一、前言
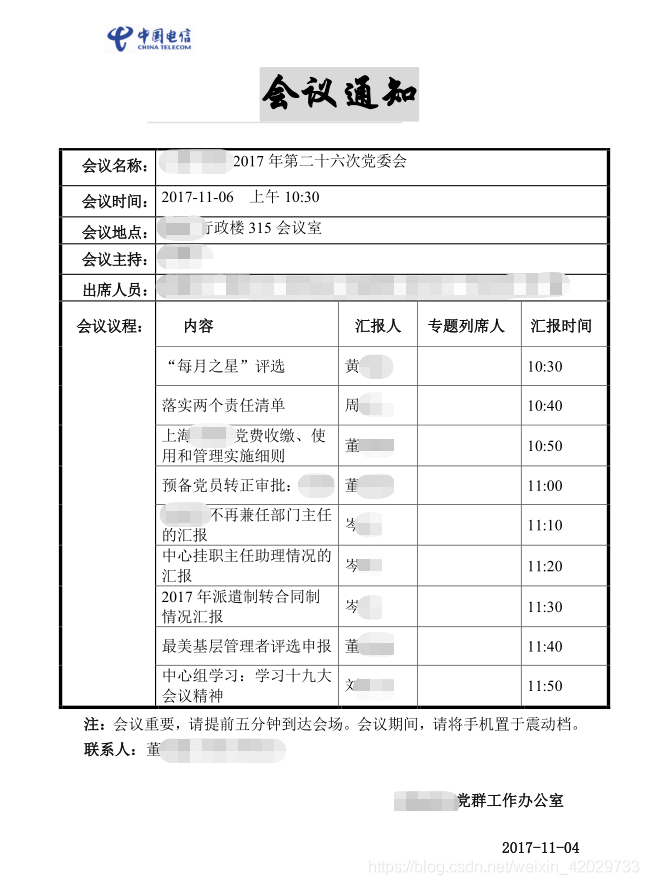
新部门接到一个新需求,要求根据以前的会议纪要,提取相关信息(如下图所示)

包括了会议名称、时间、地点、主持人、出席人员、列席人员、缺席人员、会议内容、汇报人、列席人等等,然后要生成两样东西:
1、会议通知
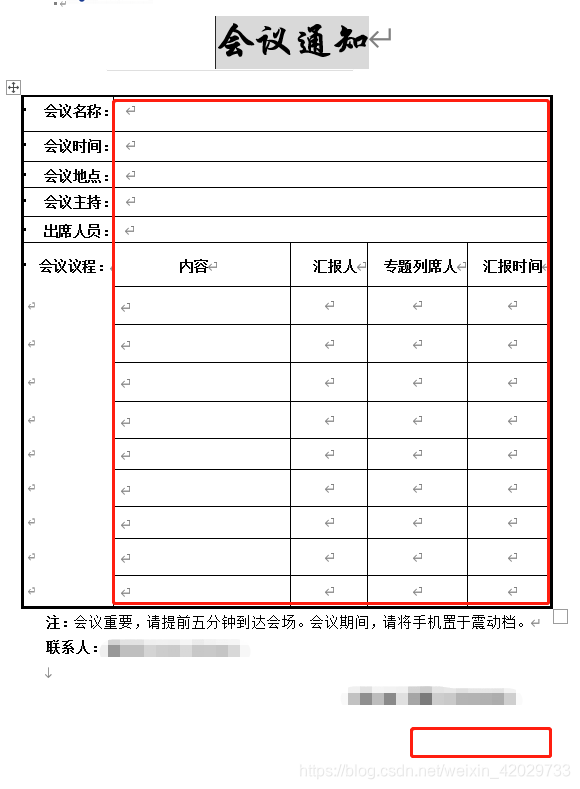
右下角是会议通知时间,根据会议时间往前倒推两天自动生成。
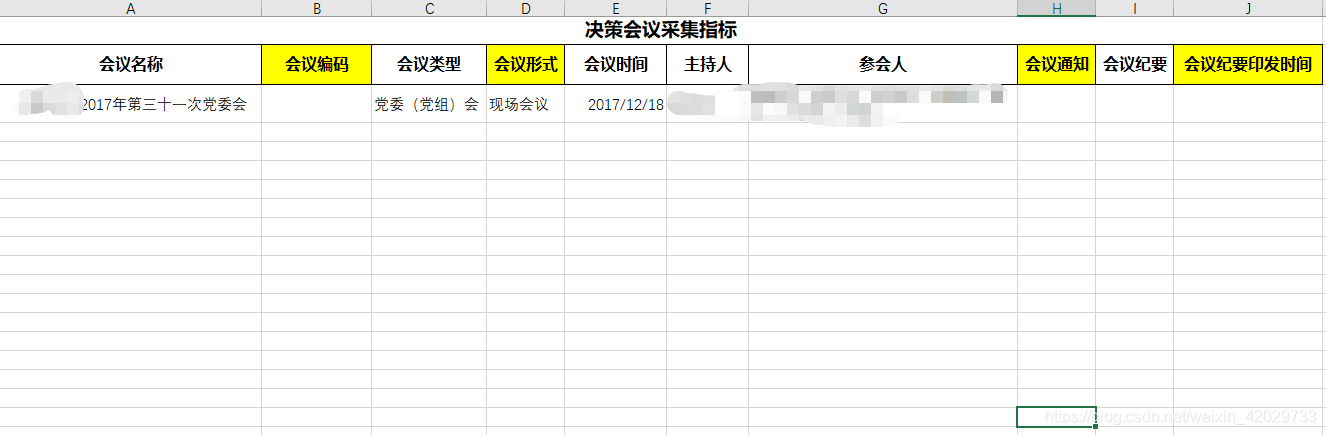
2、会议总表
二、主要难点
1、原来的文件都是doc格式的,python的docx库不能读取,所以必须要靠win32转换成docx;
2、对docx的库使用不多,所以提取和写入表格的代码都是百度了好久获得的;
3、写入excel不难,只是参会人要把“出席人员”、“列席人员”和“缺席人员”组合起来,会议时间也只要日期不要时间;
4、最后还需要把word转成pdf,又使用了win32的库。
三、具体代码
# coding=gbk
import docx
from win32com.client import Dispatch
from docx.shared import Pt
from docx.enum.text import WD_ALIGN_PARAGRAPH
import os
import datetime
import traceback
def excel_pre():
'''启动excel和路径设置'''
global xl
xl = Dispatch("Excel.Application")
xl.Visible = False #True是显示, False是隐藏
xl.DisplayAlerts = 0
def doc2Docx(fileName):
'''将doc转换为docx'''
word = Dispatch("Word.Application")
doc = word.Documents.Open(fileName)
doc.SaveAs(fileName + "x", 12, False, "", True, "", False, False, False, False)
os.remove(fileName)
doc.Close()
word.Quit()
def dict_judge(text):
'''判断text中是否存在dict中的key'''
num_dict = {'一、':1, '二、':2, '三、':3, '四、':4, '五、':5, '六、':6, '七、':7, '八、':8, '九、':9}
for key,value in num_dict.items():
if key in text:
return value
return 0
def notice_time(meeting_time, timedelta=-2):
'''根据会议时间倒推会议通知时间'''
a = datetime.datetime.strptime(meeting_time, "%Y-%m-%d")
b = a + datetime.timedelta(days=timedelta)
c = b.strftime('%Y-%m-%d')
return c
def report_time(meeting_time, num):
'''模拟生成汇报时间report_time'''
if '午' in meeting_time:
meeting_time = meeting_time.replace('午', '0')
a = datetime.datetime.strptime(meeting_time, '%H:%M')
if num ==1:
return meeting_time
else:
b = a + datetime.timedelta(minutes=10*(num-1))
c = b.strftime('%H:%M')
return c
def doc2pdf(input_file):
'''把word转成pdf'''
word = Dispatch('Word.Application')
doc = word.Documents.Open(input_file)
doc.SaveAs(input_file.replace(".docx", ".pdf"), FileFormat=17)
doc.Close()
word.Quit()
def set_font(paragraph):
'''设定word中的字体大小'''
paragraph.paragraph_format.left_indent = Pt(0) #取消左缩进
paragraph.paragraph_format.right_indent = Pt(0) # 取消右缩进
run = paragraph.runs
font = run[0].font
font.size= Pt(14) #14对应四号字体
# font.bold = True #加粗
def get_meeting_info(docname):
'''提取会议纪要里的内容'''
doc = docx.Document(meeting_file_path + docname)
meeting_name = docname.replace('纪要.docx', '')
meeting_name = '上海NOC ' + meeting_name
meeting_dict = {'会议名称':meeting_name, '会议时间': '', '主持人': '', '参会人': ''}
notice_dict = {'会议名称':meeting_name, '会议时间':'', '会议地点':'', '会议主持':'', '出席人员': ''}
joiner = ''
for i, paragraph in enumerate(doc.paragraphs):
this_text = paragraph.text
num = dict_judge(this_text)
if '会议时间' in this_text:
this_text = this_text.split(':')[1]
notice_dict['会议时间'] = this_text
meeting_date = this_text[:10] #会议日期
meeting_time = this_text[-5:] #会议时间
notice_date = notice_time(meeting_date)
meeting_dict['会议时间'] = meeting_date
notice_dict['通知时间'] = notice_date
elif '会议地点' in this_text:
this_text = this_text.split(':')[1]
notice_dict['会议地点'] = this_text
elif '会议主持' in this_text:
this_text = this_text.split(':')[1]
meeting_dict['主持人'] = notice_dict['会议主持'] = this_text
elif '出席人员' in this_text:
this_text = this_text.split(':')[1]
# notice_dict['出席人员'] = this_text
joiner = joiner + this_text + '、'
elif '列席人员' in this_text:
this_text = this_text.split(':')[1]
joiner = joiner + this_text + '、'
elif '缺席人员' in this_text:
this_text = this_text.split(':')[1]
if this_text == '无':
joiner = joiner[:-1]
else:
joiner = joiner + this_text
elif num:
this_title = this_text.split('、', 1)[1].replace('。', '')
try:
this_reporter = doc.paragraphs[i+1].text.split(':', 1)[1]
if '回避' in this_reporter:
this_reporter = this_reporter.split('(', 1)[0]
except:
this_reporter = ''
if '列席人' in this_reporter:
this_reporter, liexiren = this_reporter.split('(', 1)
liexiren = liexiren.split(':')[1].replace(')', '')
else:
liexiren = ''
this_report_time = report_time(meeting_time, num)
notice_dict[num] = [this_title, this_reporter, liexiren, this_report_time]
meeting_dict['参会人'] = joiner
if '(开会)' in joiner:
joiner = joiner.replace('(开会)', '')
notice_dict['出席人员'] = joiner
return meeting_dict, notice_dict
def make_report(report_dict):
'''制作会议通知'''
doc = docx.Document('会议通知模板.docx')
#插入主要通知内容
doc_cell_dict = {'会议名称': (0, 1), '会议时间': (1, 1), '会议地点': (2, 1), '会议主持': (3, 1), '出席人员': (4, 1)}
for key, value in doc_cell_dict.items():
doc.tables[0].rows[value[0]].cells[value[1]].text = report_dict[key]
paragraph = doc.tables[0].rows[value[0]].cells[value[1]].paragraphs[0]
set_font(paragraph)
#插入几个会议内容
for i in range(1, len(report_dict)-5):
doc.tables[0].rows[i + 5].cells[1].text = report_dict[i][0] # 会议内容
doc.tables[0].rows[i + 5].cells[2].text = report_dict[i][1] # 汇报人
doc.tables[0].rows[i + 5].cells[3].text = report_dict[i][2] # 专题列席人
doc.tables[0].rows[i + 5].cells[4].text = report_dict[i][3] # 汇报时间
for j in range(1, 5):
paragraph = doc.tables[0].rows[i + 5].cells[j].paragraphs[0]
set_font(paragraph)
#创建新的格式
try:
style1 = doc.styles['style head1']
except:
style1 = doc.styles.add_style('style head1', 2)
finally:
style1.font.bold = True
style1.font.name = u'宋体 (中文正文)'
style1.font.size = Pt(14)
#在最后插入通知时间
e = doc.add_paragraph()
e.paragraph_format.alignment = WD_ALIGN_PARAGRAPH.RIGHT #右对齐
e.add_run(report_dict['通知时间'], style=style1)
#最后根据名字保存会议通知
doc.save(report_file_path + '会议通知:'+ report_dict['会议名称'] + '.docx')
#把会议通知转成PDF格式
doc2pdf(report_file_path + '会议通知:'+ report_dict['会议名称'] + '.docx')
def make_newxls(meeting_dict, newrow):
'''把meetring的信息导入到excel里'''
ws.Cells(newrow, 1).Value = meeting_dict['会议名称']
ws.Cells(newrow, 3).Value = '党委(党组)会'
ws.Cells(newrow, 4).Value = '现场会议'
ws.Cells(newrow, 5).Value = meeting_dict['会议时间']
ws.Cells(newrow, 6).Value = meeting_dict['主持人']
ws.Cells(newrow, 7).Value = meeting_dict['参会人']
if __name__ == "__main__":
#如果原始文档是doc格式的话,就需要先批量转换为docx
# for f in os.listdir('会议纪要库'):
# if f.endswith('.doc'):
# doc2Docx(meeting_file_path + f)
meeting_file_path = os.path.abspath('.') + '\\' + '会议纪要库' + '\\'
report_file_path = os.path.abspath('.') + '\\' + '会议通知库' + '\\'
this_path = os.path.abspath('.') + '\\'
excel_pre()
wb = xl.Workbooks.Open(this_path + '决策会议采集模板.xls')
ws = wb.Sheets('决策会议')
n = 3
try:
for f in os.listdir('会议纪要库'):
if f.endswith('.docx'):
print(f)
# doc2pdf(meeting_file_path + f) # 把会议通知转成PDF格式(在“会议纪要库”里)
meeting_dict, notice_dict = get_meeting_info(f)
make_report(notice_dict) # 生成会议通知(在“会议通知库”里)
make_newxls(meeting_dict, n) #把记录放在《决策会议采集模板.xls》里
n +=1
except:
traceback.print_exc()
finally:
wb.Save()
wb.Close()
成果: