这一节开始建立模型,在建模之前,我们先梳理一下思路:
思路:
1、首先选出只带标签的数据(有风险和无风险的),进行分析,建立一个 recall rate 风险交易召回率较高的二分类模型。
2、接着在无标签的数据上应用此模型,打上标签,并与之前有标签的数据进行合并,形成最终完整训练样本。
3、将新的训练样本送入模型,得到最终模型。
4、应用测试数据,得到结果。
模型建立流程:
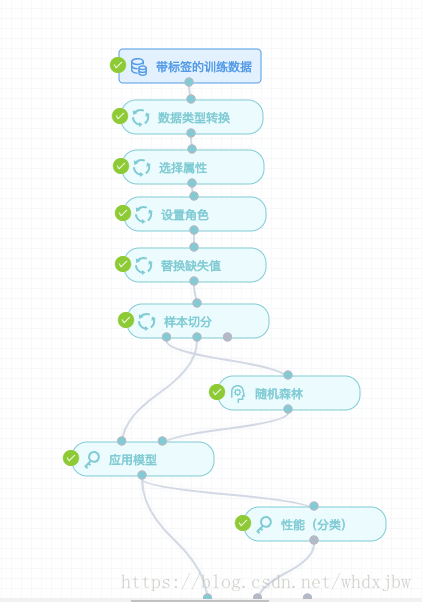
因为id无重复,说明id可能是交易id,而不是账户id,可以不送入模型训练;同时交易时间也可以不送入训练,故利用选择属性算子将其两者过滤。之后将label列的角色设置为标签label,即告诉模型是否有风险的列为你要关心的结果。接着因为随机森林要求输入模型的数据是非空数值类型,故在之前的数据类型转换基础上还要做替换缺失值操作。
在仅利用有标签数据进行预测,随机森林参数maxCategories=50,treeMaxDepth=7,treeNum=30时,结果如下,可以看到效果还不错。
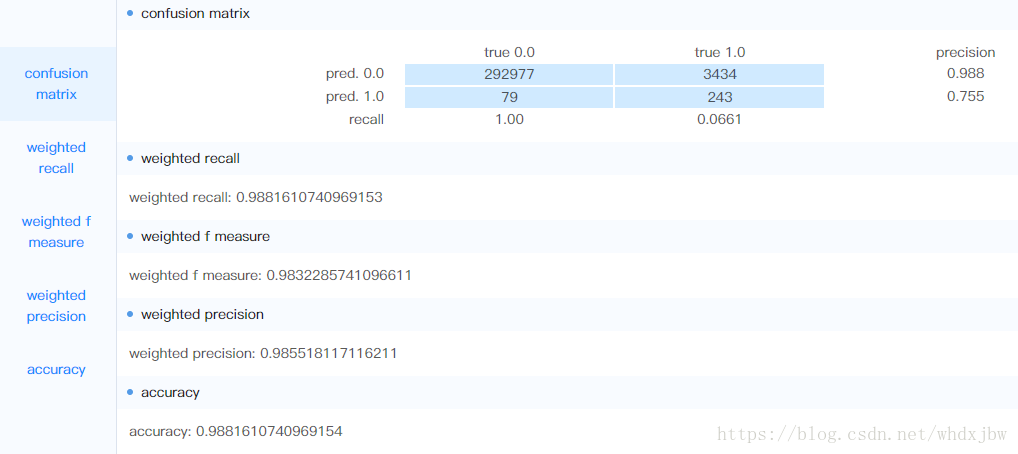
可见当随机森林中树的深度比较小时,效果很差,原因主要是数据中特征太多(接近300个),决策树太浅会导致决策策略过于粗糙,故我们需要提高每颗决策树的深度。
maxCategories=35,treeMaxDepth=6,treeNum=20:

maxCategories=35,treeMaxDepth=14,treeNum=23
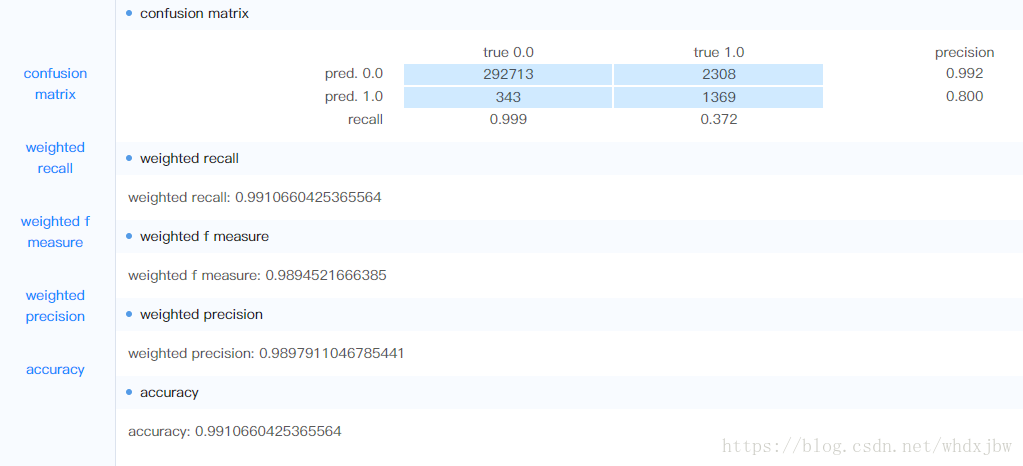
maxCategories=35,treeMaxDepth=30,treeNum=23:

可见单个决策树越深,效果越好,为了保证训练的速度,现在保持树深为15,增大随机森林中树的个数,发现效果也有变好。
maxCategories=32,treeMaxDepth=15,seed=7,treeNum=45:

maxCategories=32,treeMaxDepth=30,seed=7,treeNum=100:

但树的个树一旦超过100,再增加树的个数模型效果改善就不大了:
故最终参数调整如下:
maxCategories=32,treeMaxDepth=15,seed=7,treeNum=150:
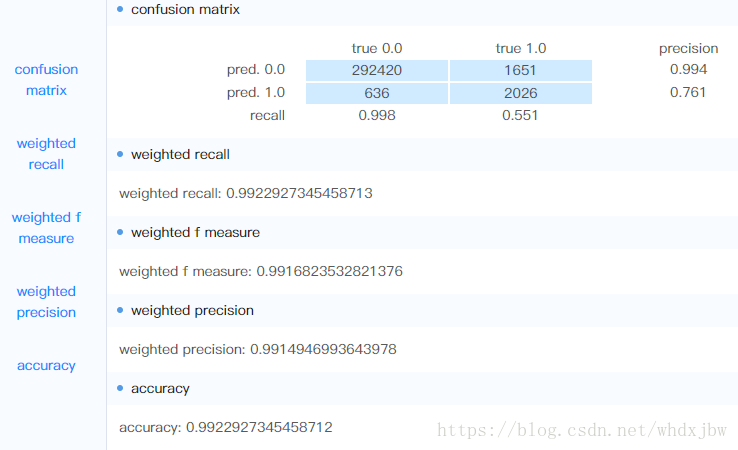
可见,只用带标签的数据,利用随机森林训练出的模型风险数据召回率并不是很高(接近0.5),因为有些无标签数据中也包含黑样本特征的重要信息。
故接下来用以上训练出的模型对无样本数据打标签。由于篇幅原因,在下一篇博客中介绍。