现在有一种类似树的数据结构,但是不存在共同的根节点 root,每一个节点的结构为 {key: 'one', value: '1', children: [...]},都包含 key 和 value,如果存在 children 则内部会存在 n 个和此结构相同的节点,现模拟数据如下图:

已知一个 value 如 3-2-1,需要取出该路径上的所有 key,即期望得到 ['three', 'three-two', 'three-two-one']。
1.广度优先遍历
广度优先的算法如下图:
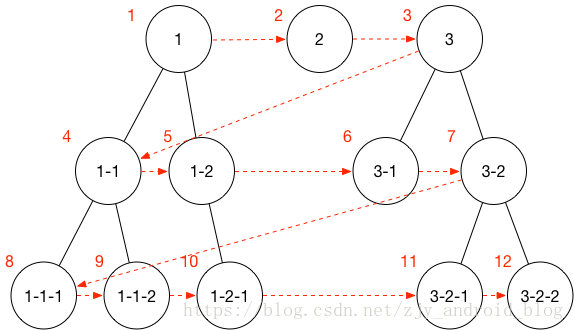
首先需要把外层的数据结构放入一个待搜索的队列(Queue)中,进而对这个队列进行遍历,当正在遍历的节点存在子节点(children)时则把此子节点下所有节点放入待搜索队列的末端。
因为本需求需要记录路径,因此还需要对这些数据做一些特殊处理,此处采用了为这些节点增加 parent 即来源的方法。
对此队列依次搜索直至找到目标节点时,可通过深度遍历此节点的 parent 从而获得到整个目标路径。具体代码如下:
// 广度优先遍历
function findPathBFS(source, goal) {
// 深拷贝原始数据
var dataSource = JSON.parse(JSON.stringify(source))
var res = []
// 每一层的数据都 push 进 res
res.push(...dataSource)
// res 动态增加长度
for (var i = 0; i < res.length; i++) {
var curData = res[i]
// 匹配成功
if (curData.value === goal) {
var result = []
// 返回当前对象及其父节点所组成的结果
return (function findParent(data) {
result.unshift(data.key)
if (data.parent) return findParent(data.parent)
return result
})(curData)
}
// 如果有 children 则 push 进 res 中待搜索
if (curData.children) {
res.push(...curData.children.map(d => {
// 在每一个数据中增加 parent,为了记录路径使用
d.parent = curData
return d
}))
}
}
// 没有搜索到结果,默认返回空数组
return []
}2.深度优先遍历
深度优先的算法如下图: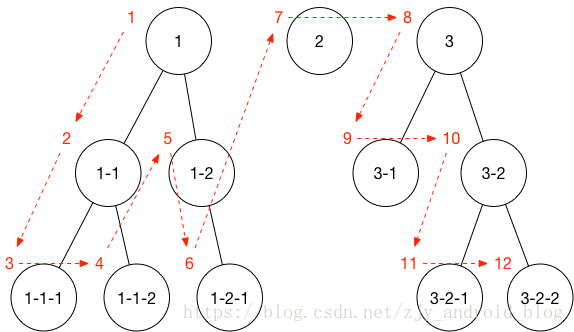
深度优先即是取得要遍历的节点时如果发现有子节点(children) 时,则不断的深度遍历,并把这些节点放入一个待搜索的栈(Stack)中,直到最后一个没有子节点的节点时,开始对栈进行搜索。后进先出(下列代码中使用了 push 方法入栈,因此需使用 pop 方法出栈),如果没有匹配到,则删掉此节点,同时删掉父节点中的自身,不断重复遍历直到匹配为止。注意,常规的深度优先并不会破坏原始数据结构,而是采用 isVisited 或者颜色标记法进行表示,原理相同,此处简单粗暴做了删除处理。代码如下:
// 深度优先遍历
function findPathDFS(source, goal) {
// 把所有资源放到一个树的节点下,因为会改变原数据,因此做深拷贝处理
var dataSource = [{children: JSON.parse(JSON.stringify(source))}]
var res = []
return (function dfs(data) {
if (!data.length) return res
res.push(data[0])
// 深度搜索一条数据,存取在数组 res 中
if (data[0].children) return dfs(data[0].children)
// 匹配成功
if (res[res.length - 1].value === goal) {
// 删除自己添加树的根节点
res.shift()
return res.map(r => r.key)
}
// 匹配失败则删掉当前比对的节点
res.pop()
// 没有匹配到任何值则 return
if (!res.length) return res
// 取得最后一个节点,待做再次匹配
var lastNode = res[res.length - 1]
// 删除已经匹配失败的节点(即为上面 res.pop() 的内容)
lastNode.children.shift()
// 没有 children 时
if (!lastNode.children.length) {
// 删除空 children,且此时需要深度搜索的为 res 的最后一个值
delete lastNode.children
return dfs([res.pop()])
}
return dfs(lastNode.children)
})(dataSource)
}该方法在思考时,添加了根节点以把数据转换成树,并在做深度遍历时传入了子节点数组 children 作为参数,其实多有不便,于是优化后的代码如下:
// 优化后的深度搜索
function findPathDFS(source, goal) {
// 因为会改变原数据,因此做深拷贝处理
var dataSource = JSON.parse(JSON.stringify(source))
var res = []
return (function dfs(data) {
res.push(data)
// 深度搜索一条数据,存取在数组 res 中
if (data.children) return dfs(data.children[0])
// 匹配成功
if (res[res.length - 1].value === goal) {
return res.map(r => r.key)
}
// 匹配失败则删掉当前比对的节点
res.pop()
// 没有匹配到任何值则 return,如果源数据有值则再次深度搜索
if (!res.length) return !!dataSource.length ? dfs(dataSource.shift()) : res
// 取得最后一个节点,待做再次匹配
var lastNode = res[res.length - 1]
// 删除已经匹配失败的节点(即为上面 res.pop() 的内容)
lastNode.children.shift()
// 没有 children 时
if (!lastNode.children.length) {
// 删除空 children,且此时需要深度搜索的为 res 的最后一个值
delete lastNode.children
return dfs(res.pop())
}
return dfs(lastNode.children[0])
})(dataSource.shift())
}改进后的方法只关心传入的节点,如果存在子节点则内部自行处理,而非预先传入所有子节点数组进行处理,此方法更易理解一些。
结语
以上便是广度与深度遍历在 JS 中的应用,代码可在 codepen 中查看。
本文转载自:https://zhaoshibo.net/blog/2017/05/09/JS%20%E4%B8%AD%E7%9A%84%E5%B9%BF%E5%BA%A6%E4%B8%8E%E6%B7%B1%E5%BA%A6%E4%BC%98%E5%85%88%E9%81%8D%E5%8E%86/
如果有侵犯到谁的权益请在评论中给我留言,本人会删除转载的文章,谢谢!