Kafka Indexing Service开发的目的是为了增强Kafka中数据的实时摄入。其特性如下:
- 保障数据摄入的Exactly Once。
- 可以摄入任意时间戳的数据,而不仅仅是当前数据。
- 可以根据Kafka分区的变化二调整任务的数量。
影响数据摄入Exactly Once的主要因素是Kafka的Offset管理。Kafka Indexing Service为了实现Exactly Once语义,去掉了windowPeriod,并采用底层API实现了对Offset的事务管理。
Kafka Indexing Service的类图如下:
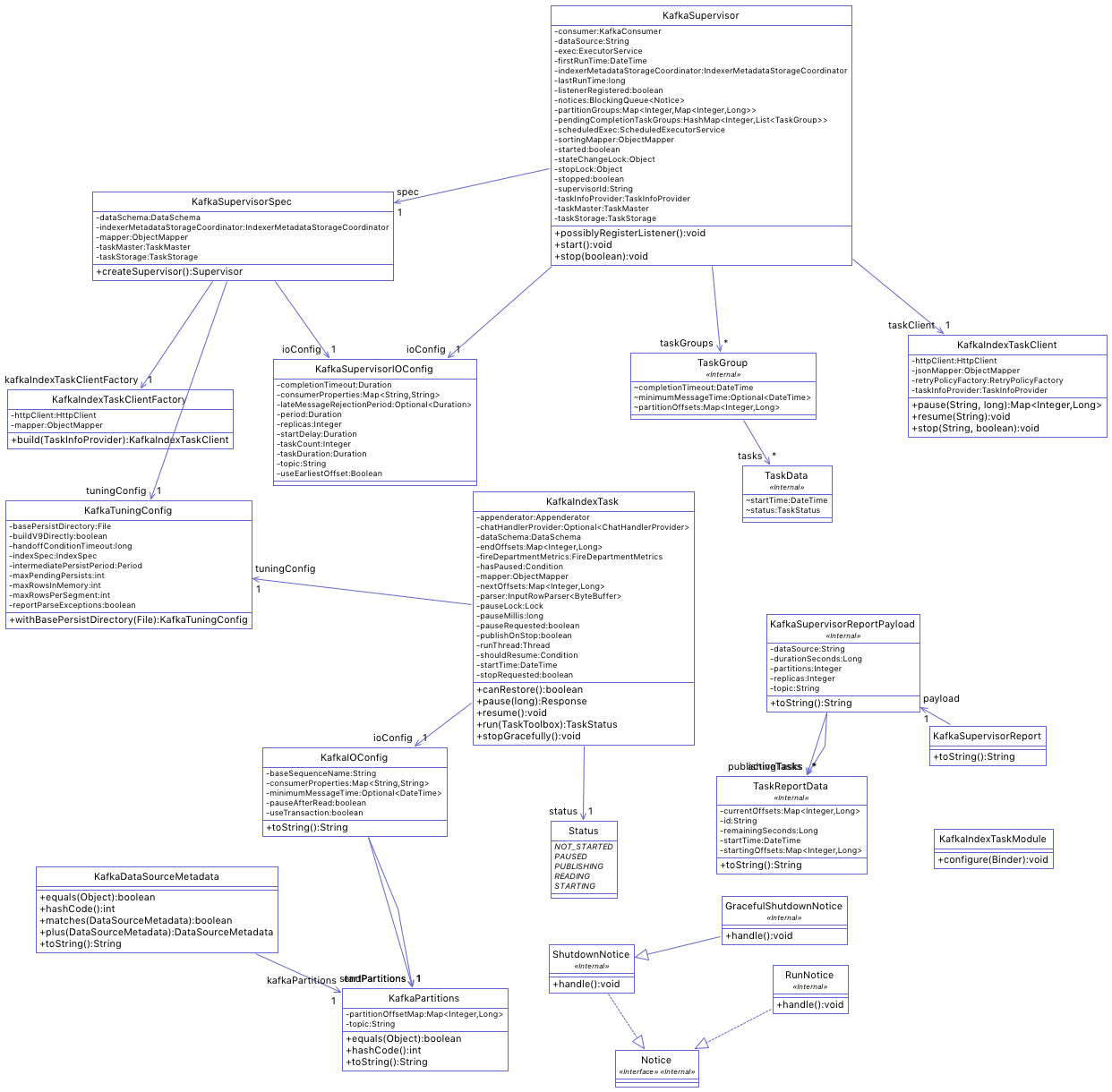
其中:
KafkaSupervisor
负责整个Kafka Indexing Service的创建以及其整个生命周期的管理,它监管Kafka Indexing Service的状态来完成协调移交,管理失败,同时保障添加/删除Kafka 分区以后的可扩展性以及任务的多副本执行。
TaskGroups
是KafkaSupervisor管理partition,Offset和Indexing service的数据结构,用来保障任务的多副本执行。每个TaskGroups中的所有任务做的都是相同的事情。读取分配给TaskGroups的所有partition的数据,而且都是从相同的Offset开始读取。通过修改replicas的值来调整任务副本数量。
KafkaIndexTask
从KafkaIOConfig的startPosition中的offset处开始读取数据,一直到endPartition的结束Offset处结束读取,发布移交segment。在执行过程中,startPosition中的Offset不会变,endPosition的Offset初始设置为: Long.MAX_VALUE。KafkaSupervisor通过修改endPosition的值来结束任务的执行。运行中的任务有两种状态:读取和发布。任务会保持读取状态,直到达到taskDuration以后进入发布状态。接下来会保持发布状态,直到生成segment,并推送至Deep Storage,然后His节点加载。或者达到completionTimeout的时间。
Appenderator
用来索引数据,采用LSM-Tree结构。这个模块负责索引和查询数据,并将Segment推送到Deep Storage中,他只将Segment信息发布到元数据存储中。
FiniteAppendratorDriver
驱动Appendrator完成有限流式数据的索引,在索引结束后执行移交操作。它完成Appenderator不能做的那些事情,包括SegmentAllocator将数据分配到指定的Segment,监控移交等。
Kafka Indexing Service利用Kafka的底层Consumer接口,从传入startOffsets Map{partition, startOffset} 处读取数据,使用FiniteAppendratorDriver构建Segment。FiniteAppendratorDriver采用有限流失数据的处理方式,读取固定时间段的数据。
FiniteAppendratorDriver会带来副作用,会产生一些碎片化的Segment,特别是日志跨时段乱序延迟严重的情况。
如何使用?
将该Extension添加到Overlord和MiddleManager中:
druid.extensions.loadList=["other-modules", "kafka-indexing-service"]
通过 http://<OVERLORD_IP>:<OVERLORD_PORT>/druid/indexer/v1/supervisor 来提交任务。
Kafka Indexing Service开发的目的是为了增强Kafka中数据的实时摄入。其特性如下:
- 保障数据摄入的Exactly Once。
- 可以摄入任意时间戳的数据,而不仅仅是当前数据。
- 可以根据Kafka分区的变化二调整任务的数量。
影响数据摄入Exactly Once的主要因素是Kafka的Offset管理。Kafka Indexing Service为了实现Exactly Once语义,去掉了windowPeriod,并采用底层API实现了对Offset的事务管理。
Kafka Indexing Service的类图如下:
其中:
KafkaSupervisor
负责整个Kafka Indexing Service的创建以及其整个生命周期的管理,它监管Kafka Indexing Service的状态来完成协调移交,管理失败,同时保障添加/删除Kafka 分区以后的可扩展性以及任务的多副本执行。
TaskGroups
是KafkaSupervisor管理partition,Offset和Indexing service的数据结构,用来保障任务的多副本执行。每个TaskGroups中的所有任务做的都是相同的事情。读取分配给TaskGroups的所有partition的数据,而且都是从相同的Offset开始读取。通过修改replicas的值来调整任务副本数量。
KafkaIndexTask
从KafkaIOConfig的startPosition中的offset处开始读取数据,一直到endPartition的结束Offset处结束读取,发布移交segment。在执行过程中,startPosition中的Offset不会变,endPosition的Offset初始设置为: Long.MAX_VALUE。KafkaSupervisor通过修改endPosition的值来结束任务的执行。运行中的任务有两种状态:读取和发布。任务会保持读取状态,直到达到taskDuration以后进入发布状态。接下来会保持发布状态,直到生成segment,并推送至Deep Storage,然后His节点加载。或者达到completionTimeout的时间。
Appenderator
用来索引数据,采用LSM-Tree结构。这个模块负责索引和查询数据,并将Segment推送到Deep Storage中,他只将Segment信息发布到元数据存储中。
FiniteAppendratorDriver
驱动Appendrator完成有限流式数据的索引,在索引结束后执行移交操作。它完成Appenderator不能做的那些事情,包括SegmentAllocator将数据分配到指定的Segment,监控移交等。
Kafka Indexing Service利用Kafka的底层Consumer接口,从传入startOffsets Map{partition, startOffset} 处读取数据,使用FiniteAppendratorDriver构建Segment。FiniteAppendratorDriver采用有限流失数据的处理方式,读取固定时间段的数据。
FiniteAppendratorDriver会带来副作用,会产生一些碎片化的Segment,特别是日志跨时段乱序延迟严重的情况。
如何使用?
将该Extension添加到Overlord和MiddleManager中:
druid.extensions.loadList=["other-modules", "kafka-indexing-service"]
通过 http://<OVERLORD_IP>:<OVERLORD_PORT>/druid/indexer/v1/supervisor 来提交任务。