一.Kafka的持久化
1.数据持久化:
读操作:读的时候从文件中读就好了









- 发现线性的访问磁盘(即:按顺序的访问磁盘),很多时候比随机的内存访问快得多,而且有利于持久化;
- 传统的使用内存做为磁盘的缓存
- Kafka直接将数据写入到日志文件中,以追加的形式写入
2.日志数据持久化特性:
写操作:通过将数据追加到文件中实现
读操作:读的时候从文件中读就好了
3.优势:
读操作不会阻塞写操作和其他操作(因为读和写都是追加的形式,都是顺序的,不会乱,所以不会发生阻塞),数据大小不对性能产生影响;
没有容量限制(相对于内存来说)的硬盘空间建立消息系统;
线性访问磁盘,速度快,可以保存任意一段时间!
没有容量限制(相对于内存来说)的硬盘空间建立消息系统;
线性访问磁盘,速度快,可以保存任意一段时间!
4.持久化的具体实现:
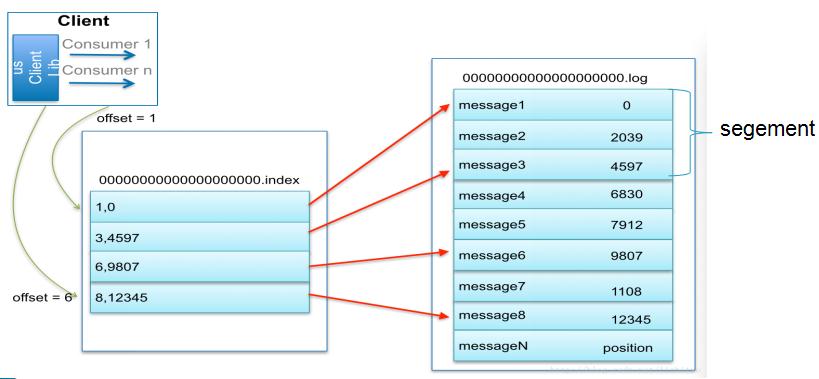
5.索引
为数据文件建索引:
稀疏存储,每隔一定字节的数据建立一条索引(这样的目的是为了减少索引文件的大小)。
下图为一个partition的索引示意图:
注:
1.现在对6.和8建立了索引,如果要查找7,则会先查找到8然后,再找到8后的一个索引6,然后两个索引之间做二分法,找到7的位置
2.每一个log文件中又分为多个segment
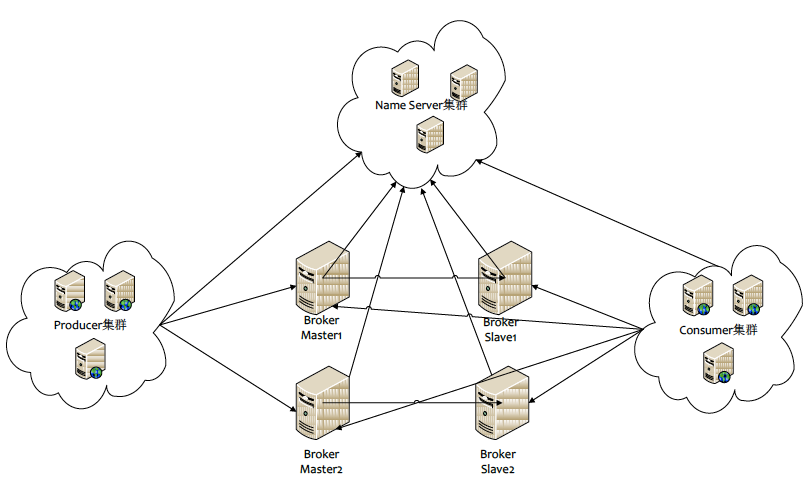
二.Kafka的分布式实现
注:
1.当生产者将消息发送到Kafka后,就会去立刻通知ZooKeeper,会往zookeeper的节点中去挂,
zookeeper中会watch到相关的动作,当watch到相关的数据变化后,会通知消费者去消费消息。
2.消费者是主动去Pull(拉)kafka中的消息,这样可以降低Broker的压力,因为Broker中的消息是无状态的,Broker也不知道哪个消息是可以消费的
3.当消费者消费了一条消息后,也必须要去通知ZooKeeper。zookeeper会记录下消费的数据,这样但系统出现问题后就可以还原,可以知道哪些消息已经被消费了
部署图:
Name Server集群即ZooKeeper集群
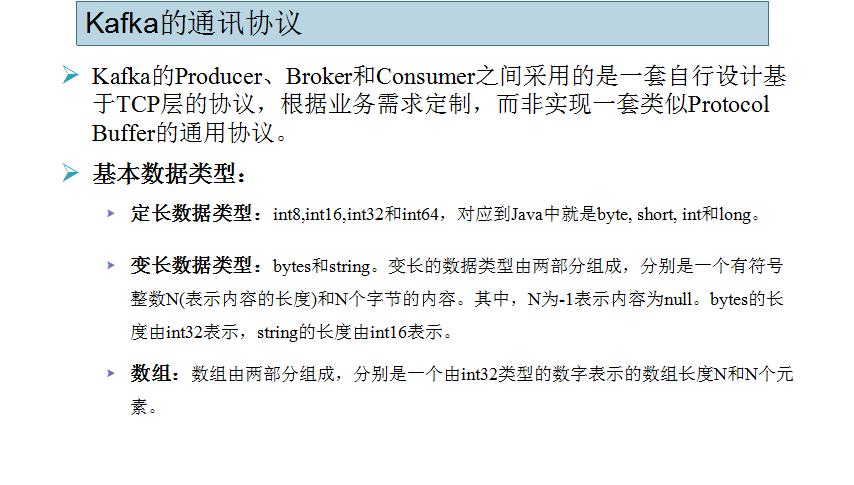
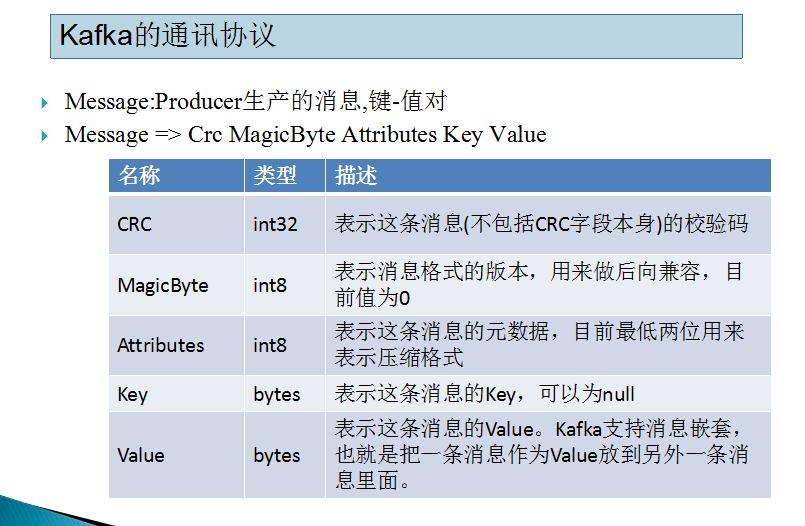
四.Kafka的通讯协议