原文转载于:https://blog.csdn.net/saga1979/article/details/44807813
概述:
Intel Threading Building Blocks (Intel® TBB)是基于任务(task)驱动的。一般来说,只有在TBB提供的算法模板中找不到合适的模板时,才考虑使用任务调度器自行实现。任务(task)是一个逻辑概念,操作系统并没有提供对应的实现。你可以把它当作线程池的进化。实现时,一个thread可对应多个task。在非阻塞编程时,相对于线程(thread),基于任务的编程有很多优点,比如:
- task的启动、停止通常比thread更快
- task更能匹配有效资源(因为有TBB的任务调度器)
- task在编程时使程序员更能专注业务实现而不是底层细节
- task实现了负载均衡
但是,要记住,task的应用场景是并行,而不是并发(不要企图把TBB用于Socket之类的并发 )。如果一个task被阻塞,其对应的thread也将被阻塞,这样,运行于thread之上的所有task都将被阻塞。task与thread的关系如下图:
)。如果一个task被阻塞,其对应的thread也将被阻塞,这样,运行于thread之上的所有task都将被阻塞。task与thread的关系如下图:
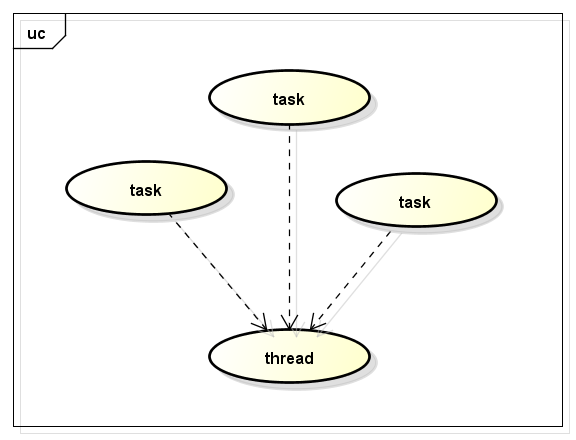
任务对象的生成
task的定义在task.h中,派生类必须要实现纯虚函数execute
-
//! Should be overridden by derived classes.
-
virtual task* execute() = 0;
task对象不能直接new,而是要使用TBB中重载的new操作符:
-
inline void *operator new( size_t bytes, const tbb::internal::allocate_root_proxy& )
-
inline void * operator new ( size_t bytes, const tbb::internal::allocate_root_with_context_proxy& p )
-
inline void * operator new ( size_t bytes, const tbb::internal::allocate_continuation_proxy& p )
-
inline void * operator new ( size_t bytes, const tbb::internal::allocate_child_proxy& p )
-
inline void * operator new ( size_t bytes, const tbb::internal::allocate_additional_child_of_proxy& p )
-
下面是TBB Tutorial中的示例:
-
-
-
-
-
using tbb::task;
-
-
long SerialFib(long n)
-
{
-
if (n < 2)
-
return n;
-
else
-
return SerialFib(n - 1) + SerialFib(n - 2);
-
}
-
-
class FibTask : public task
-
{
-
public:
-
const long n;
-
long* const sum;
-
FibTask( long n_, long* sum_) :
-
n(n_), sum(sum_)
-
{
-
}
-
task* execute()
-
{
-
if (n < 10)
-
{
-
*sum = SerialFib(n);
-
}
-
else
-
{
-
long x, y;
-
FibTask& a = * new(allocate_child()) FibTask(n - 1, &x);
-
FibTask& b = * new(allocate_child()) FibTask(n - 2, &y);
-
// ref_count的值为2+1(a+b+后面函数sapwn_and_wait_for_all产生的等待任务)
-
set_ref_count( 3);
-
spawn(b);
-
spawn_and_wait_for_all(a);
-
*sum = x + y;
-
}
-
return NULL;
-
}
-
};
-
-
long ParallelFib(long n)
-
{
-
long sum;
-
FibTask& a = * new(task::allocate_root()) FibTask(n, &sum);
-
task::spawn_root_and_wait(a);
-
return sum;
-
}
-
-
-
-
int main(int argc, char** argv)
-
{
-
using namespace tbb;
-
tick_count start = tick_count::now();
-
ParallelFib( 10);
-
tick_count end = tick_count::now();
-
printf( "tick count = %f\n", (end - start).seconds());
-
-
return 0;
-
}
任务的调度
调度器持有一个定向图表,每个节点对应一个任务对象。每个task指向它的继任者(successor),也就是指向等待它完成的任务(可以为空)。successor可以通过task::parent()得到。每个任务对象都包含一个引用计数,用来统计将此任务作为继任者的任务数量”。下图是斐波那契计算的任务图形快照:

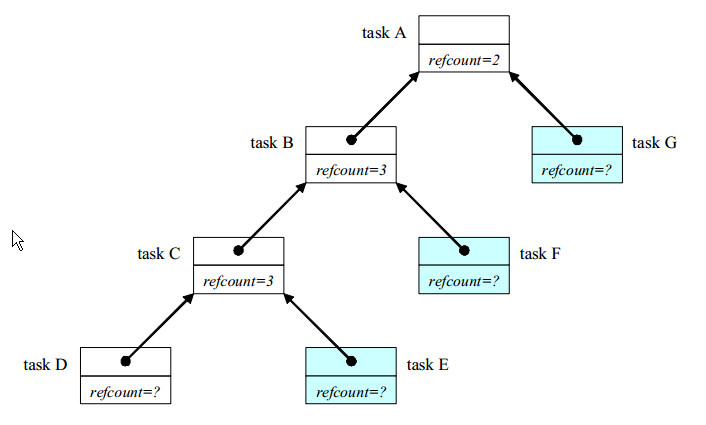
任务A、B、C都产生了子任务并等待其完成。它们的引用计数为子任务的数目+1.
任务D正在运行,但是没有产生子任务,所以不需要设置引用计数
任务E、F、G都没有开始执行(spawned,当时没有excuting)
调度器运行任务的方式倾向于最小化内存需求以及跨线程通讯。但也需要在两种执行方式(深度优先、广度优先)间达到平衡。假定树是固定的,深度优先就是最佳的顺序执行方式:
- 趁热打铁 最深层次的通常是最新创建的任务,因此在缓存(cache)中处于活跃状态。如果他们能完成,紧接着他们的任务就会被执行(比如D执行完后执行C),虽然不如第一个任务在缓存中的状态活跃,但相比创建事件更久的任务,它是最有效的。
- 最小化空间占用 执行最浅节点的任务会将树按照广度优先展开。这将同时创建指数级数量的节点。于此相比,深度优先只创建同等数量的节点,而且同一时间存在一个线性数量,因为它将其他准备好的任务压入堆栈。
虽然广度优先有着严重的内存占用问题,但在如果你拥有无数个物理线程,它能最大并行化。一般来说物理线程都是有限的,所以广度优先执行的数量让有效的处理器保持繁忙就够了。调度器实现了广度优先、深度优先的混合执行模式。每个线程都有自己的就绪任务队列。当一个线程产出一个任务时,就将此任务推入队列的底部。下图展示了上述任务图形快照中某个线程的任务队列,按照时间先后自顶向下排列:
| 任务 G |
| 任务 F |
| 任务 E |
线程的队列
线程执行任务的时候,按照以下规则从任务队列取得任务:
- 规则1:获取上一个task的execute方法返回的task,如果为空继续获取
- 规则2:从自身的队列底部弹出一个task,如果队列为空,继续下一条判断
- 规则3:随机选择一个任务队列,从其顶部“偷”一个task。如果选择的队列为空,继续遍历其余的队列,直到成功
规则2的效果就是执行本线程最近产出的任务,属于深度优先执行任务。规则3会从别的线程任务队列中选择最先产出的任务,发生广度优先任务执行,将潜在的并行变为实际的并行执行。作为任务演进图的一部分,获取任务是自动的。任务入队可以是显式的,也可以是隐式的。一个线程总是把任务加入自己队列的底部(不会加入另外线程的队列)。只有偷窃器才能把一个线程产出的任务传送到另外一个线程。在以下条件下,一个线程会将一个任务压入它的队列:
- 任务被此线程显式产出,比如方法spawn
- 一个任务被方法task::recycle_to_reexecute标记为再执行
- 一个线程执行完最后的前任任务,并且此后隐式地将任务的引用计数减少到0。如果这种情况发生,线程隐式的将后续任务推入他的队列底部。如果一个任务有外部引用,执行完它所有的孩子任务并不会导致它的引用计数为0
总体来说,任务调度的基本策略是“广度优先窃取,深度优先运行”。广度优先窃取准则会使线程保持繁忙,提升并行效率。深度优先运行准则会使每个线程在有足够工作需要做时,保持高效操作。
有用的任务技术
递归链式反应
如果任务图为树形结构,调度器能工作的最好。因为此时“广度优先窃取、深度优先执行”策略非常适合。而且,树形结构的任务图也能很快地为很多任务创建出来。比如,一个主控任务需要创建N个孩子,如果直接创建,需要O(N)个步骤。但使用树形结构叉分建立,只需要O(lg(N))个步骤。
一般情况下,问题都不是明显的树形结构,但可以轻松将他们映射到树。比如,parallel_for工作在迭代空间(比如,一个整数队列)。模板函数parallel_for使用定义将一个迭代空间递归映射到一个二叉树。
持续传递
spawn_and_wait_for_all方法使正在执行的父任务等待所有的子任务完成,但是会稍微影响一些性能。当一个线程调用这个函数时,它会保持繁忙直到所有的孩子任务完成。有些时候,父任务准备就绪,可以继续执行,但却不能马上开始,因为它的线程还在执行其他任务中的一个任务。解决方案是父任务不再等待它的孩子,而是产出子任务后返回。子任务不是被作为父任务的孩子被分配,而是作为父任务的持续任务(continuation task)。这样,空闲的线程在它的子任务完成后就能偷窃并运行持续任务。上述FibTask的“持续传递”变体如下:
-
struct FibContinuation : public task
-
{
-
long* const sum;
-
long x, y;
-
FibContinuation( long* sum_) : sum(sum_) {}
-
task* execute()
-
{
-
*sum = x + y;
-
return NULL;
-
}
-
};
-
struct FibTask : public task
-
{
-
const long n;
-
long* const sum;
-
FibTask( long n_, long* sum_) :
-
n(n_), sum(sum_)
-
{
-
}
-
task* execute()
-
{
-
if (n< 10)
-
{
-
*sum = SerialFib(n);
-
return NULL;
-
}
-
else
-
{
-
FibContinuation& c =
-
* new(allocate_continuation()) FibContinuation(sum);
-
FibTask& a = * new(c.allocate_child()) FibTask(n - 2, &c.x);
-
FibTask& b = * new(c.allocate_child()) FibTask(n - 1, &c.y);
-
// 这里的引用计数是2,而不是2+1.
-
c.set_ref_count( 2);
-
spawn(b);
-
spawn(a);
-
return NULL;
-
}
-
}
-
};
两个版本的以下不同点需要了解:
最大的区别是,在execute方法中,原来版本的x、y都是局部变量。在持续传递版本,它们就不能是局部变量了,因为父任务在子任务完成之前就返回了。作为替代方案,他们都是持续任务FibContinuation的字段。
改为使用allocate_continuation分配持续的任务。它与allocate_child类似,只是它的继任者(successor)是c而不是this,并且设置this的继任者为NULL,下面的图示了这种转换:
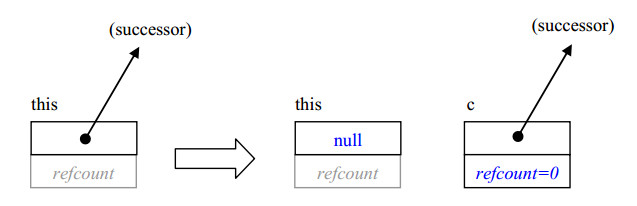
这种转换的一个属性就是它不改变继任者的引用计数,这样就避免了涉入引用计数逻辑。
引用计数被设置为2,子任务的数量。在初始版本,它被设置为3,因为spawn_and_wait_for_all需要增加计数。而且,代码设置持续任务(FibContinuation)而不是父任务的引用计数,因为是持续任务对象在等待子任务。
指针sum通过FibContinuation的构造函数传递给持续任务对象,因为现在是FibContinuation把计算结果保存到*sum。子任务仍然使用allocate_child分配,但是都作为c,而不是父节点的孩子。这样,当两个子任务完成后,就是c而不是this作为继任者被产出。如果你凑巧使用this.allocate_child(),父任务就会在两个子任务完成后再次运行。
如果大家还记得初始版本中的ParallelFib是怎么编写的,就也许会担心持续传递风格会打破这段代码,因为现在根FibTask在子任务完工之前完成,并且实现代码使用spawn_root_and_wait来等待根FibTask。这算不上问题,因为spawn_root_and_wait被设计的能与持续传递风格很好的工作。调用spawn_root_and_wait(x)并不真的等待x结束。实际上,它构造了X的一个亚元(dummy)继任者,并且等待继任者的引用计数被消减。因为allocate_continuation将此亚元继任者传递给持续任务,亚元继任者的引用计数会在持续任务完成后才递减。
调度旁路
调度旁路(scheduler bypass)是一种优化手段,此时你直接指定下一个要运行的任务。持续传递风格经常会为调度旁路开启机会。例如,在持续传递例子的最后,方法execute()产出任务“a”后返回。这会导致正在执行的线程做以下事情:
1. 将任务“a”入栈线程的任务队列
2. 从方法execute()返回
3. 将任务“a”出栈,如果它被别的线程“偷窃”
步骤1、3都是不必要的队列操作,更坏的是,允许“偷窃”会损害局部性而没有显著增加并行。方法execute()能通过返回一个指向“a”的指针而不是产出它来避免这些问题。由线程执行任务的规则1可知,“a”变为此线程的下一个要执行的任务。而且,这种方法保证执行任务“a”的是此线程,而不是另外的线程。
下面的示例显示了前一节的例子中必须要做的变更:
-
struct FibTask : public task
-
{
-
...
-
task* execute()
-
{
-
if (n<CutOff)
-
{
-
*sum = SerialFib(n);
-
return NULL;
-
}
-
else
-
{
-
FibContinuation& c =
-
* new(allocate_continuation()) FibContinuation(sum);
-
FibTask& a = * new(c.allocate_child()) FibTask(n - 2, &c.x);
-
FibTask& b = * new(c.allocate_child()) FibTask(n - 1, &c.y);
-
// Set ref_count to "two children".
-
c.set_ref_count( 2);
-
spawn(b);
-
spawn(a);
-
//return NULL;
-
return &a;
-
}
-
}
-
};
任务再生
不但可以绕过调度器,也可以绕过任务分配与再分配。这在递归任务执行调度旁路时,会有相应的更高几率发生。考虑前面的例子。当它创建了一个持续任务“c”,会执行下面的步骤:
1. 创建子任务“a”
2. 创建并产出子任务“b”
3. 从execute()方法返回指向任务“a”的指针
4. 销毁父任务
如果把“a”当作父任务,就可以避免上述的步骤1、4. 在很多场景中,步骤1需要从父任务中拷贝状态。将“a”当作父任务会消除拷贝开销。下面的例子显示了使用任务再生改造调度旁路的代码:
-
struct FibTask : public task
-
{
-
/*const*/ long n;
-
long* /*const*/ sum;
-
...
-
task* execute()
-
{
-
if (n< 10)
-
{
-
*sum = SerialFib(n);
-
return NULL;
-
}
-
else
-
{
-
FibContinuation& c =
-
* new(allocate_continuation()) FibContinuation(sum);
-
FibTask& a = * new(c.allocate_child()) FibTask(n - 2, &c.x);
-
FibTask& b = * new(c.allocate_child()) FibTask(n - 1, &c.y);
-
recycle_as_child_of(c);
-
n -= 2;
-
sum = &c.x;
-
// Set ref_count to "two children".
-
c.set_ref_count( 2);
-
spawn(b);
-
//return &a;
-
return this;
-
}
-
}
-
};
execute()方法现在返回this,而不是"a" 任务。调用recycle_as_child_of(c)有几种作用:
- 标记this在execute()返回后不能自动销毁
- 设置this的继任者为c
为了防止引用计数问题,recycle_as_child_of有个前置条件,那就是this的继任者必须为空。这是在allocate_continuation发生后的情况。下图显示了allocate_continuation、recycle_as_child_of如何转换任务图:
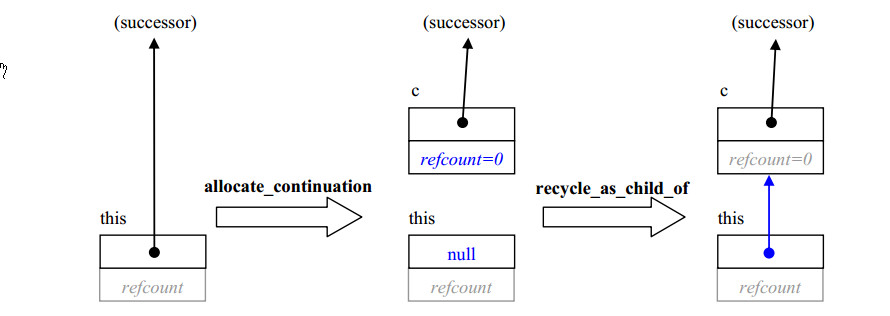
使用任务再生时,确保原始任务的字段在任务开始运行后不能处于被使用状态。例子使用调度旁路技术来确保这点。可以在产出时,当它的字段没有被使用时再产出再生任务。这个限制甚至适用于任何const字段,因为产出(spawning)后,任务可能在父任务没有任何动作的情况下运行并销毁。
一个类似的方法,task::recycle_as_continuation(),将一个任务作为一个持续任务而不是孩子任务。
总结
由于任务调度的复杂性,官方并不鼓励直接使用调度器,采用parallel_for、parallel_reduce等模板是个好主意。以下细节需要谨记:
-
使用new(allocation_method)T来分配一个task (allocation_method是task类的一种分配方法)。不要创建局部或者文件作用域的task实例
-
除非使用allocate_additional_child_of,否则在运行任何任务前,它的兄弟任务都必须分配完毕。
-
采用持续传递、绕过调度器,以及任务再生等技术榨取最大性能
-
如果一个任务完成了,并且没有被标记为再执行,就会自动销毁。同样,它的继任者的引用计数会减少,如果到了0,继任者会被自动产出