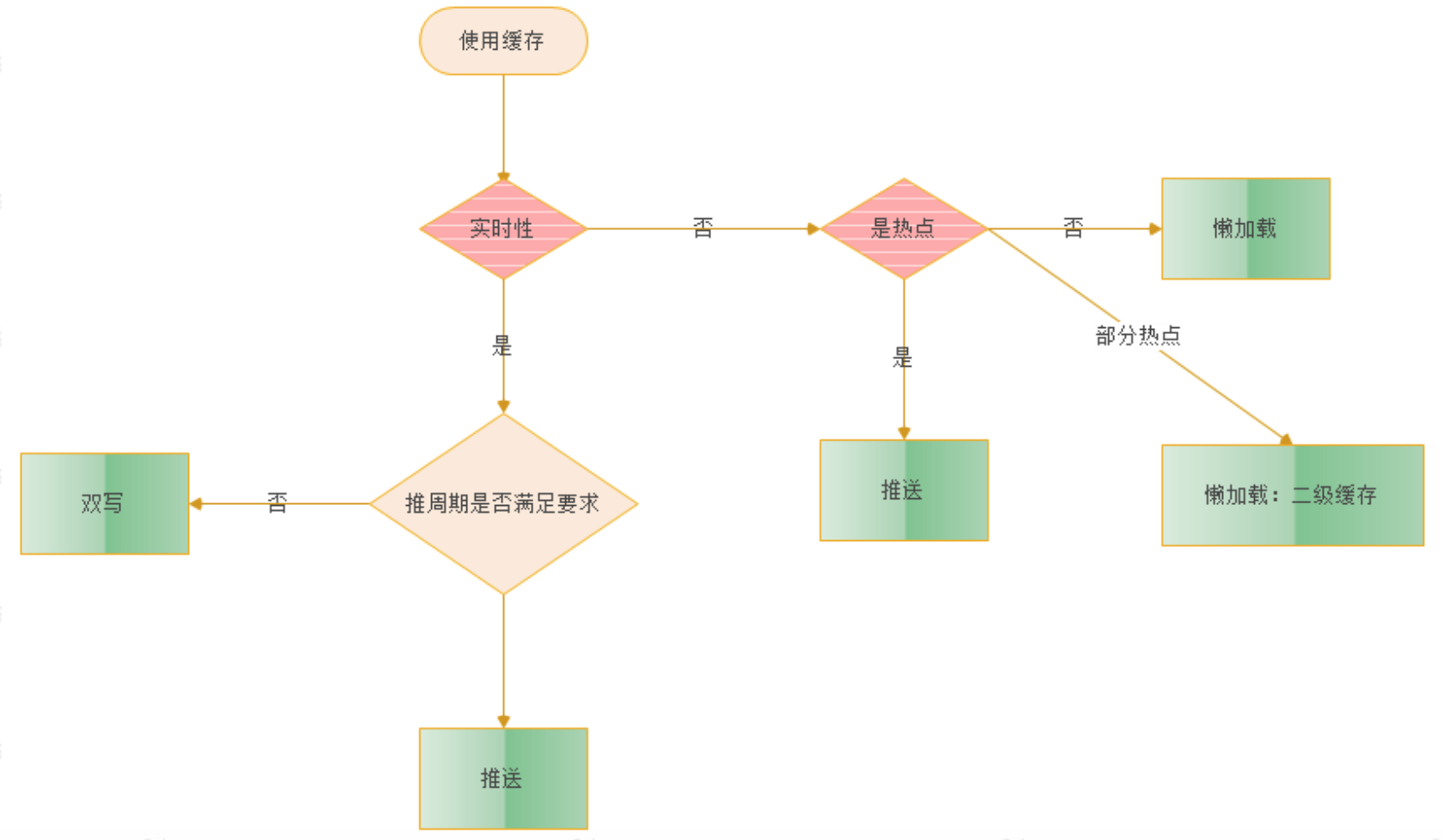
一、使用缓存
1、缓存的使用适用于变化不频繁,需要大量被访问的数据,例如线路、仓库名称等,每次大促来临之时,业务上会禁止一些数据的变更,以便于数据预热到缓存时能与DB保持一致,大促之时,系统基本从缓存中读取数据,以此减少IO次数,同时也是为了保护高流量下DB不会击垮。
2、缓存分为本地缓存 & 分布式缓存,本地缓存是将热点数据存储到本地JVM中,系统访问数据时先从本地缓存中读取,没有再从分布式缓存中获取,先读取本地可以有效地降低网络通信的耗时(访问分布式缓存需要走网络通信)。本地缓存如今有许多开源框架供以选择,例如guava cache、Caffine等,当然最简单的还是使用JDK的ConcurrentHashMap,在高并发系统中,Caffine性能好于guava,一般系统中,使用guava即可。
3、使用缓存的场景是高并发 & 允许出现短时间的数据不一致。如果业务是实时性的,需要考虑采用主动推送的方式更新缓存,当数据库出现变化时,主动put最新值到缓存中,但update & put操作还是存在时间差的,这段时间里还是会出现缓存不一致的情况,但好于缓存失效之后再去DB中捞取数据。