针对集合问题,统一整理如下:(以后统一补充到此文档中) 最后一次更新(2018/07/06 09:21)
Java.util.Collection是一个集合接口,提供了对集合对象进行基本操作的通用接口方法,Collection接口的意义是为各种具体的集合提供最大化的统一操作方式。
Java.util.Collections是一个包装类,包括有各种有关集合操作的静态方法,不能实例化,就是一个工具类,服务于Java的Collection框架。 Collections类提供了sychronizedXxx()方法,可以将指定集合包装成线程安全的集合。
比如:List list = Collections.synchronizedList(new ArrayList());
Set set = Collections.synchronizedSet(new HashSet());
1. Collection的继承实现关系:
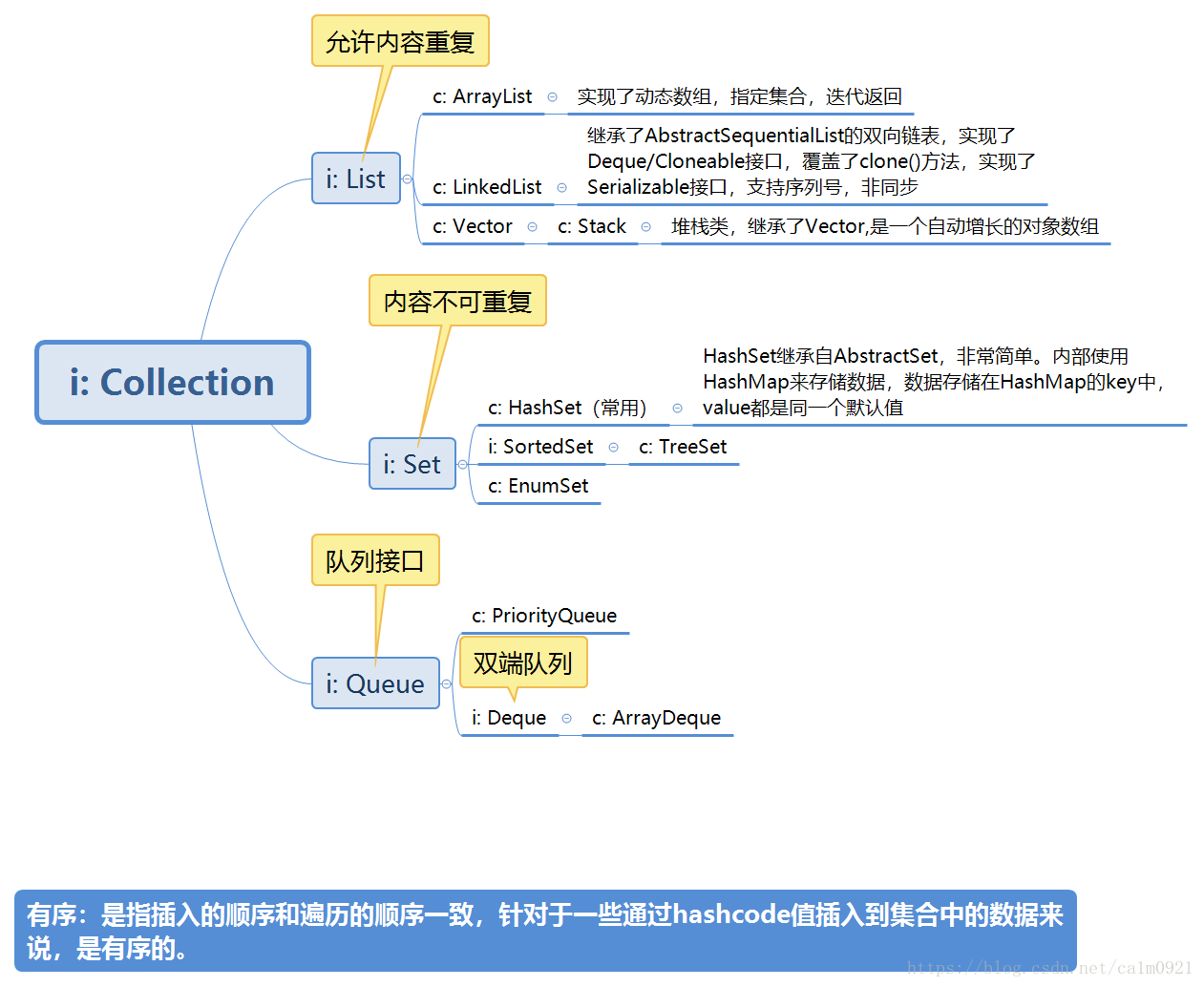
1.1 关于Collection的一些补充:
1. ArrayList
实现了List接口,内部实现是通过数组完成的,其本质是一个顺序存储的线性表。
插入和删除都会影响其他元素的位置,下标改变(循环输出或迭代时注意),效率低。但随机访问效率高。
默认初始化容量为10,当超过数组大小就创建一个新的数组,扩容为1.5倍+1扩容。10-->16
有三个构造函数。
Arraylist()构造一个初始化容量为10的空列表。
Arraylist(Collection<? extends E> c)构造一个包含指定collection元素的列表,按迭代器返回它们的顺序。
Arraylist(int initialCapacity)构造一个指定容量列表的空列表。
其他方法:
常用Iterator中的方法:
hasNext()、next()、
remove()方法调用的是remove(int index);而不是remove(Object o); 因此通过索引删除元素。
ArrayList中的迭代器使用:
public static void main(String[] args){
List<String> list=new ArrayList<>();
list.add("abc");
list.add("edf");
list.add("ghi");
for(Iterator<String> it=list.iterator();it.hasNext();){
System.out.println(it.next());
}
}迭代器的实现原理:
在ArrayList内部定义了一个内部类Itr,该类实现了Iterator接口。
在Itr中,有三个变量分别是
cursor:表示下一个元素的索引位置 (hasNext判断 cursor是不是等于size)
lastRet:表示上一个元素的索引位置 (用来返回当前元素)
expectModCount:预期被修改的次数 (在ArrayList中存在一个modCount记录集合的修改次数,在Iterator中也存在一个expectModCount用来记录集合的修改次数,当在Iterator的遍历中,有线程修改了集合,modCount会+1,此时两者不相等,抛出java.util.ConcurrentModificationException异常)。
Iterator只支持在遍历的时候,删除元素,如果要在遍历时,添加元素,该怎么办呢?
这时就引出了ListIterator,可以用于在遍历的过程中,修改元素,正反遍历,返回当前位置。(添加元素通过当前元素比较)
2. LinkedKist
实现了List接口,内存结构是双向链表存储。
链式存储结构的插入和删除效率高,不影响其他元素的位置,但是随机访问效率低。需要从头依次访问。
没有扩容机制,随意在链表头或尾部插入和删除
3. Vector
在内存中占用连续的空间,默认初始化容量为10,扩容为1倍扩容。
比ArrayList多了同步机制,效率较低,线程安全。
如果Vector定义为Object类型,则可以存放任意类型,该集合已弃用。
Blocking queue:(在多线程领域:所谓阻塞,在某些情况下会挂起线程(即阻塞),一旦条件满足,被挂起的线程又会自动被唤醒)
4. ArrayBlockingQueue
基于数组实现的阻塞队列,内部维护一个定长数组。
还维护两个整型数据:队列头和队列尾在数组中的位置。
5. LinkedBlockingQueue
基于链接节点的可选限定的blocking queue(先进先出),如果没有在初始化时,指定大小,默认为无限大。
头部最长,尾部最短,链接队列通常具有 比 基于阵列的队列更高的吞吐量,但在并发应用程序中可预测性能较低。
ArrayBlockingQueue 和 LinkedBlockingQueue 的区别: (以 生产者 和 消费者为例分析)
前者队列头和队列尾 维护同一个锁,后者使用了分离锁。
前者在添加和删除操作时,不产生或销毁任何的对象实例,后者会生成一个额外的 Node对象。高并发大批量数据处理中,影响gc,内存容易爆满。
6. PriorityQueue:
基于优先级堆的无限优先级queue。
优先级队列的元素根据它们的有序natural ordering或由一个Comparator在队列构造的时候提供,取决于使用的构造方法。
优先级队列不允许null元素,自然排序的优先级队列也不允许插入不可比较的对象(可能导致ClassCastException)。此实现不同步,多线程不应同时访问PriorityQueue实例,而应该使用PriorityBlockingQueue类(线程安全)。
6. ConcurrentLinkedQueue:
基于链接节点的无界并发deque(deque是双端队列),并发插入。
删除和访问可以跨多个线程安全执行,不允许null元素。
7. AbstractSet类实现了set接口,HashSet继承AbstractSet类,同时实现set接口。
8. stack堆栈类,继承了vector,vector继承了ArrayList,重写了其方法,所以是线程安全的
9. enumeration 枚举,相当于迭代器
---------------------------------------------------------------------------------------------------------------------------------
2. Map的继承实现关系:
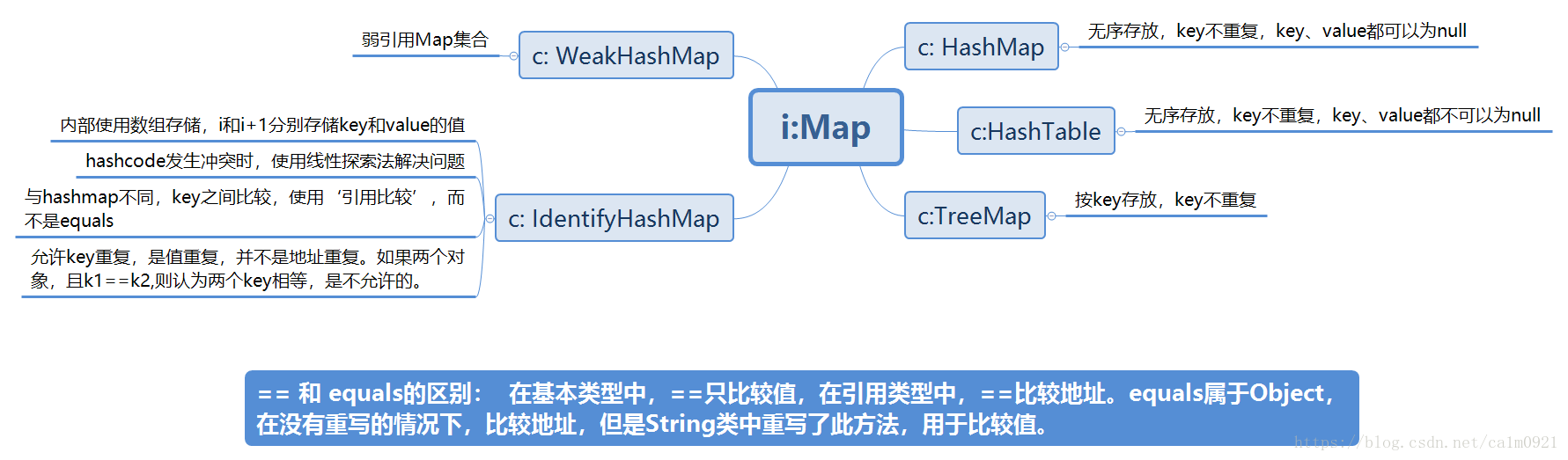
2.1 关于Map的一些补充:
1. HashMap
默认初始化容量为16,扩容为2倍+1。(初始化大小是 16 ,扩容因子默认0.75(可以指定初始化大小,和扩容因子))
未进行同步考虑,是线程不安全的。
key、value都可以为null,判断key=null;的键是否存在,应该用containsKey方法,并不能用get方法。因为get返回null,即可表示
null键存在也可表示此键不存在。存储的key重新计算hash值(+salt?)。
2. HashTable
默认初始化容量为11,扩容为2倍。
比hashmap多了同步机制,是线程安全的,对整张哈希表加锁。
在多线程中使用put方法时,对于其他线程连get方法都不能用。所以效率低。
key、value都不可为null,存储的key为对象的hashcode,已弃用。
HashTable 和 HashMap的区别:
1) 继承不同
HashTable : public class HashTable extends Dictionary implements Map
HashMap: public class HashMap extends AbstractMap implements Map
2) 同步问题
HashTable 中方法是同步的,而HashMap中方法在缺省的情况下是不同步的,需要自己添加同步。用sychronizedHashMap
3) null 的问题:
HashTable中,key、value都不允许出现null值,
HashMap中,null可以作为键,这样的键只有一个,可以有多个value=null,需要自己增加同步。
4) 遍历方式不同:
HashTable、HashMap都使用了Iterator,而由于历史原因,HashTable还使用了Enumeration的方式,
5) 哈希值不同:
HashTable直接使用对象的hashcode,而HashMap重新计算hash值。
6) 初始化和扩容:
HashTable和HashMap内部实现都是数组初始化大小和扩容方式。
HashTable的Hash数组默认为11,扩容为old*2+1;
HashMap的hash数组默认值为16,而且一定是2的指数扩容。
3. concurrentHashMap
提供一组和HashMap功能相同但线程安全的方法。
将Hash表分为16桶(segment),每次只对需要的桶加锁。
在JDK1.8之后,可以做到读取不加锁,其内部结构可以在写操作时将锁粒度尽量的小,锁区变小。
ConcurrentHashMap并不再是分段锁,而是更细粒度的锁,只是在修改map时对链表头加锁。(红黑树根)
4.HashSet
内部使用Map保存数据,即HashSet对象的hashcode做key。
因为set中不允许相同对象出现,所以添加对象需要比较两次,hashcode、equals,一次比较hashcode是否存在,一次比较equals,也就是对象时否存在,因为,hashcode的计算方法并不能保证唯一性,可能通过权重、或其他方法计算,并不能保证唯一性,所以存储时需要检验。
重点:HashMap为什么线程不安全:
HashMap在并发时可能出现的问题主要是两方面:
①首先如果多个线程同时使用put方法添加元素,而且假设正好存在两个put的key发生了碰撞(hash值一样),那么根据HashMap的实现,这两个key会添加到数组的同一个位置,这样最终就会发生其中一个线程的put的数据被覆盖。
②如果多个线程同时检测到元素个数超过数组大小*loadFactor,这样就会发生多个线程同时对Node数组进行扩容,都在重新计算元素位置以及复制数据,但是最终只有一个线程扩容后的数组会赋给table,也就是说其他线程的都会丢失,并且各自线程put的数据也丢失。
关于HashMap线程不安全这一点,《Java并发编程的艺术》一书中是这样说的:HashMap在并发执行put操作时会引起死循环,导致CPU利用率接近100%。因为多线程会导致HashMap的Node链表形成环形数据结构,一旦形成环形数据结构,Node的next节点永远不为空,就会在获取Node时产生死循环。(rehash可能导致环形数据结构)
我们可以采用三个方法解决:使用HashTable、使用sychronized修饰方法、使用concurrentHashMap。
多线程访问中如果使用迭代器过程中,有其他线程修改了集合对象结构,会触发快速失败机制(Fail-Fast),可能会抛出ConcurrentModificationException,所谓快速失败机制。所以 在迭代器创建之后,如果从结构上对映射进行修改,除非使用迭代器本身的remove方法。