与Python中csv模块不同,Python中没有处理Excel文件的标准模块,所有需要xlrd和xlwt扩展包,这两个包的具体安装过程,请大家自行百度,我就不在这多叙述了,本文主要讲的是Python对Excel文件的几个简单操作,由于代码里注释比较详细,所以本文文字会相对来说会少一下,如有不懂地方,可以私信我。
一、利用xlrd和xlwt进行简单读写Excel文件:
import sys
from xlrd import open_workbook
'''
利用xlrd模块读取excel工作簿三个表的name,行数和列数
'''
input_file="E:\\studytest\\data\\excel\\sales_2013.xlsx"
workbook=open_workbook(input_file)
print("Number of worksheets:",workbook.nsheets)
for worksheet in workbook.sheets():
print("Worksheet name:",worksheet.name,"\tRows:",worksheet.nrows,"\tColumns:",worksheet.ncols)二、处理单个文件:
import sys
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
'''
处理单个工作表
1、读写excel文件
'''
input_file='E:\\studytest\\data\\excel\\sales_2013.xlsx'
output_file='E:\\studytest\\data\\excel_test\\2output.xlsx'
output_workbook=Workbook()
output_worksheet=output_workbook.add_sheet('jan_2013_output')
with open_workbook(input_file) as workbook:
#根据工作表名字选区工作表
worksheet=workbook.sheet_by_name('january_2013')
for row_index in range(worksheet.nrows):
for column_index in range(worksheet.ncols):
output_worksheet.write(row_index,column_index,worksheet.cell_value(row_index,column_index))
output_workbook.save(output_file)但是需要注意的是,当工作表中存在日期格式的列时,写入时会变成数字,该数字为时间数值与1900年1月1日之间的天数差,为了保证数据的完整性,我们需要对格式为日期的列进行格式化,代码如下:
from datetime import date
input_file='E:\\studytest\\data\\excel\\sales_2013.xlsx'
output_file='E:\\studytest\\data\\excel_test\\2output_date.xlsx'
output_workbook=Workbook()
output_worksheet=output_workbook.add_sheet('jan_2013_output')
with open_workbook(input_file) as workbook:
worksheet=workbook.sheet_by_name('january_2013')
#循环行
for row_index in range(worksheet.nrows):
#用于存放构造好的行数据
row_list_output = []
#循环列
for column_index in range(worksheet.ncols):
#type=3表示该列类型为日期
#若该列为日期格式,则格式化日期
if worksheet.cell_type(row_index,column_index) == 3:
date_cell = xldate_as_tuple(worksheet.cell_value(row_index,column_index),workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%Y')
row_list_output.append(date_cell)
output_worksheet.write(row_index,column_index,date_cell)
#否则直接拼接row_list_output
else:
non_date_cell = worksheet.cell_value(row_index,column_index)
row_list_output.append(non_date_cell)
output_worksheet.write(row_index,column_index,non_date_cell)
output_workbook.save(output_file)在处理单个文件时,我们经常会有筛选特定的行的需求,而筛选特定存在一下三种情况:
1、行中某列数值满足某个条件;
2、行中某列数值在某个集合里;
3、行中某列的值匹配于特定的模式。
三种情况代码大致相同,本文只列出第一种情况的代码,大家可以试着做一下后两中。
2、筛选特定行
2、1 行中的值满足某个条件
2、2 行中的值属于某个集合(和上面的差不多,判断条件改成in A集合)
2、3 行中的值匹配于特定的模式(和上面的差不多,判断条件改成pattern.search(数值))
'''
from datetime import date
input_file='E:\\studytest\\data\\excel\\sales_2013.xlsx'
output_file='E:\\studytest\\data\\excel_test\\4output.xlsx'
output_workbook=Workbook()
output_worksheet=output_workbook.add_sheet('jan_2013_output')
#条件:第四列的值
sale_amount_column_index=3
with open_workbook(input_file) as workbook:
worksheet=workbook.sheet_by_name('january_2013')
data = []
#取表头
header = worksheet.row_values(0)
data.append(header)
#循环第1行到最后一行
for row_index in range(1,worksheet.nrows):
#用于存放构造好的行数据
row_list_output = []
#取出需要判断列的值,比如某列值大于1400
sale_amount = worksheet.cell_value(row_index,sale_amount_column_index)
if sale_amount > 1400.0:
#循环该列
for column_index in range(worksheet.ncols):
#type=3表示该列类型为日期
#若该列为日期格式,则格式化日期
if worksheet.cell_type(row_index,column_index) == 3:
date_cell = xldate_as_tuple(worksheet.cell_value(row_index,column_index),workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%Y')
row_list_output.append(date_cell)
#否则直接拼接row_list_output
else:
non_date_cell = worksheet.cell_value(row_index,column_index)
row_list_output.append(non_date_cell)
if row_list_output:
data.append(row_list_output)
#此处用迭代的原因是因为,如果直接写入的话,会导致索引也写入到新文件中,写入后的文件会出现空白行的情况
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)大家可以看一下,上面代码倒数第四行用到了迭代,为什么要用迭代呐,因为直接写入时会把行的索引也写入到新文件中,就会导致文件出现空白行的现象,如下图:

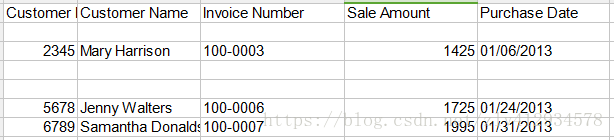
所以,为了避免出现这种情况,这里使用了迭代,后面的所有代码中凡是利用迭代实现,都是为了避免这种情况的出现。
当然,除了筛选特定行,我们还会有筛选特定列的需求,筛选特定列存在一下两种方法:
1、根据列索引来筛选,工作表中每个列都有一个对应的索引值,从0开始;
2、根据列标题来筛选,其中这种筛选方法和1原理一样,先根据列标题找出对应的索引值,单后根据索引值筛选,好处是不会出错,只要列标题正确,筛选的结果就不会出错。
下面是两种方法的实现代码:
'''
3、选取特定的列
3、1 根据列索引值
'''
from datetime import date
input_file='E:\\studytest\\data\\excel\\sales_2013.xlsx'
output_file='E:\\studytest\\data\\excel_test\\7output.xlsx'
output_workbook=Workbook()
output_worksheet=output_workbook.add_sheet('jan_2013_output')
#条件:只取索引号为1和4的两列
my_columns = [1,4]
with open_workbook(input_file) as workbook:
worksheet=workbook.sheet_by_name('january_2013')
data = []
for row_index in range(worksheet.nrows):
#用于存放构造好的行数据
row_list = []
#循环满足条件的列
for column_index in my_columns:
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
#type=3表示该列类型为日期
#若该列为日期格式,则格式化日期
if cell_type == 3:
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%Y')
row_list.append(date_cell)
#否则直接拼接row_list_output
else:
row_list.append(cell_value)
data.append(row_list)
#此处用迭代的原因是因为,如果直接写入的话,会导致索引也写入到新文件中,写入后的文件会出现空白行的情况
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)'''
3、2 根据列标题选取(同上,先根据标题选出列索引值,然后再使用列索引值)
'''
from datetime import date
input_file='E:\\studytest\\data\\excel\\sales_2013.xlsx'
output_file='E:\\studytest\\data\\excel_test\\8output.xlsx'
output_workbook=Workbook()
output_worksheet=output_workbook.add_sheet('jan_2013_output')
#条件:只取索引号为1和4的两列
my_columns = ['Customer ID','Purchase Date']
with open_workbook(input_file) as workbook:
worksheet=workbook.sheet_by_name('january_2013')
data = [my_columns]
#取出列标题行
header_list=worksheet.row_values(0)
header_index_list = []
#循环标题列表,找出符合条件列的索引号
for header_index in range(len(header_list)):
if header_list[header_index] in my_columns:
header_index_list.append(header_index)
for row_index in range(1,worksheet.nrows):
#用于存放构造好的行数据
row_list = []
#循环满足条件的列
for column_index in header_index_list:
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
#type=3表示该列类型为日期
#若该列为日期格式,则格式化日期
if cell_type == 3:
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%Y')
row_list.append(date_cell)
#否则直接拼接row_list_output
else:
row_list.append(cell_value)
data.append(row_list)
#此处用迭代的原因是因为,如果直接写入的话,会导致索引也写入到新文件中,写入后的文件会出现空白行的情况
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)三、处理工作簿中多个Excel工作表
在处理多个Excel文件时,我们基本的操作和单个相似,有如下三种:
1、选取特定的行;(存在三种情况,请参看二中处理单个文件)
2、选取特定的列;(存在两种方法,请参看二中处理单个文件)
3、选取特定的工作表(一个工作簿中存在多个Excel工作表,有时候我们并不是都需要处理,这个时候我们就可以根据条件来处理相应的文件)
三种情况代码如下:
1、选取特定的行;
'''
读取工作簿中的所有工作表
1、在所有工作表中筛选特定行
'''
import sys
from datetime import date
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
input_file='E:\\studytest\\data\\excel\\sales_2013.xlsx'
output_file='E:\\studytest\\data\\excel_test\\10output.xlsx'
output_workbook=Workbook()
output_worksheet=output_workbook.add_sheet('filtered_rows_all_worksheets')
sale_column_index = 3
threshold = 2000.0
first_worksheet = True
with open_workbook(input_file) as workbook:
data = []
for worksheet in workbook.sheets():
if first_worksheet:
header_row=worksheet.row_values(0)
data.append(header_row)
first_worksheet= False
for row_index in range(1,worksheet.nrows):
row_list = []
sale_amount=worksheet.cell_value(row_index,sale_column_index)
if sale_amount > threshold:
for column_index in range(worksheet.ncols):
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type == 3:
date_cell=xldate_as_tuple(cell_value,workbook.datemode)
date_cell=date(*date_cell[0:3]).strftime('%m/%d/%Y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
if row_list:
data.append(row_list)
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)2、筛选特定列:
'''
2、在所有工作表中筛选特定列
根据前面操作单工作表的代码,我们可以发现这个地方存在两种方法,一是根据索引值;二是根据列标题。我们以第二种为例。
'''
import sys
from datetime import date
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
input_file='E:\\studytest\\data\\excel\\sales_2013.xlsx'
output_file='E:\\studytest\\data\\excel_test\\10output.xlsx'
output_workbook=Workbook()
output_worksheet=output_workbook.add_sheet('selected_columns_all_worksheets')
#条件,取列标题为XX的两列
my_columns = ['Customer Name','Sale Amount']
first_worksheet = True
with open_workbook(input_file) as workbook:
data = [my_columns]
#存放列标题对应的索引值
index_of_cols_to_keep = []
for worksheet in workbook.sheets():
if first_worksheet:
header_row=worksheet.row_values(0)
for column_index in range(len(header_row)):
if header_row[column_index] in my_columns:
index_of_cols_to_keep.append(column_index)
first_worksheet= False
for row_index in range(1,worksheet.nrows):
row_list = []
for column_index in index_of_cols_to_keep:
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type == 3:
date_cell=xldate_as_tuple(cell_value,workbook.datemode)
date_cell=date(*date_cell[0:3]).strftime('%m/%d/%Y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
data.append(row_list)
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)3、选取特定的工作表
'''
3、在excel工作簿中读取一组工作表
'''
import sys
from datetime import date
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
input_file='E:\\studytest\\data\\excel\\sales_2013.xlsx'
output_file='E:\\studytest\\data\\excel_test\\11output.xlsx'
output_workbook=Workbook()
output_worksheet=output_workbook.add_sheet('set_of_worksheets')
#条件,取索引号为0和1的两个工作表
my_sheets = [0,1]
first_worksheet = True
with open_workbook(input_file) as workbook:
data = []
#循环工作簿中每个工作表
for sheet_index in range(workbook.nsheets):
#判断是否为需要处理的工作表
if sheet_index in my_sheets:
# 找到符合要求的工作表,并取出表内容
worksheet = workbook.sheet_by_index(sheet_index)
if first_worksheet:
header_row=worksheet.row_values(0)
data.append(header_row)
first_worksheet= False
for row_index in range(1,worksheet.nrows):
row_list = []
for column_index in range(worksheet.ncols):
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type == 3:
date_cell=xldate_as_tuple(cell_value,workbook.datemode)
date_cell=date(*date_cell[0:3]).strftime('%m/%d/%Y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
if row_list:
data.append(row_list)
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)四、处理多个工作簿
1、工作表计数和每个工作表中行列的计数:
'''
处理多个工作簿
1、工作表计数以及每个工作表中的行列计数
'''
import glob
import os
import sys
from xlrd import open_workbook
input_directory = 'E:\\studytest\\data\\excel'
workbook_counter = 0
for input_file in glob.glob(os.path.join(input_directory,'*.xlsx')):
workbook = open_workbook(input_file)
print('Workbook:%s'%os.path.basename((input_file)))
print('Number of worksheets:%d'%workbook.nsheets)
for worksheet in workbook.sheets():
print('Worksheet name:',worksheet.name,'\tRows:',worksheet.nrows,'\tColumns:',worksheet.ncols)
workbook_counter += 1
print('Number of Excel workbooks:%d'%(workbook_counter))2、从多个工作簿中连接数据:
下面代码实现的是将多个工作簿中数据放到一个Excel工作表中
'''
2、从多个工作簿中连接数据
'''
import glob
import os
import sys
from datetime import date
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
input_directory = 'E:\\studytest\\data\\excel'
output_file = 'E:\\studytest\\data\\excel_test\\13output.xlsx'
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('all_data_all_workbooks')
data = []
first_worksheet = True
#循环多个工作簿
for input_file in glob.glob(os.path.join(input_directory,'*.xls*')):
print(os.path.basename(input_file))
#打开当前工作簿
with open_workbook(input_file) as workbook:
#循环当前工作簿的每个工作表
for worksheet in workbook.sheets():
if first_worksheet:
header_row = worksheet.row_values(0)
data.append(header_row)
first_worksheet = False
#循环行
for row_index in range(1,worksheet.nrows):
row_list = []
#循环列
for column_index in range(worksheet.ncols):
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type == 3:
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%Y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
data.append(row_list)
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)3、为每个工作簿和工作表计算总数和均值
'''
3、为每个工作簿和工作表计算总数和均值
'''
import glob
import os
import sys
from datetime import date
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
input_directory = 'E:\\studytest\\data\\excel'
output_file = 'E:\\studytest\\data\\excel_test\\14output.xlsx'
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('sums_and_averages')
all_data = []
#对索引号为3的列求总值和平均值
sale_column_index = 3
#输出文件列标题
header = ['workbook','worksheet','worksheet_total','worksheet_average','workbook_total','workbook_average']
all_data.append(header)
#循环多个工作簿
for input_file in glob.glob(os.path.join(input_directory,'*.xls*')):
#打开当前工作簿
with open_workbook(input_file) as workbook:
#存放当前工作簿所求列的总值
list_of_totals = []
# 存放当前工作簿所求列的个数
list_of_number = []
workbook_output = []
#循环当前工作簿的每个工作表
for worksheet in workbook.sheets():
#当前工作表所求列总值
total_sales = 0
#当前工作表所求列个数
number_of_sales = 0
#存放当前工作表的名字,总值,平均值
worksheet_list = []
worksheet_list.append(os.path.basename(input_file))
worksheet_list.append(worksheet.name)
#循环行
for row_index in range(1,worksheet.nrows):
try:
total_sales += float(str(worksheet.cell_value(row_index,sale_column_index)))
number_of_sales += 1
except:
total_sales += 0
number_of_sales += 0
average_sales = '%.2f'%(total_sales/number_of_sales)
worksheet_list.append(total_sales)
worksheet_list.append(float(average_sales))
list_of_totals.append(total_sales)
list_of_number.append(float(average_sales))
workbook_output.append(worksheet_list)
workbook_total = sum(list_of_totals)
workbook_average = sum(list_of_totals)/sum(list_of_number)
for list_element in workbook_output:
list_element.append(workbook_total)
list_element.append(workbook_average)
all_data.extend(workbook_output)
for list_index,output_list in enumerate(all_data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)由于代码相对基础,所以我只贴出来比较细节的代码结果截图,其余的大家可以根据代码自己实现一下看看效果,使用以上代码只需要修改代码前几号文件的路径即可。
如有什么问题和疑问,请私信我,我会在第一时间帮你解决!谢谢支持