前言:初赛215名/2522,A榜成绩一直在前100名,最好时大约排名前10。
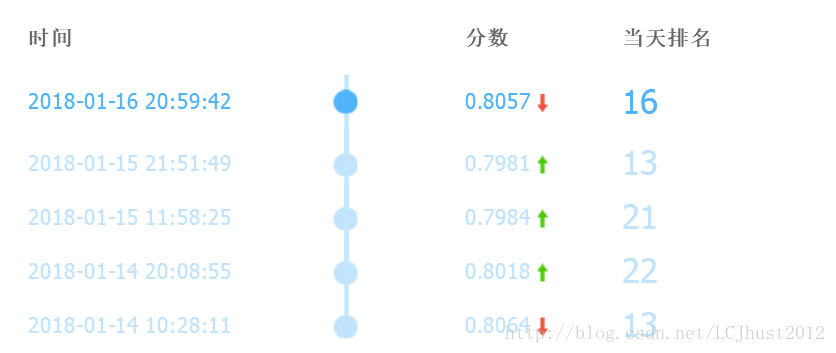
B榜换了测试数据后,结果大跌眼镜,成绩只有200多名,应该是模型不够稳定,或者说过拟合了。

虽然对最终的成绩感到有点小小的遗憾,但在这次比赛中确实收获了不少,做一个小小的总结。第一次参加比赛,会把整个工程都做特别详细的介绍,就当是个小小的教程,分享给有需要的小伙伴们~
附上github:https://github.com/LCJHust/MedicalTreat_Diabetes
初赛方案
1.数据观察
导入数据,观察数据规模、数据类型、是否含有空值、计较训练数据和测试数据的不同。

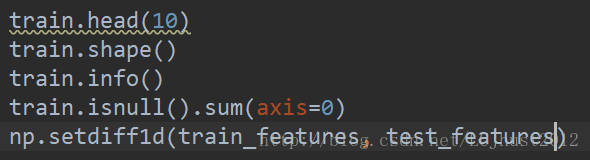
2.数据预处理(数据清洗):
(1)读入数据后,为了数据显示与观察的方便,将所有的columns都用英文名称代替。

(2)性别特征做one-hot coding,男性为1,女性为0。

(3)观察到最早的体检日期为2017-09-15,将所有的日期都转化为距离该最早体检日期的天数。

(4)用中值或者平均值填充空值。在多次提交结果中发现,这两者区别并不是很大,平均值效果略微比中值好一些。

3.特征工程
(1)做特征间的加减乘除四则运算,生成大量候选特征,依次向最优子集添加。如果线下交叉验证结果有较为明显的提升,则将生成的特征加入作为新的特征。

(2)部分特征的缺失值的比例非常高,而用中值或者平均值填充后病没有明显的改善,并且无法找到合理的解释,于是我们决定删除那些有大量缺失值的特征。在lightgbm模型中,做了特征重要性排名,根据排名删除那些对结果几乎没有贡献或者贡献很小的特征。

4.模型训练
(1)我们最初使用的是xgboost模型,6折交叉验证,之后又采用lightgbm和randomforest进行模型融合,最终的预测结果为:

一点点小收获
1.在训练模型时,仅仅采用大赛给的测评函数进行评估,在线下进行分析时没有从模型的多个角度评价模型的好坏。
2.观察数据发现,有一些样本的血糖值非常高,大于20,而我们的模型预测测试数据时,最高的血糖值不会超过10,。简而言之,模型无法预测实际血糖较高的样本。关于这一点,我个人认为,测试数据中的这部分样本本身就是异常值,属于较大的噪声,故模型无法做出准确的预测。
3.针对第2点,我们对预测结果进行了一些后处理,找出预测结果中较大的一小部分值,将人为地它们进行扩大。事实证明,进行后处理的A榜结果有很大的改善,排名明显提高,但是我们也因此陷入了误区。正因为这些数据是异常值,而我们却想尽一切办法尽可能地去逼近这些值,这样做训练出来的模型鲁棒性很差,严重过拟合测试数据A,对另一组测试数据B非常不利,因为你无法得知B榜数据的异常值是什么样的。我认为这是造成我们A榜、B榜结果相差甚远的最主要原因。
4.我们缺少对特征之间关联性、独立性的分析,特征工程做得不是很好。
5.我们缺少对两组测试数据的分布情况的分析,没有对此做出相应的调整。
6.心态上,小白第一次参加比赛,在前20多天里,排名没有掉过前100,到了初赛后期已经十分轻敌了,状态有些松懈,心里还一直美滋滋乐呵呵,暗搓搓地觉得自己可牛皮了呢,然而被最终被打脸啪啪响(哭哭)。
7.总之,有经历才有成长嘛!