导入库与数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
train_set=pd.read_csv('train.csv')
test_set=pd.read_csv('test.csv')因为数据集的属性太多,不再使用head()方法进行观察。
数据清洗
目标值检验
在机器学习的大部分模型中,有一个基本假设就是噪声服从高斯分布。首先检验目标值是否服从正态分布:
plt.clf()
plt.hist(train_set.loc[:,'SalePrice'])
plt.show()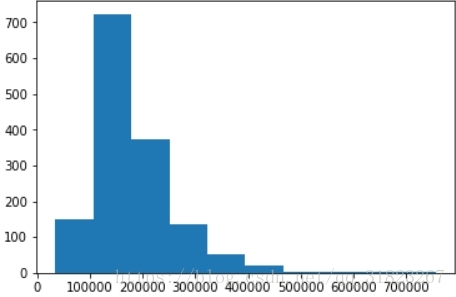
很明显的斜分布,所以先对目标值进行log1p变换:
train_set.loc[:,'SalePrice_log1p'] = np.log1p(train_set.loc[:,'SalePrice'])
plt.clf()
plt.hist(train_set.loc[:,'SalePrice_log1p'])
plt.show()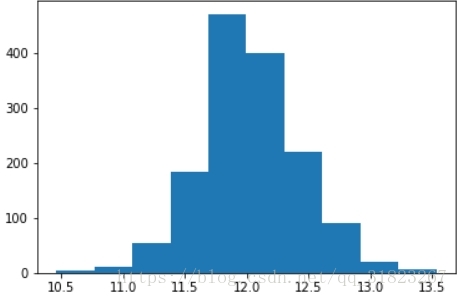
数据中特征值比较多,需要谨慎对待。通过观察,特征值的种类有这么几种:
- 无序类别型
- 有序类别型
- 无序数值型
- 有序数值型
是否有序通过是否存在不等式关系来判断。如MSZoning列的类别型只是单纯的表示类别,类别之间不可比较,属无序类别型;而LotShape虽然也是类别型,但是类别之间却有比较关系,属于有序类别型。
对于有序类别型,需要将其转换成有序数值型。但是注意转换步骤必须在填充缺失值之后才能进行。
异常值
异常值是针对训练集中的异常数据,对于异常值,选择丢弃。(也可以选择修复,比如对异常数据进行截断)
train_set.drop(['Id'],axis=1,inplace=True)mask=train_set.dtypes!='object'
num_cols=tuple(train_set.dtypes[mask].index)
fig_col=5
plt.clf()
fig,axes=plt.subplots(
int(np.ceil(len(num_cols)/fig_col)),
fig_col,
figsize=(20,20),
sharey=True)
for i,col in zip(range(len(num_cols)),num_cols):
axes[i//fig_col,i%fig_col].scatter(train_set.loc[:,col].values,train_set.loc[:,'SalePrice'].values)
axes[i//fig_col,i%fig_col].set_title(col)
plt.subplots_adjust(wspace=0.3,hspace=0.3)
plt.show()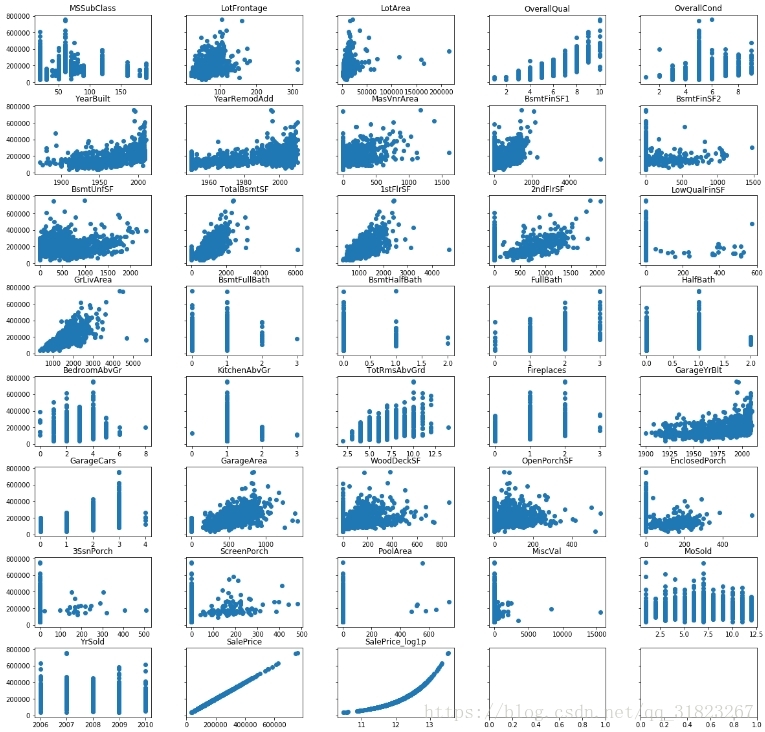
根据从图象上的观察来剔除异常值:
outliers_mask=(
(train_set.loc[:,'LotFrontage']>300)|
(train_set.loc[:,'1stFlrSF']>4000)|
((train_set.loc[:,'LowQualFinSF']>400)&(train_set.loc[:,'SalePrice']>400000))|
(train_set.loc[:,'BsmtFinSF1']>4000)|
((train_set.loc[:,'GrLivArea']>4000)&(train_set.loc[:,'SalePrice']<400000))|
(train_set.loc[:,'LotArea']>100000)|
(train_set.loc[:,'MiscVal']>10000)|
(train_set.loc[:,'TotalBsmtSF']>6000)
)
outliers_index=train_set[outliers_mask].index
train_set.drop(outliers_index,inplace=True)再次输出图像确认异常值的剔除:
fig_col=5
plt.clf()
fig,axes=plt.subplots(
int(np.ceil(len(num_cols)/fig_col)),
fig_col,
figsize=(20,20),
sharey=True)
for i,col in zip(range(len(num_cols)),num_cols):
axes[i//fig_col,i%fig_col].scatter(train_set.loc[:,col].values,train_set.loc[:,'SalePrice'].values)
axes[i//fig_col,i%fig_col].set_title(col)
plt.subplots_adjust(wspace=0.3,hspace=0.3)
plt.show()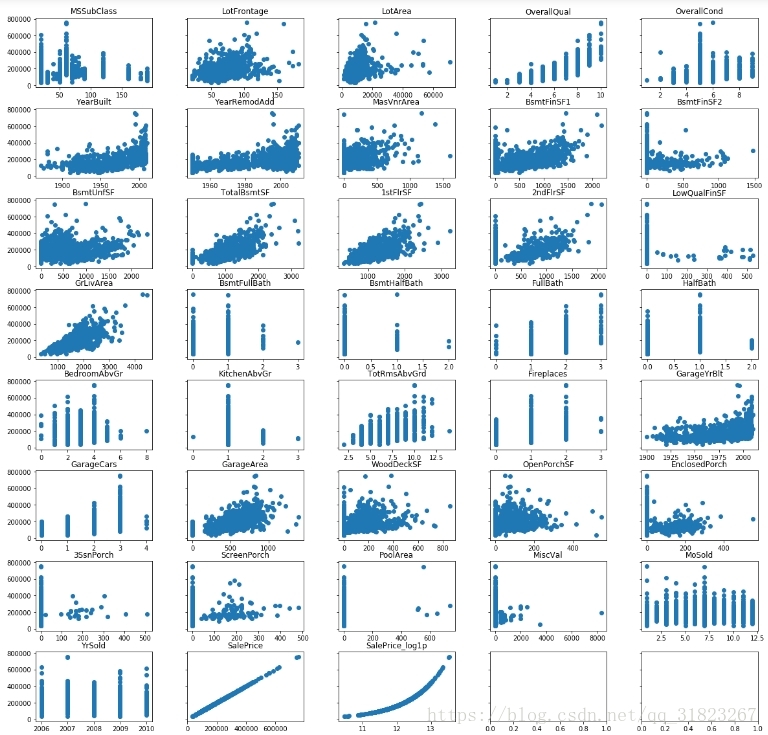
缺失值
因为训练集与测试集的大小相仿,所以在填充缺失值时最好将测试集中的数据也利用起来。(能不能用测试集的数据有待商榷)
Y_train=train_set.loc[:,'SalePrice_log1p'].values
train_set.drop(['SalePrice','SalePrice_log1p'],axis=1,inplace=True)
test_ID=test_set.loc[:,'Id']
test_set.drop(['Id'],axis=1,inplace=True)
n_train=train_set.shape[0]
n_test=test_set.shape[0]
data=pd.concat((train_set,test_set),axis=0).reset_index(drop=True) #拼接数据集以便数据清洗
# print(n_train,n_test)data.isnull().sum().sort_values(ascending=False)[:20]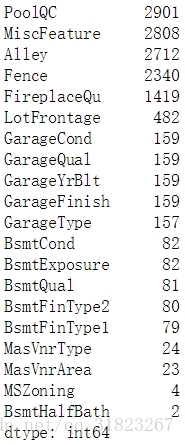
根据数据的描述文档来填充伪缺失值:
mask=data.dtypes!='object'
num_cols=tuple(data.dtypes[mask].index)
#伪缺失值
fake_missing_cols=['Alley','MasVnrType','BsmtQual','BsmtCond','BsmtExposure','BsmtFinType1',
'BsmtFinType2','FireplaceQu','GarageType','GarageFinish','GarageQual','GarageCond',
'PoolQC','Fence','MiscFeature']
for col in fake_missing_cols:
data.loc[:,col].fillna('None',inplace=True)
#数值缺失值
num_col=['LotFrontage','LotFrontage']
for col in num_cols:
median=data.loc[:,col].median()
data.loc[:,col].fillna(median,inplace=True)
#缺失值可看成0的列
zero_cols=['GarageArea','GarageCars','BsmtFinSF1','BsmtFinSF2','BsmtUnfSF','TotalBsmtSF','BsmtFullBath',
'BsmtHalfBath','MasVnrArea']
for col in zero_cols:
data.loc[:,col].fillna(0,inplace=True)
#类别型缺失值
cat_missing_cols=['MSZoning','Utilities','Functional','Electrical','KitchenQual',
'Exterior1st','Exterior2nd','SaleType','MSSubClass']
for col in cat_missing_cols:
mode=data.loc[:,col].mode()[0]
data.loc[:,col].fillna(mode,inplace=True)确认缺失值全部填充完毕:
data.isnull().sum(axis=0).sort_values(ascending=False)[0]有序类别型的编码
将有序类别型的特征转换成有序的离散数字1、2、3…
from sklearn.preprocessing import LabelEncoderorderd_cat_cols=['Street','Alley','LotShape','Utilities','LandSlope','ExterQual','ExterCond','BsmtQual',
'BsmtCond','BsmtExposure','BsmtFinType1','BsmtFinType2','HeatingQC','CentralAir','KitchenQual',
'Functional','FireplaceQu','GarageType','GarageFinish','GarageQual','GarageCond',
'PavedDrive','PoolQC','Fence']for col in orderd_cat_cols:
label = LabelEncoder()
label.fit(list(data.loc[:,col].values))
data[col] = label.transform(list(data.loc[:,col].values))fig_col=5
plt.clf()
fig,axes=plt.subplots(
int(np.ceil(len(orderd_cat_cols)/fig_col)),
fig_col,
figsize=(20,20),
sharey=True)
for i,col in zip(range(len(orderd_cat_cols)),orderd_cat_cols):
axes[i//fig_col,i%fig_col].scatter(data.loc[:n_train-1,col],Y_train)
axes[i//fig_col,i%fig_col].set_title(col)
plt.subplots_adjust(wspace=0.3,hspace=0.3)
plt.show()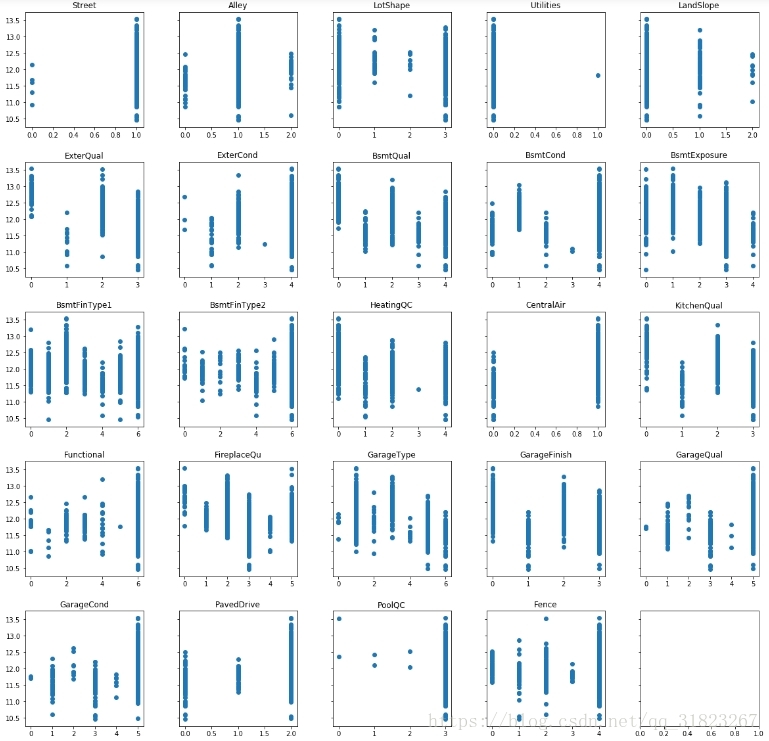
特征工程(可优化
#室内总面积
data.loc[:,'TotalSF']=data.loc[:,'TotalBsmtSF']+data.loc[:,'1stFlrSF']+data.loc[:,'2ndFlrSF']
data.drop(['TotalBsmtSF','1stFlrSF','2ndFlrSF'],axis=1,inplace=True)
data.loc[:,'TotalHalfBath']=data.loc[:,'BsmtHalfBath']+data.loc[:,'HalfBath']
data.loc[:,'TotalFullBath']=data.loc[:,'BsmtFullBath']+data.loc[:,'FullBath']
data.drop(['BsmtHalfBath','HalfBath','BsmtFullBath','FullBath'],axis=1,inplace=True)分布检验
检验数值型数据分布是否符合高斯分布,将那些分布过分倾斜的特征进行分布变换。
from scipy.stats import skew
from scipy.special import boxcox1pmask=data.dtypes!='object'
num_cols=data.dtypes[mask].index
skewed_cols = data[num_cols].apply(lambda x: skew(x)).sort_values(ascending=False)
skewed_cols.head(10)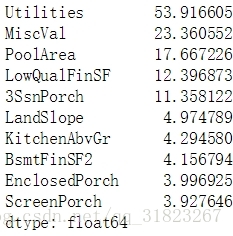
从输出可以看出Utilities这一列分布极度倾斜,看一下这一列的值:
data.loc[:,'Utilities'].value_counts()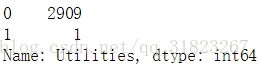
可以看出这一列基本可看作是常数列,无用,丢弃:
data.drop(['Utilities'],axis=1,inplace=True)再次查看一下数据分布的倾斜程度:
mask=data.dtypes!='object'
num_cols=data.dtypes[mask].index
skewed_cols = data[num_cols].apply(lambda x: skew(x)).sort_values(ascending=False)
skewed_cols=skewed_cols[abs(skewed_cols)>0.75].index
data[skewed_cols] = np.log1p(data[skewed_cols])
skewed_cols = data[num_cols].apply(lambda x: skew(x)).sort_values(ascending=False)
skewed_cols.head(10)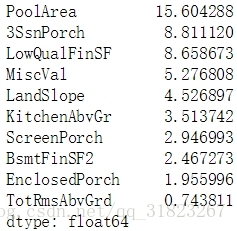
离散化与编码
将那些无序的离散数值转换成字符型,以便之后的特征编码。
注意这是回归问题,不能将特征中的连续数值进行区间切割!
data.loc[:,'MSSubClass']=data.loc[:,'MSSubClass'].astype(str)
data.loc[:,'YrSold']=data.loc[:,'YrSold'].astype(str)
data.loc[:,'MoSold']=data.loc[:,'MoSold'].astype(str)data=pd.get_dummies(data)
data.shape# data.sample(5)X_train=data.iloc[:n_train,:].values
X_test=data.iloc[n_train:,:].values机器学习模型
import xgboost as xgb
import lightgbm as lgb
from sklearn.linear_model import ElasticNet, Lasso
from sklearn.kernel_ridge import KernelRidge
from sklearn import svm,ensemble
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler根据网站上的评判标准,定义一个直接返回CV分数均值的函数:
def rmse(model):
score=np.sqrt(-cross_val_score(model,X_train,Y_train,cv=10,scoring='neg_mean_squared_error',n_jobs=-1).mean())
return score基准分数
Models=[
xgb.XGBRegressor(),
# lgb.LGBMRegressor(), #lgb与sklearn的cross_val_score有冲突
Lasso(),
ElasticNet(),
KernelRidge(),
svm.SVR(),
#Ensemble Methods
ensemble.AdaBoostRegressor(),
ensemble.BaggingRegressor(),
ensemble.RandomForestRegressor(),
ensemble.GradientBoostingRegressor()
]
columns=['Model_name','RMSE']
Model_compare=pd.DataFrame(columns=columns)
row_index=0
for Model in Models:
Model_compare.loc[row_index,'Model_name']=Model.__class__.__name__
Model_compare.loc[row_index,'RMSE']=rmse(Model)
row_index+=1
Model_compare.sort_values(by='RMSE',ascending=True)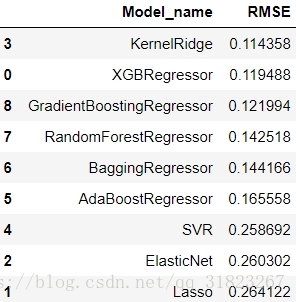
调参
此处参数参照别人的。
xgb_reg=xgb.XGBRegressor(colsample_bytree=0.4603, gamma=0.0468,
learning_rate=0.05, max_depth=3,
min_child_weight=1.7817, n_estimators=2200,
reg_alpha=0.4640, reg_lambda=0.8571,
subsample=0.5213, silent=1,
random_state =7, nthread = -1)
print(rmse(xgb_reg))0.11528566980058698
ela_reg=ElasticNet(alpha=0.0005, l1_ratio=.9, random_state=3)
print(rmse(ela_reg))0.11003984963258855
knr_reg=KernelRidge()
print(rmse(knr_reg))0.11435779064268664
las_reg=Lasso(alpha =0.0005, random_state=1)
print(rmse(las_reg))0.11023323390309617
gdb_reg=ensemble.GradientBoostingRegressor(n_estimators=3000, learning_rate=0.05,
max_depth=4, max_features='sqrt',
min_samples_leaf=15, min_samples_split=10,
loss='huber', random_state =5)
print(rmse(gdb_reg))0.11516414977792105
融合
(待补充)
制作提交结果
las_reg.fit(X_train,Y_train)
xgb_reg.fit(X_train,Y_train)
ela_reg.fit(X_train,Y_train)
Y_test_las=np.expm1(las_reg.predict(X_test))
Y_test_xgb=np.expm1(xgb_reg.predict(X_test))
Y_test_ela=np.expm1(ela_reg.predict(X_test))
Y_test=0.45*Y_test_las + 0.25*Y_test_xgb+0.30*Y_test_elasub = pd.DataFrame()
sub['Id'] = test_ID
sub['SalePrice'] = Y_test
sub.to_csv('submission.csv',index=False)提交后LB分数为0.1143。