然就可以预测了
可预测就可以跳过条件跳转指令,从而提高了流水线的占用率,程序就会快了
如何避免分支预测提高程序的运行效率呢
我这里先提供 两个方案:
利用表查询:
如果事先对数组排序消耗很大,这里用到了表查询的技巧
int lookup[256];
for (int i = 0; i < 256; ++i)
{
lookup[i] = (i >= 128) ? i : 0;
}构造一张表,将不符合的位置记录为0,符合的数字记为自己本身
for (unsigned i = 0; i < ARRAY_SIZE; ++i)
{
sum += lookup[data[i]];
}累加的时候,没有判断,只不过不符合的数字全部加为0,这样就避免了分支判断
利用位运算取消分支跳转:
通过data[i] - 128计算出正负值
(data[i] - 128)>>31右移31位,若小于128得到-1,大于等于128得到0
-1转换为二进制为0xffff,0为0x0000
用~反转一下
若为正确的数字和0xffff与一下,则是原来的数字
若不正确和0x0000与一下,就是0了
for (unsigned i = 0; i < ARRAY_SIZE; ++i)
{
int t = (data[i] - 128) >> 31;
sum += ~t & data[i];
}分支预测分类
分支预测技术包含编译时进行的静态分支预测和硬件在执行时进行的动态分支预测
最简单的静态分支预测方法就是任选一条分支。这样平均命中率为50%,更精确的办法是根据原先运行的结果进行统计从而尝试预测分支是否会跳转
动态分支预测是近来的处理器已经尝试采用的的技术。最简单的动态分支预测策略是分支预测缓冲区(Branch Prediction Buff)或分支历史表(branch history table)
下面介绍两种预测分类
1-bit动态预测
根据该指令上次是否跳转来预测此次是否跳转。如果上次跳转,则预测此次也会跳转
对于上面排好的数组简直是太适用了,这个预测只在开始和中间部分会改变两次,剩下就不会发生分支预测失效了
2-bit动态预测
这种预测又称为双模态预测器或者饱和预测器
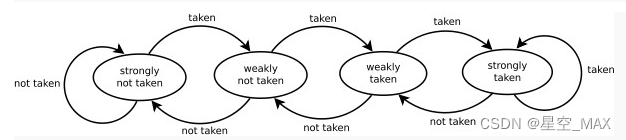
分为00 01 10 11四种状态
当处于00和01状态时候预测为采纳分支
当处于10和11状态时候预测为不采纳分支
当预测为采纳的时候向左推一个状态,如果为00态则保持不变
当预测为不采纳分支的时候向左推一个状态,如果为11态则保持不变
该条件分支指令必须连续选择某条分支两次,才能从强状态翻转,从而改变了预测的分支
适合一直稳定突然出现变化的情况
两级自适应预测器:
简单来说就是可以记录周期性的跳转,能预测一个模式
分两个部分,前面是一个分支历史寄存器,后面跟了一个饱和预测器
对于001001001001的情况而言
拿一个2-bit自适应预测器来说,前面历史记录器发现00,然后跳转到后面的饱和预测器,就能马上判断是1的可能性大了

根据饱和寄存器A中的状态机状态,下一个为1的可能性能极大 ,这就是大致原理
下面是一张4-bit的自适应器

分支历史表更大了,其他原理一样
对于n-bit的BHR而言,可以准确追踪重复周期在n以内的分支历史pattern。如果程序中某个分支历史的pattern周期超过n,性能就会受到影响
当然还有其他分支预测器,这里就不展开介绍了