互斥控制某块代码能同时被多少线程执行。在Intel Threading Building Blocks(intelTBB)中,互斥通过互斥体(mutexes)和锁(locks)来实现。互斥体是一种对象,在此对象上,一个线程可以获得一把锁。在同一时间,只有一个线程能持有某个互斥体的锁,其他线程必须等待时机。
最简单的互斥体是spin_mutex。试图在spin_mutex上获得锁的线程要保持繁忙等待,直到成功。spin_mutex适合一个锁只被持有数个指令时常的情况。例如,下面的代码使用一个互斥体FreeListMutex来保护一个共享变量FreeList。它负责审查在同一时间只有一个线程访问FreeList。
-
Node* FreeList;
-
typedef spin_mutex FreeListMutexType;
-
FreeListMutexType FreeListMutex;
-
Node* AllocateNode()
-
{
-
Node* n;
-
{
-
FreeListMutexType:: scoped_lock lock(FreeListMutex);
-
n = FreeList;
-
if (n)
-
FreeList = n->next;
-
}
-
if (!n)
-
n = new Node();
-
return n;
-
}
-
void FreeNode(Node* n)
-
{
-
FreeListMutexType:: scoped_lock lock(FreeListMutex);
-
n->next = FreeList;
-
FreeList = n;
-
}
scoped_lock的构造子(构造函数)会一直等待,直到FreeListMutex上没有别的锁。析构子(析构函数)释放获得的锁。AllocateNode中的大括弧也许看起来不太常见。它们的作用是使锁的生命周期尽可能的短,这样其他的正在等待的线程就能尽可能快地得到机会。
注意:确保命名锁对象,否则它会被过快的销毁。例如,如果例子中的scoped_lock对象以如下方式创建
FreeListMutexType::scoped_lock (FreeListMutex);这样scoped_lock会在执行到分号处时销毁,即在FreeList被访问前释放锁。
编写AllocatedNode的另一种可选方式如下:
-
Node* AllocateNode()
-
{
-
Node* n;
-
FreeListMutexType::scoped_lock lock;
-
lock.acquire(FreeListMutex);
-
n = FreeList;
-
if (n)
-
FreeList = n->next;
-
lock.release();
-
if (!n)
-
n = new Node();
-
return n;
-
}
acquire方法在得到锁前会一直等待;release方法释放该锁。
推荐的做法是尽可能得加上大括弧,以使得那些代码被锁保护对于维护者来说更为清晰。
如果你很熟悉锁的C接口,也许会疑惑为什么在互斥体对象自身上没有获取、释放方法。原因是C接口不是异常安全的,因为如果被保护的区域抛出一个异常,控制流就会略过释放操作。借助面向对象接口,析构scoped_lock对象会致使锁的释放,无论是正常退出保护区域,还是因为异常。即使对于我们使用acquire、release方法实现的AllocateNode的版本也是这样的——显式释放让锁得以早点释放,而后,析构函数判断锁已经被释放,就不去操作锁了。
Intel TBB中所有的互斥体都有类似的接口,不但能让他们易于学习,还能适用于泛型编程。例如,所有的互斥体都嵌套一个scoped_lock类型,对于给定类型M,对应的锁类型是M::scoped_lock。
推荐为互斥体类型使用typedef,如同前面的例子所示。以这种方式,你可以稍后改变锁的类型而不用编辑其余的代码。在这些例子中,可以使用typedef queuing_mutex FreeListMutexType来代替 typedef spin_mutex FreeListMutexType(及使用queuing_mutex代替spin_mutex),代码仍然正确。
互斥体要素
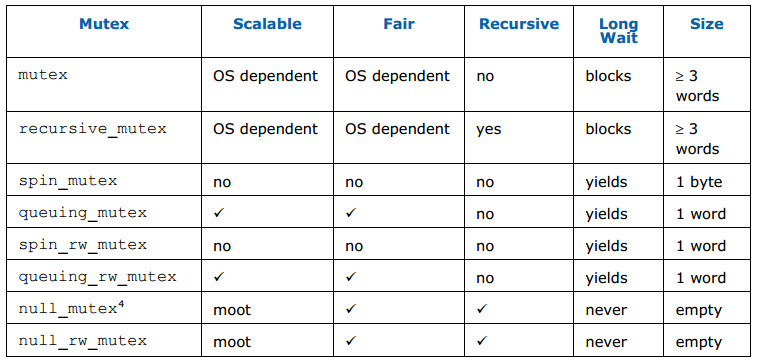
互斥体的行家总结了互斥体的各种特性。知道这些是有帮助的,因为它们影响通用性、性能的权衡。选择正确会有助于性能提升。互斥体能以下面的要素描述:
- 可伸缩性 一些互斥体被称为可伸缩的。在严格意义上,这不是一个准确的名字,因为互斥体限制在某个时间某个线程的执行。一个可伸缩的互斥体是不会比这个做的更差。如果等待线程消耗了大量的处理器循环和内存带宽,减少了线程做实际工作的速度,此时互斥体会比串行执行更糟糕。在轻微竞争的情况下,可伸缩互斥体通常要比非可伸缩互斥体要慢,此时非可伸缩互斥体要优于前者。如果有疑惑,就使用可伸缩互斥体。
- 公平 互斥体可以是公平或者非公平的。公平的互斥体按照线程到达的顺序使其通过,防止饿死线程。每个线程依序进行。然而,非公平互斥体会更快,它们允许正在运行的线程先通过,而不是下一个也许因为某个中断正在睡眠的在线(in line)线程。
- 递归 互斥体可以是递归的,也可以是非递归的。可递归互斥体允许线程在持有此互斥体锁的情况下再次获得锁。这在一些递归算法中很有用,但也增加了锁实现的开销。
- 放弃或者阻塞 这是影响性能的实现细节。在长等待时,Intel TBB的互斥体要么放弃(yields)要么阻塞(blocks)。这里的放弃(yields)的意思是,重复轮询看能否有进展,如果不能,就暂时放弃处理器的使用权。阻塞意味着直到互斥体完成处理才释放处理器。如果等待短暂,就使用放弃互斥体;如果等待时间往往比较长,就使用阻塞互斥体。(在windows系统中,yield通过SwitchToThread()实现,其他系统中通过sched_yield() 实现)
下面是互斥体的行为总结:
- spin_mutex 非可伸缩,非公平,非递归,在用户空间自旋(光吃不干)。看起来它似乎在所有场景里都是最坏的,例外就是,在轻微竞争的情况下,它非常快。如果你设计程序时,竞争行为在很多spin_mutex对象间传播,那还是使用别的种类的互斥体为好。如果互斥体是重度竞争的,你的算法无论如何都不会是可伸缩的。此种情况下,重新设计算法比寻找更有效的锁合适。
- queuing_mutex 可伸缩,公平,非递归,在用户控件自旋。当可伸缩与公平很重要时使用。
- spin_rw_mutex、queuing_rw_mutex 与spin_mutex、queuing_mutex类似,但是增加了读取锁支持。
- mutex与recursive_mutex 这两个互斥体是对系统原生互斥的包装。在windows系统中,是在CRITICAL_SECTION(关键代码段)上封装的。在Linux以及Mac OS 操作系统中,通过pthread的互斥体实现。封装的好处是加入了异常安全接口,并相比Intel TBB的其他互斥体提供了接口的一致性,这样当出于性能方面考虑时能方便地将其替换为别的互斥体。
- null_mutex和null_rw_mutex 这两个互斥体什么都不做。它们可被用作模版参数。例如,假定你要定义一个容器模板并且知道它的一些实例会被多个线程共享,需要内部锁定,但是其余的会被某个线程私有,不需要锁定。你可以定义一个将互斥体类型作为参数的模板。在需要锁定时,这个参数可以是真实互斥体类型中的一种,在不需要锁定时,将null_mutex作为参数传入。
互斥体的行为与特点:
读写锁
互斥在当多个线程写操作某个共享变量时是必要的。但允许多个读操作者进入保护区域就没什么大不了了。互斥体的读写变种,在类名称中以_rw_标记,通过区分读取锁与写入锁,允许多个读操作者。一个给定的互斥体,可以有多个读取锁。
scoped_lock的构造函数通过一个额外的布尔型参数来区分读取锁请求与写入锁请求。如果这个参数为false,表示请求读取锁。true表示请求写入锁。默认值为true,这样,当省略此参数时,spin_rw_mutex或者queuing_rw_mutex的行为就跟没有“_rw_”的版本一样。
升级/降级
通过方法upgrade_to_writer可以将一个读取锁升级为写入锁:
-
std:: vector< string> MyVector;
-
typedef spin_rw_mutex MyVectorMutexType;
-
MyVectorMutexType MyVectorMutex;
-
void AddKeyIfMissing(const string& key)
-
{
-
// Obtain a reader lock on MyVectorMutex
-
MyVectorMutexType:: scoped_lock
-
lock (MyVectorMutex,/*is_writer=*/false);
-
size_t n = MyVector.size();
-
for ( size_t i = 0; i<n; ++i)
-
if (MyVector[i] == key) return;
-
if (!MyVectorMutex.upgrade_to_writer())
-
// Check if key was added while lock was temporarily released
-
for ( int i = n; i<MyVector.size(); ++i)
-
if (MyVector[i] == key) return;
-
vector.push_back(key);
-
}
注意,vector在某些时候必须重新搜索。这是因为upgrade_to_writer在它升级前可能不得不临时释放锁。否则,接下来可能会发生死锁(下面会讲到)。upgrade_to_writer方法返回值为bool类型,在没有释放锁就成功升级的情况下会返回true,如果锁被临时释放了,返回false。因此,如果upgrade_to_writer返回了false,代码必须重新运行查找操作确保“key”没有被其他的线程插入。例子假定“keys”总被追加到vector的末端,而且这些键值不会被移除。由于这些假定,它不用重新搜索整个vector,而仅搜索那些最初搜索过的之外的元素。需要记住的关键点是,如果upgrade_to_writer返回了false,任何假定持有读取锁的假定都可能无效,必须重新检查。
于此相应,有个相对的方法downgrade_to_reader,但是在实际应用中,基本找不到使用它的理由。
锁异常
锁会导致性能与正确性问题。对于使用锁的新手,有些问题要避免:
死锁
当多个线程企图获得多个锁,而且它们会相互持有对方需要的锁时,死锁就会发生。更为准确地定义,当发生以下情况时死锁会发生:
-
存在线程回路
-
每个线程至少持有互斥体上的一个锁,而且在等待回路中下一个线程已经持有锁的互斥体
-
任何线程都不愿意放弃它的锁
(这就像路口的堵车,那些SB明知道走不动非要顶上去堵着别人)避免死锁的两种惯用方法是:
-
避免需要同一时间持有两把锁的情况。将大块的程序拆分为小块,每块都可以在持有一把锁的情况下完工。
-
总是以同样的顺序取锁。例如,如果你有“外部容器”与“内部容器”互斥体,需要从中获取锁,你可以总是先从“外部密室”获取。另外一个例子是在锁具有命名的情况下“以字母顺序获取锁”。或者,如果锁没有命名,就以互斥体的数字地址作为顺序获取锁。
-
使用原子操作替换锁(随后会说到原子操作)
锁护送
另外一个与锁相关的常见问题是锁护送。当操作系统打断一个持有锁的线程时,这种情况就会发生。所有其他的需要这把锁的线程都必须等待被中断的线程恢复并释放锁。公平互斥体会导致更糟糕的状况,因为,如果一个正在等待的线程被中断,所有它后面的线程都必须等待它恢复(就不单是需要它持有锁的那些线程的问题了)。
-
要最小化这种情况发生,应该尽量缩短持有锁的时间。在请求锁之前,进行任何可被预先计算的工作。
-
要避免这种情况,尽可能使用原子操作代替锁。