应用的知识
最优分段
主成分分析
贝叶斯网络
套袋算法
spearman相关系数
数据重命名、连接、聚合等等处理
code
#加载所需的包
library(data.table)
library(dplyr)
library(psych)
library(caret)
library(smbinning)
#设置工作路径
setwd('D:\\R\\wokingdiretory\\work\\4_29')
#读取数据
ST2015 <- read.csv('xx.csv', sep = "",fileEncoding = 'utf-8')
ST2016 <- read.csv('xxx.csv', sep = ",",fileEncoding = 'utf-8')
ZC2015 <- read.csv('xxxx.csv', sep = ",",fileEncoding = 'utf-8')
ZC2016 <- read.csv('xxxxx.csv', sep = ",",fileEncoding = 'utf-8')
head(ST2015);dim(ST2015);str(ST2015)
head(ST2016);dim(ST2016);str(ST2016)
head(ZC2015);dim(ZC2015);str(ZC2015)
head(ZC2016);dim(ZC2016);str(ZC2016)
###################################数据整合###################################
ST2015 <- as.data.table(ST2015)
ST2016 <- as.data.table(ST2016)
ZC2015 <- as.data.table(ZC2015)
ZC2016 <- as.data.table(ZC2016)
ST2015 <- ST2015[,ClassName :='ST']
ZC2015 <- ZC2015[,ClassName :='ZC']
ST2016 <- ST2016[,ClassName :='ST']
ZC2016 <- ZC2016[,ClassName :='ZC']
dt_2015 <- rbind(ST2015,ZC2015)
dt_2016 <- rbind(ST2016,ZC2016)
data <- rbind(dt_2015,dt_2016)
total_name <- names(data)
split_name <- unlist(strsplit(names(data), "_"))
dis_list <- seq(1,length(split_name),2)
names(data)<- c(split_name[-dis_list],'ClassName')
data <- as.data.frame(data)
for (i in 4:(ncol(data)-1)) {
data[,i] <- as.numeric(data[,i])
}
str(data)
# 遍历计算data的缺失百分比
num_na <- c()
for (i in 1:ncol(data)) {
num_na[i] <- sum(is.na(data[,i]))/nrow(data)*100
}
xuhao <- which(num_na>25)
names(data)[xuhao]
data <- data[,-xuhao]
dim(data)
################################ spearman相关系数检验
data$ClassName[which(data$ClassName=="ZC")] <- 1
data$ClassName[which(data$ClassName=="ST")] <- 0
data$ClassName <- as.numeric(data$ClassName)
spear_result <- corr.test(data[4:(ncol(data)-1)], data[ncol(data)], method = "spearman")
spear_result $r
spear_result $p
save_var_list <- which(abs(spear_result$r)>0.1)
temp_dt_r <- (spear_result$r)[save_var_list,]
temp_dt_p <- (spear_result$p)[save_var_list,]
temp_dt_r <- as.data.frame(temp_dt_r)
temp_dt_p <- as.data.frame(temp_dt_p)
temp_dt <- data.frame(temp_dt_r,temp_dt_p)
temp_name <- row.names(temp_dt)
temp_dt <- data.frame(temp_name,temp_dt)
names(temp_dt) <- c('var_name','r','p')
order_result <- arrange(temp_dt, desc(r))
temp_dt_result <- filter(order_result,p<0.05)
model_dt <- data[c('Enddt',as.character(temp_dt_result[,'var_name']),'ClassName')]
dim(model_dt)
head(model_dt)
for (i in 2:(ncol(model_dt)-1)) {
model_dt[,i] <- as.numeric(model_dt[,i])
}
str(model_dt)
#set.seed(1230)
#preproc <- preProcess(model_dt[,-c(1,ncol(model_dt))],method="bagImpute")
#data1 <- predict(preproc,model_dt[,-c(1,ncol(model_dt))])
#data1$ClassName <- model_dt[,ncol(model_dt)]
#data1$Date <- model_dt[,1]
#model_dt <- data1
#write.csv(data1,'model_dt.csv',fileEncoding = 'utf-8')
model_dt <- read.csv('model_dt.csv',encoding = 'utf-8')
head(model_dt)
names(model_dt)
model_dt <- model_dt[,-1]
#######################################变量组合(主成分分析)################################################
################### 主成分分析
cor(model_dt[,-c(16,17)])
KMO(cor(model_dt[,-c(9,12,16,17)]))
# (PC1= 0.39*Retearassrt + 0.50*Totprfcostrt + 0.55*Mopeprfrt)
xlnl_num_factors <- fa.parallel(model_dt[,c(1,8,13)],fa='pc',n.iter = 100,show.legend = FALSE,
main = "Scree plot with parallel analysis")
xlnl_pca <- principal(model_dt[,c(1,8,13)],nfactors = 1,rotate = "varimax")
round(unclass(xlnl_pca$weights),2)
# (PCA = 0.6911728*EPSgrrt + 0.6911728*Totassrat)
chengznl_num_factors <- fa.parallel(model_dt[,c(10,14)],fa='pc',n.iter = 100,show.legend = FALSE,
main = "Scree plot with parallel analysis")
chengznl_pca <- principal(model_dt[,c(10,14)],nfactors = 1,rotate = "varimax")
round(unclass(chengznl_pca$weights),8)
# PC1 = 0.340575*Qckrt +0.340567*Cascurrt +0.082665*Dbgr + 0.275111*Wrkcapassrt -0.243764*Dbassrt
changznl_num_factors <- fa.parallel(model_dt[,c(2,4,5,11,15)],fa='pc',n.iter = 100,show.legend = FALSE,
main = "Scree plot with parallel analysis")
changznl_pca <- principal(model_dt[,c(2,4,5,11,15)],nfactors = 2,rotate = "varimax")
round(unclass(changznl_pca$weights),6)
# (PC1 = 0.687828*ARTrat + 0.687828*Invtrtrrat)
zcglnl_num_factors <- fa.parallel(model_dt[,c(3,6)],fa='pc',n.iter = 100,show.legend = FALSE,
main = "Scree plot with parallel analysis")
zcglnl_pca <- principal(model_dt[,c(3,6)],nfactors = 1,rotate = "varimax")
round(unclass(zcglnl_pca$weights),6)
###########各个综合指标值计算
profitability_index <- 0.39*model_dt$Retearassrt + 0.50*model_dt$Totprfcostrt + 0.55*model_dt$Mopeprfrt
growth_capability_index <- 0.6911728*model_dt$EPSgrrt + 0.6911728*model_dt$Totassrat
debt_solvency_index <- 0.340575*model_dt$Qckrt +0.340567*model_dt$Cascurrt +0.082665*model_dt$Dbgr +
0.275111*model_dt$Wrkcapassrt -0.243764*model_dt$Dbassrt
asset_management_capability_index <- 0.687828*model_dt$ARTrat + 0.687828*model_dt$Invtrtrrat
cash_flow_level_index <- model_dt$OpeCPS
modify_model_dt <- data.frame(Profitability=profitability_index,
Growth_capability=growth_capability_index,
Debt_solvency=debt_solvency_index,
Asset_management_capability=asset_management_capability_index,
Cash_flow_level=cash_flow_level_index,
Date=model_dt$Date,ClassName=model_dt$ClassName)
dim(modify_model_dt)
str(modify_model_dt)
library(smbinning)
n_rows <- ncol(modify_model_dt)
Names <- names(modify_model_dt)[-c(n_rows-1,n_rows)]
Names
for (i in 1:(ncol(modify_model_dt)-2)) {
modify_model_dt[,i] <- as.numeric(modify_model_dt[,i])
}
str(modify_model_dt)
summary(modify_model_dt)
# 最优分段
for (Name in Names) {
index <- duplicated(modify_model_dt[c(Name)])
assign(Name,smbinning(df=unique(filter(modify_model_dt[-which(index),c(Name,'ClassName')],eval(parse(text = paste0(Name,'<100'))))),
y="ClassName",x=Name,p=0.05))
}
summary(modify_model_dt$Profitability)
Profitability <- smbinning(df=filter(modify_model_dt,Profitability<10 ),y="ClassName",x='Profitability',p=0.05)
summary(modify_model_dt$Debt_solvency)
Debt_solvency <- smbinning(df=filter(modify_model_dt,Debt_solvency<5329938277 ),y="ClassName",x='Debt_solvency',p=0.05)
summary(modify_model_dt$Asset_management_capability)
Asset_management_capability <- smbinning(df=filter(modify_model_dt,Asset_management_capability<30),
y="ClassName",x='Asset_management_capability',p=0.05)
Profitability$ctree
Growth_capability$ctree
Debt_solvency$ctree
Asset_management_capability$ctree
Cash_flow_level$ctree
# 根据数据的分组将原始数据进行离散化赋值
# 1、Profitability
summary(modify_model_dt$Profitability)
Profitability$ctree
modify_model_dt$Profitability <- ifelse(modify_model_dt$Profitability <= -0.07826,c("(-4.6756,-0.07826]"), c("[-0.07826,1.8448)"))
# 2、Growth_capability
summary(modify_model_dt$Growth_capability)
Growth_capability$ctree
modify_model_dt$Growth_capability <- ifelse(modify_model_dt$Growth_capability <= -0.36902,c("(-17.0318,-0.36902]"),
ifelse(modify_model_dt$Growth_capability <= 0.84242,c("(-0.36902,0.84242]"), c("(-0.84242,102.8643]")))
# 3、Debt_solvency
summary(modify_model_dt$Debt_solvency)
Debt_solvency$ctree
modify_model_dt$Debt_solvency <- ifelse(modify_model_dt$Debt_solvency <= 1.0049,c("(-868515548,1.0049]"),
ifelse(modify_model_dt$Debt_solvency <= 131149421.3953,c("(1.0049,131149421.3953]"), c("(131149421.3953,5329938277]")))
# 4、Asset_management_capability
summary(modify_model_dt$Asset_management_capability)
Asset_management_capability$ctree
modify_model_dt$Asset_management_capability <- ifelse(modify_model_dt$Asset_management_capability <= 2.1183,c("(-10.55 ,2.1183]"), c("[2.1183,42392.45)"))
# 5、Cash_flow_level
summary(modify_model_dt$Cash_flow_level)
Cash_flow_level$ctree
modify_model_dt$Cash_flow_level <- ifelse(modify_model_dt$Cash_flow_level <= -0.3757,c("(-0.3757,1.0049]"),
ifelse(modify_model_dt$Cash_flow_level <= -0.1337,c("(-0.3757,-0.1337]"), c("(-0.1337,8.15480]")))
str(modify_model_dt)
for (k in 1:(ncol(modify_model_dt)-2)) {
modify_model_dt[,k] <- as.factor(modify_model_dt[,k])
}
str(modify_model_dt)
modify_model_dt$Date <- as.Date(modify_model_dt$Date)
modify_model_dt$ClassName <- as.factor(modify_model_dt$ClassName)
###############################################构建贝叶斯网络模型###########################################
library(caret)
model_dt_2015 <- filter(modify_model_dt,Date< '2016-01-01')
model_dt_2016 <- filter(modify_model_dt,Date>='2016-01-01')
# 删除Date一列
model_dt_2015 <- model_dt_2015[,-c(ncol(model_dt_2015)-1)]
model_dt_2016 <- model_dt_2016[,-c(ncol(model_dt_2016)-1)]
set.seed(123012)
test_number <-createDataPartition(y=model_dt_2016$ClassName,p=0.40,list=FALSE) # 测试数据序号
train_temp <- model_dt_2016[-test_number, ] #训练数据集
test <- model_dt_2016[test_number, ] #测试集
train <- rbind(train_temp,model_dt_2015)
#####################################################
#################################利用训练集训练模型
library(bnlearn)
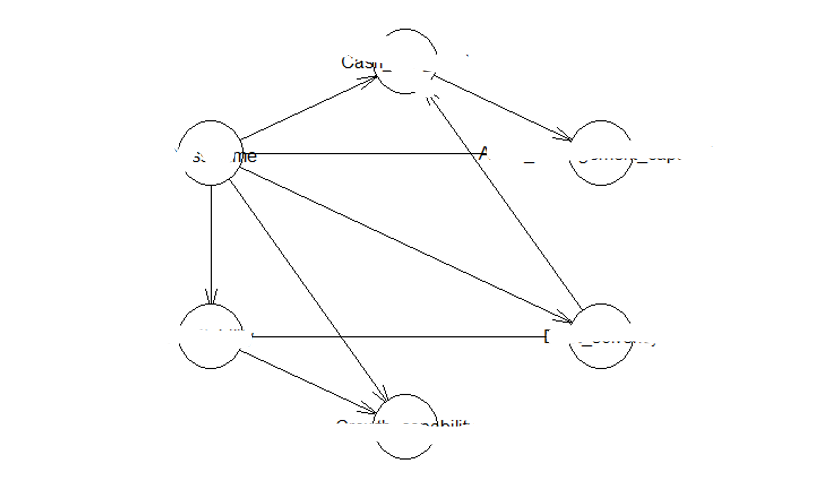
tan_train <- tree.bayes(train,"ClassName")
plot(tan_train)
modelstring(tan_train)
fit_result_train <- bn.fit(tan_train,train,method = "bayes")
fit_result_train
predict_train_train <- predict(fit_result_train,train)
temp_result_train <- table(predict_train_train,train[,"ClassName"])
# 正确率(97.42063%)
accuracy_rate_train <- ((temp_result_train[1,1]+temp_result_train[2,2])/sum(temp_result_train))*100
################################################
#################################预测2016年
predict_train_2016 <- predict(fit_result_train,test)
temp_result_2016 <- table(predict_train_2016,test[,"ClassName"])
# 正确率(96.8254%)
accuracy_rate_2016 <- ((temp_result_2016[1,1]+temp_result_2016[2,2])/sum(temp_result_2016))*100
结果
在训练样本中该模型总体的预测正确率达到了97.42063%, 测试样本中总体的预测正确率为96.8254%