目标
最近实验室里成立了一个计算机兴趣小组
倡议大家多把自己解决问题的经验记录并分享
就像在CSDN写博客一样
虽然刚刚起步
但考虑到后面此类经验记录的资料会越来越多
所以一开始就要做好模板设计(如下所示)

方便后面建立电子数据库
从而使得其他人可以迅速地搜索到相关记录
据说“人生苦短,我用python”
所以决定用python从docx文档中提取文件头的信息
然后把信息更新到一个xls电子表格中,像下面这样(直接po结果好了)
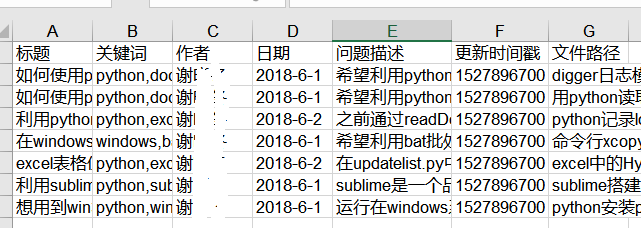
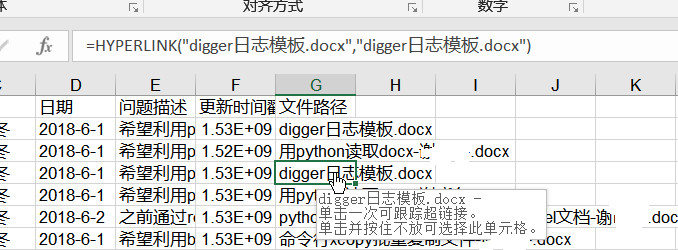
而且点击文件路径可以直接打开对应的文件(含超链接)
代码实现
1. 采集docx里面文件头信息
# -*- coding:utf-8 -*-
# 此程序可扫描Log中的docx文件并返回基本信息
import docx
from docx import Document
test_d = '../log/sublime搭建python的集成开发环境.docx'
def docxInfo(addr):
document = Document(addr)
info = {'title':[],
'keywords':[],
'author':[],
'date':[],
'question':[]}
lines = [0 for i in range(len(document.paragraphs))]
k = 0
for paragraph in document.paragraphs:
lines[k] = paragraph.text
k = k+1
index = [0 for i in range(5)]
k = 0
for line in lines:
if line.startswith('标题'):
index[0] = k
if line.startswith('关键词'):
index[1] = k
if line.startswith('作者'):
index[2] = k
if line.startswith('日期'):
index[3] = k
if line.startswith('问题描述'):
index[4] = k
k = k+1
info['title'] = lines[index[0]+1]
keywords = []
for line in lines[index[1]+1:index[2]]:
keywords.append(line)
info['keywords'] = keywords
info['author'] = lines[index[2]+1]
info['date'] = lines[index[3]+1]
info['question'] = lines[index[4]+1]
return info
if __name__ == '__main__':
print(docxInfo(test_d))# -*- coding:utf-8 -*-
# 此程序可以批量扫描log中的文件,如果碰到docx文档,
# 则调用readfile()提取文档信息,并将信息保存到digger
# 日志列表.xls之中,方便后期快速检索
import os,datetime
import time
import xlrd
from xlrd import xldate_as_tuple
import xlwt
from readfile import docxInfo
from xlutils.copy import copy
# 打开日志列表读取最近一条记录的更新日期
memo_d = '../log/digger日志列表.xls'
memo = xlrd.open_workbook(memo_d) #读取excel
sheet0 = memo.sheet_by_index(0) #读取第1张表
memo_date = sheet0.col_values(5) #读取第5列
memo_n = len(memo_date) #去掉标题
if memo_n>0:
xlsx_date = memo_date[memo_n-1] #读取最后一条记录的日期,
latest_date = sheet0.cell_value(memo_n-1,5)
# 返回时间戳
# 新建一个xlsx
memo_new = copy(memo)
sheet1 = memo_new.get_sheet(0)
# 重建超链接
hyperlinks = sheet0.col_values(6) # xlrd读取的也是text,造成超链接丢失
k = 1
n_hyperlink = len(hyperlinks)
for k in range(n_hyperlink):
link = 'HYPERLINK("%s";"%s")' %(hyperlinks[k],hyperlinks[k])
sheet1.write(k,6,xlwt.Formula(link))
k = k+1
# 判断文件后缀
def endWith(s,*endstring):
array = map(s.endswith,endstring)
if True in array:
return True
else:
return False
# 遍历log文件夹并进行查询
log_d = '../log'
logFiles = os.listdir(log_d)
for file in logFiles:
if endWith(file,'.docx'):
timestamp = os.path.getmtime(log_d+'/'+file)
if timestamp>latest_date:
info = docxInfo(log_d+'/'+file)
sheet1.write(memo_n,0,info['title'])
keywords_text = ','.join(info['keywords'])
sheet1.write(memo_n,1,keywords_text)
sheet1.write(memo_n,2,info['author'])
sheet1.write(memo_n,3,info['date'])
sheet1.write(memo_n,4,info['question'])
#获取当前时间
time_now = time.time() #浮点值,精确到毫秒
sheet1.write(memo_n,5, time_now)
link = 'HYPERLINK("%s";"%s")' %(file,file)
sheet1.write(memo_n,6,xlwt.Formula(link))
memo_n = memo_n+1
os.remove(memo_d)
memo_new.save(memo_d)
print('memo was updated!')其实还有一些操作电子表格更好的模块,比如panda、xlsxwriter、openpyxl等。不过上述代码已经基本能实现功能,而且科研狗毕竟没那么多时间写代码做调试,所以后面有空再update吧!