vue 与 vue-resource 跨域问题解决
方法一:
在vue项目下的 config/index.js 文件里面配置代理proxyTable:
var path = require('path')
module.exports = {
build: {
env: require('./prod.env'),
index: path.resolve(__dirname, '../dist/index.html'),
assetsRoot: path.resolve(__dirname, '../dist'),
assetsSubDirectory: 'static',
assetsPublicPath: '/',
productionSourceMap: true,
// Gzip off by default as many popular static hosts such as
// Surge or Netlify already gzip all static assets for you.
// Before setting to `true`, make sure to:
// npm install --save-dev compression-webpack-plugin
productionGzip: false,
productionGzipExtensions: ['js', 'css'],
// Run the build command with an extra argument to
// View the bundle analyzer report after build finishes:
// `npm run build --report`
// Set to `true` or `false` to always turn it on or off
bundleAnalyzerReport: process.env.npm_config_report
},
dev: {
env: require('./dev.env'),
port: 8080,
autoOpenBrowser: true,
assetsSubDirectory: 'static',
assetsPublicPath: '/',
proxyTable: {
'/login': {
target: 'http://192.168.0.240:8888/yammiicn/v1/login',
changeOrigin: true,
pathRewrite: {
'^/login':''
}
}
},
// CSS Sourcemaps off by default because relative paths are "buggy"
// with this option, according to the CSS-Loader README
// (https://github.com/webpack/css-loader#sourcemaps)
// In our experience, they generally work as expected,
// just be aware of this issue when enabling this option.
cssSourceMap: false
}
}方法二:
使用
Vue.http.options.xhr = { withCredentials: true }
//或是
this.$http.jsonp('...', { credentials: true })
//例子
this.$http.jsonp("https://sug.so.360.cn/suggest",{
params:{
word:'a'
}
}).then(resp=>{
console.log(resp.data.s);
},response => {
console.log("发送失败"+response.status+","+response.statusText);
}); iframe高度自适应
JS自适应高度,其实就是设置iframe的高度,使其等于内嵌网页的高度,从而看不出来滚动条和嵌套痕迹。对于用户体验和网站美观起着重要作用。如果内容是固定的,那么我们可以通过CSS来给它直接定义一个高度,同样可以实现上面的需求。当内容是未知或者是变化的时候。这个时候又有几种情况了。iframe内容未知,高度可预测这个时候,我们可以给它添加一个默认的CSS的min-height值,然后同时使用JavaScript改变高度。常用的兼容代码有:`
// document.domain = "caibaojian.com";
function setIframeHeight(iframe) {
if (iframe) {
var iframeWin = iframe.contentWindow || iframe.contentDocument.parentWindow;
if (iframeWin.document.body) {
iframe.height = iframeWin.document.documentElement.scrollHeight || iframeWin.document.body.scrollHeight;
}
}
};
window.onload = function () {
setIframeHeight(document.getElementById('external-frame'));
};
演示地址·演示一(如果在同个顶级域名下,不同子域名之间互通信息,设置document.domain=”caibaojian.com”只要修改以上的iframe的ID即可了。或者你可以直接在iframe里面写代码,我们一般为了不污染HTML代码,建议使用上面的代码。
<iframe src="backtop.html" frameborder="0" scrolling="no" id="external-frame" onload="setIframeHeight(this)"></iframe>演示二多个iframe的情况下`
<script language="javascript">
//输入你希望根据页面高度自动调整高度的iframe的名称的列表
//用逗号把每个iframe的ID分隔. 例如: ["myframe1", "myframe2"],可以只有一个窗体,则不用逗号。
//定义iframe的ID
var iframeids=["test"];
//如果用户的浏览器不支持iframe是否将iframe隐藏 yes 表示隐藏,no表示不隐藏
var iframehide="yes";
function dyniframesize()
{
var dyniframe=new Array()
for (i=0; i<iframeids.length; i++)
{
if (document.getElementById)
{
//自动调整iframe高度
dyniframe[dyniframe.length] = document.getElementById(iframeids[i]);
if (dyniframe[i] && !window.opera)
{
dyniframe[i].style.display="block";
if (dyniframe[i].contentDocument && dyniframe[i].contentDocument.body.offsetHeight) //如果用户的浏览器是NetScape
dyniframe[i].height = dyniframe[i].contentDocument.body.offsetHeight;
else if (dyniframe[i].Document && dyniframe[i].Document.body.scrollHeight) //如果用户的浏览器是IE
dyniframe[i].height = dyniframe[i].Document.body.scrollHeight;
}
}
//根据设定的参数来处理不支持iframe的浏览器的显示问题
if ((document.all || document.getElementById) && iframehide=="no")
{
var tempobj=document.all? document.all[iframeids[i]] : document.getElementById(iframeids[i]);
tempobj.style.display="block";
}
}
}
if (window.addEventListener)
window.addEventListener("load", dyniframesize, false);
else if (window.attachEvent)
window.attachEvent("onload", dyniframesize);
else
window.onload=dyniframesize;
</script>演示三针对知道的iframe的ID调用
function iframeAutoFit(iframeObj){
setTimeout(function(){if(!iframeObj) return;iframeObj.height=(iframeObj.Document?iframeObj.Document.body.scrollHeight:iframeObj.contentDocument.body.offsetHeight);},200)
}演示四内容宽度变化的iframe高度自适应
<iframe src="backtop.html" frameborder="0" scrolling="no" id="test" onload="this.height=100"></iframe>
<script type="text/javascript">
function reinitIframe(){
var iframe = document.getElementById("test");
try{
var bHeight = iframe.contentWindow.document.body.scrollHeight;
var dHeight = iframe.contentWindow.document.documentElement.scrollHeight;
var height = Math.max(bHeight, dHeight);
iframe.height = height;
console.log(height);
}catch (ex){}
}
window.setInterval("reinitIframe()", 200);
演示五打开调试运行窗口可以看到运行。
跨域下的iframe自适应高度跨域的时候,由于js的同源策略,父页面内的js不能获取到iframe页面的高度。需要一个页面来做代理。
方法如下:假设www.a.com下的一个页面a.html要包含www.b.com下的一个页面c.html。
我们使用www.a.com下的另一个页面agent.html来做代理,通过它获取iframe页面的高度,并设定iframe元素的高度。
a.html中包含iframe:
<iframe src="http://www.b.com/c.html" id="Iframe" frameborder="0" scrolling="no" style="border:0px;"></iframe>在c.html中加入如下代码:
<iframe id="c_iframe" height="0" width="0" src="http://www.a.com/agent.html" style="display:none" ></iframe>
<script type="text/javascript">
(function autoHeight(){
var b_width = Math.max(document.body.scrollWidth,document.body.clientWidth);
var b_height = Math.max(document.body.scrollHeight,document.body.clientHeight);
var c_iframe = document.getElementById("c_iframe");
c_iframe.src = c_iframe.src + "#" + b_width + "|" + b_height; // 这里通过hash传递b.htm的宽高
})();
</script>最后,agent.html中放入一段js:
<script type="text/javascript">
var b_iframe = window.parent.parent.document.getElementById("Iframe");
var hash_url = window.location.hash;
if(hash_url.indexOf("#")>=0){
var hash_width = hash_url.split("#")[1].split("|")[0]+"px";
var hash_height = hash_url.split("#")[1].split("|")[1]+"px";
b_iframe.style.width = hash_width;
b_iframe.style.height = hash_height;
}
</script>获取DOM元素的宽高
agent.html从URL中获得宽度值和高度值,并设置iframe的高度和宽度(因为agent.html在www.a.com下,所以操作a.html时不受JavaScript的同源限制)
avascript中获取dom元素高度和宽度的方法如下:
网页可见区域宽: document.body.clientWidth
网页可见区域高: document.body.clientHeight
网页可见区域宽: document.body.offsetWidth (包括边线的宽)
网页可见区域高: document.body.offsetHeight (包括边线的高)
网页正文全文宽: document.body.scrollWidth
网页正文全文高: document.body.scrollHeight
网页被卷去的高: document.body.scrollTop
网页被卷去的左: document.body.scrollLeft
对应的dom元素的宽高有以下几个常用的:
元素的实际高度:document.getElementById("div").offsetHeight
元素的实际宽度:document.getElementById("div").offsetWidth
元素的实际距离左边界的距离:document.getElementById("div").offsetLeft
元素的实际距离上边界的距离:document.getElementById("div").offsetTop
vue监听窗口大小变化自适应
data(){
return {
clientHeight: '600px',
},
},
mounted() {
// 动态设置背景图的高度为浏览器可视区域高度
// 首先在Virtual DOM渲染数据时,设置下背景图的高度.
this.clientHeight.height = `${document.documentElement.clientHeight}px`;
// 然后监听window的resize事件.在浏览器窗口变化时再设置下背景图高度.
const that = this;
window.onresize = function temp() {
that.clientHeight = `${document.documentElement.clientHeight}px`;
};
},[https://github.com/pagekit/vue-resource/blob/develop/docs/http.md]:
CDN服务器加速
CDN服务器加速原理
用户访问未使用CDN缓存网站的过程为:
1)、用户向浏览器提供要访问的域名;
2)、浏览器调用域名解析函数库对域名进行解析,以得到此域名对应的IP地址;
3)、浏览器使用所得到的IP地址,向域名的服务主机发出数据访问请求;
4)、浏览器根据域名主机返回的数据显示网页的内容。
通过以上四个步骤,浏览器完成从用户处接收用户要访问的域名到从域名服务主机处获取数据的整个过程。CDN网络是在用户和服务器之间增加Cache层,如何将用户的请求引导到Cache上获得源服务器的数据,主要是通过接管DNS实现,下面让我们看看访问使用CDN缓存后的网站的过程:
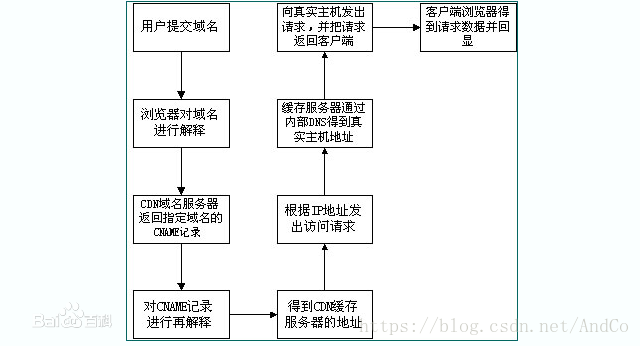
通过上图,我们可以了解到,使用了CDN缓存后的网站的访问过程变为:
1)、用户向浏览器提供要访问的域名;
2)、浏览器调用域名解析库对域名进行解析,由于CDN对域名解析过程进行了调整,所以解析函数库一般得到的是该域名对应的CNAME记录,为了得到实际IP地址,浏览器需要再次对获得的CNAME域名进行解析以得到实际的IP地址;在此过程中,使用的全局负载均衡DNS解析,如根据地理位置信息解析对应的IP地址,使得用户能就近访问。
3)、此次解析得到CDN缓存服务器的IP地址,浏览器在得到实际的IP地址以后,向缓存服务器发出访问请求;
4)、缓存服务器根据浏览器提供的要访问的域名,通过Cache内部专用DNS解析得到此域名的实际IP地址,再由缓存服务器向此实际IP地址提交访问请求;
5)、缓存服务器从实际IP地址得得到内容以后,一方面在本地进行保存,以备以后使用,另一方面把获取的数据返回给客户端,完成数据服务过程;
6)、客户端得到由缓存服务器返回的数据以后显示出来并完成整个浏览的数据请求过程。
通过以上的分析我们可以得到,为了实现既要对普通用户透明(即加入缓存以后用户客户端无需进行任何设置,直接使用被加速网站原有的域名即可访问,又要在为指定的网站提供加速服务的同时降低对ICP的影响,只要修改整个访问过程中的域名解析部分,以实现透明的加速服务,下面是CDN网络实现的具体操作过程。
1)、作为ICP,只需要把域名解释权交给CDN运营商,其他方面不需要进行任何的修改;操作时,ICP修改自己域名的解析记录,一般用cname方式指向CDN网络Cache服务器的地址。
2)、作为CDN运营商,首先需要为ICP的域名提供公开的解析,为了实现sortlist,一般是把ICP的域名解释结果指向一个CNAME记录;
3)、当需要进行sortlist时,CDN运营商可以利用DNS对CNAME指向的域名解析过程进行特殊处理,使DNS服务器在接收到客户端请求时可以根据客户端的IP地址,返回相同域名的不同IP地址;
4)、由于从cname获得的IP地址,并且带有hostname信息,请求到达Cache之后,Cache必须知道源服务器的IP地址,所以在CDN运营商内部维护一个内部DNS服务器,用于解释用户所访问的域名的真实IP地址;
5)、在维护内部DNS服务器时,还需要维护一台授权服务器,控制哪些域名可以进行缓存,而哪些又不进行缓存,以免发生开放代理的情况。
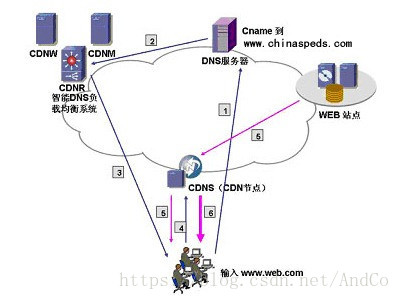
1.用户向浏览器输入www.web.com这个域名,浏览器第一次发现本地没有dns缓存,则向网站的DNS服务器请求;
2.网站的DNS域名解析器设置了CNAME,指向了www.web.51cdn.com,请求指向了CDN网络中的智能DNS负载均衡系统;
3.智能DNS负载均衡系统解析域名,把对用户响应速度最快的IP节点返回给用户;
4.用户向该IP节点(CDN服务器)发出请求;
5.由于是第一次访问,CDN服务器会向原web站点请求,并缓存内容;
6.请求结果发给用户。
SEO优化概述
第一个,站内结构优化
合理规划站点结构(1、扁平化结构 2、辅助导航、面包屑导航、次导航)
内容页结构设置(最新文章、推荐文章、热门文章、增加相关性、方便自助根据链接抓取更多内容)
较快的加载速度
简洁的页面结构
第二个,代码优化
Robot.txt
次导航
404页面设置、301重定向
网站地图
图片Alt、title标签
标题
关键词
描述
关键字密度
个别关键字密度
H1H2H3中的关键字
关键字强调
外链最好nofollow
为页面添加元标记meta
丰富网页摘要(微数据、微格式和RDFa)
第三个,网站地图设置
html网站地图(1、为搜索引擎建立一个良好的导航结构 2、横向和纵向地图:01横向为频道、栏目、专题/02纵向主要针对关键词 3、每页都有指向网站地图的链接)
XML网站地图(sitemap.xml提交给百度、google)
第四个,关键词部署
挑选关键词的步骤(1、确定目标关键词 2、目标关键词定义上的扩展 3、模拟用户的思维设计关键词 4、研究竞争者的关键词)
页面关键词优化先后顺序(1、最终页>专题>栏目>频道>首页 2、最终页:长尾关键词 3、专题页:【a、热门关键词 b、为热点关键词制作专题 c、关键词相关信息的聚合 d、辅以文章内链导入链接】 4、栏目页:固定关键词 5、频道页:目标关键词 6、首页:做行业一到两个顶级关键词,或者网站名称)
关键词部署建议(1、不要把关键词堆积在首页 2、每个页面承载关键词合理数目为3-5个 3、系统规划)
然后,我们的内容编辑人员要对网站进行内容建设,怎样合理的做到网站内部优化的功效?这里主要有五个方面:
第一个,网站内容来源
原创内容或伪原创内容
编辑撰稿或UGC
扫描书籍、报刊、杂志
第二个,内容细节优化
标题写法、关键词、描述设置
文章摘要规范
URL标准化
次导航
内页增加锚文本以及第一次出现关键词进行加粗
长尾关键词记录单
图片Alt、titile标签
外链最好nofollow
百度站长工具、google管理员工具的使用
建立反向链接
第三个,关键词部署
挑选关键词的步骤(1、确定目标关键词 2、目标关键词定义上的扩展 3、模拟用户的思维设计关键词 4、研究竞争者的关键词)
页面关键词优化先后顺序(1、最终页>专题>栏目>频道>首页 2、最终页:长尾关键词 3、专题页:【a、热门关键词 b、为热点关键词制作专题 c、关键词相关信息的聚合 d、辅以文章内链导入链接】 4、栏目页:固定关键词 5、频道页:目标关键词 6、首页:做行业一到两个顶级关键词,或者网站名称)
关键词部署建议(1、不要把关键词堆积在首页 2、每个页面承载关键词合理数目为3-5个 3、系统规划)
第四个,内链策略
控制文章内部链接数量
链接对象的相关性要高
给重要网页更多的关注
使用绝对路径
需要改进的地方
第五个,注意事项
不要大量采集
有节奏的更新
编辑发布文章的时候要做好锚文本
做好长尾关键词记录单
接下来,我们的推广人员就要对网站进行站外优化了,这里主要包括两个大的方面:
第一个,外链建设基本途径
友情链接
软文
目录提交
独立博客
论坛签名
黄页网站
提交收藏
分类信息
微博推广
sns推广
第二个,链接诱饵建设思路
举办活动,带上相关链接,引导网友大规模转播
最后,我们的数据分析人员就要对网站进行每天的数据分析,总结流量来源,这里主要从五个方面分析:
第一个,数据分析
根据统计(百度统计工具,CNZZ统计工具等等),分析用户进入的关键词,模拟用户思路,思考长尾关键词
第二个,竞争对手分析
百度权重、PR值
快照
反链
内链
收录
网站历史
品牌关键词
长尾关键词
网站结构
第三个,关键词定位
目标关键词
品牌关键词
热门关键词
长尾关键词
第四个,长尾关键词挖掘—长尾关键词类型
目标型长尾(目标型指的是网站的产品或者服务延伸的长尾关键词,往往优化长尾的时候都是先以目标型长尾为主,因为这些长尾可以真实给我们带来目标客户和目标量)
营销型长尾(营销型长尾是指与行业站服务相关的长尾,可以让我们进行二次转化成我们的目标用户)
第五个,挖掘长尾关键词用到的工具
百度指数工具
百度知道
百度及其他SE的相关搜索及下拉框
百度站长工具、google关键词分析工具
至此,一个完整的网站SEO优化方案已经完成
域名解析两种方式
1、什么是域名解析?
域名解析就是国际域名或者国内域名以及中文域名等域名申请后做的到IP地址的转换过程。IP地址是网路上标识您站点的数字地址,为了简单好记,采用域名来代替ip地址标识站点地址。域名的解析工作由DNS服务器完成。
2、什么是A记录?
A (Address) 记录是用来指定主机名(或域名)对应的IP地址记录。用户可以将该域名下的网站服务器指向到自己的web server上。同时也可以设置您域名的二级域名。
3、什么是CNAME记录?
即:别名记录。这种记录允许您将多个名字映射到另外一个域名。通常用于同时提供WWW和MAIL服务的计算机。例如,有一台计算机名为“host.mydomain.com”(A记录)。它同时提供WWW和MAIL服务,为了便于用户访问服务。可以为该计算机设置两个别名(CNAME):WWW和MAIL。这两个别名的全称就 http://www.mydomain.com/和“mail.mydomain.com”。实际上他们都指向 “host.mydomain.com”。
4、使用A记录和CNAME进行域名解析的区别
A记录就是把一个域名解析到一个IP地址(Address,特制数字IP地址),而CNAME记录就是把域名解析到另外一个域名。其功能是差不多,CNAME将几个主机名指向一个别名,其实跟指向IP地址是一样的,因为这个别名也要做一个A记录的。但是使用CNAME记录可以很方便地变更IP地址。如果一台服务器有100个网站,他们都做了别名,该台服务器变更IP时,只需要变更别名的A记录就可以了。
5、使用A记录和CNAME哪个好?
域名解析CNAME记录A记录哪一种比较好?如果论对网站的影响,就没有多大区别。但是:CNAME有一个好处就是稳定,就好像一个IP与一个域名的区别。服务商从方便维护的角度,一般也建议用户使用CNAME记录绑定域名的。如果主机使用了双线IP,显然使用CNAME也要方便一些。
A记录也有一些好处,例如可以在输入域名时不用输入WWW.来访问网站哦!从SEO优化角度来看,一些搜索引擎如alex或一些搜索查询工具网站等等则默认是自动去掉WWW.来辨别网站,CNAME记录是必须有如:WWW(别名)前缀的域名,有时候会遇到这样的麻烦,前缀去掉了默认网站无法访问。
有人认为,在SEO优化网站的时候,由于搜索引擎找不到去掉WWW.的域名时,对网站权重也会有些影响。因为有些网民客户也是不喜欢多写三个W来访问网站的,网站无法访问有少量网民客户会放弃继续尝试加WWW.访问域名了,因此网站访问浏览量也会减少一些。
也有人认为同一个域名加WWW.和不加WWW.访问网站也会使网站权重分散,这也是个问题。但是可以使用301跳转把不加WWW.跳转到加WWW.的域名,问题就解决了。
浏览器渲染
浏览器渲染原理
浏览器工作大流程

从上面这个图中,我们可以看到那么几个事:
1)浏览器会解析三个东西:
- 一个是HTML/SVG/XHTML,事实上,Webkit有三个C++的类对应这三类文档。解析这三种文件会产生一个DOM Tree。
- CSS,解析CSS会产生CSS规则树。
- Javascript,脚本,主要是通过DOM API和CSSOM API来操作DOM Tree和CSS Rule Tree.
2)解析完成后,浏览器引擎会通过DOM Tree 和 CSS Rule Tree 来构造 Rendering Tree。注意:
- Rendering Tree 渲染树并不等同于DOM树,因为一些像Header或display:none的东西就没必要放在渲染树中了。
- CSS 的 Rule Tree主要是为了完成匹配并把CSS Rule附加上Rendering Tree上的每个Element。也就是DOM结点。也就是所谓的Frame。
- 然后,计算每个Frame(也就是每个Element)的位置,这又叫layout和reflow过程。
3)最后通过调用操作系统Native GUI的API绘制。
DOM解析
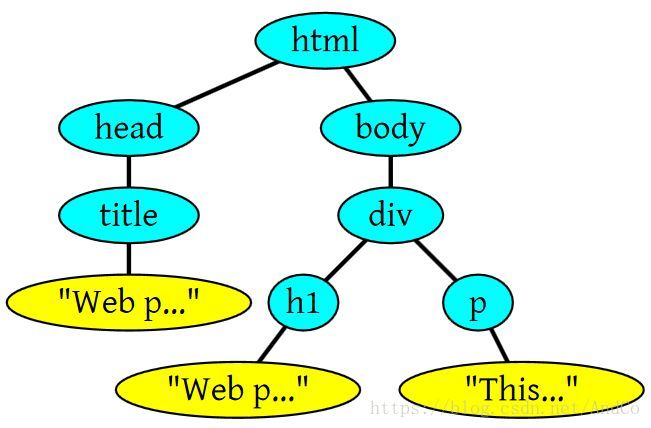
HTML的DOM Tree解析如下:
<html> <head> <title>Web page parsing</title> </head> <body> <div> <h1>Web page parsing</h1> <p>This is an example Web page.</p> </div> </body></html>上面这段HTML会解析成这样:
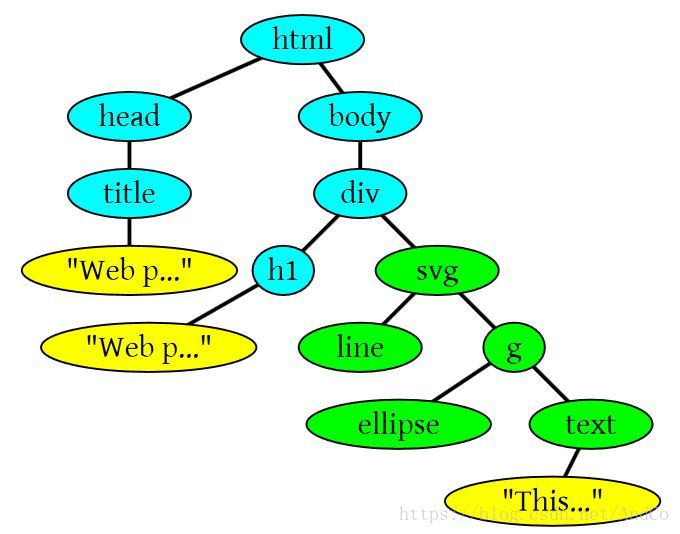
下面是另一个有SVG标签的情况。
CSS解析
CSS的解析大概是下面这个样子(下面主要说的是Gecko也就是Firefox的玩法),假设我们有下面的HTML文档:
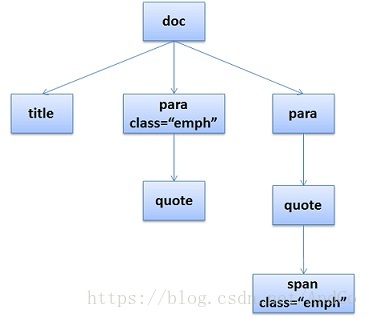
<doc><title>A few quotes</title><para> Franklin said that <quote>"A penny saved is a penny earned."</quote></para><para> FDR said <quote>"We have nothing to fear but <span>fear itself.</span>"</quote></para></doc>于是DOM Tree是这个样子:
然后我们的CSS文档是这样的:
/* rule 1 */ doc { display: block; text-indent: 1em; }/* rule 2 */ title { display: block; font-size: 3em; }/* rule 3 */ para { display: block; }/* rule 4 */ [class="emph"] { font-style: italic; }于是我们的CSS Rule Tree会是这个样子:
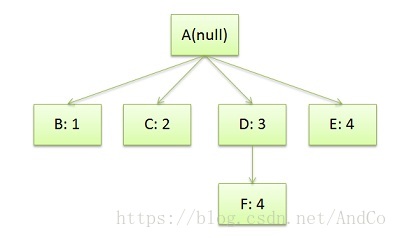
注意,图中的第4条规则出现了两次,一次是独立的,一次是在规则3的子结点。所以,我们可以知道,建立CSS Rule Tree是需要比照着DOM Tree来的。CSS匹配DOM Tree主要是从右到左解析CSS的Selector,好多人以为这个事会比较快,其实并不一定。关键还看我们的CSS的Selector怎么写了。
注意:CSS匹配HTML元素是一个相当复杂和有性能问题的事情。所以,你就会在N多地方看到很多人都告诉你,DOM树要小,CSS尽量用id和class,千万不要过渡层叠下去,……
通过这两个树,我们可以得到一个叫Style Context Tree,也就是下面这样(把CSS Rule结点Attach到DOM Tree上):
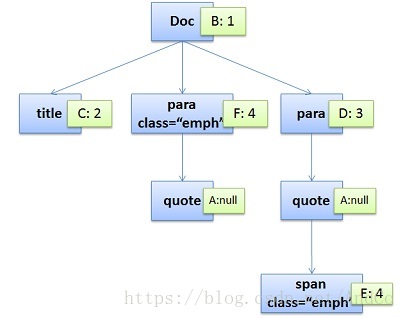
所以,Firefox基本上来说是通过CSS 解析 生成 CSS Rule Tree,然后,通过比对DOM生成Style Context Tree,然后Firefox通过把Style Context Tree和其Render Tree(Frame Tree)关联上,就完成了。注意:Render Tree会把一些不可见的结点去除掉。而Firefox中所谓的Frame就是一个DOM结点,不要被其名字所迷惑了。
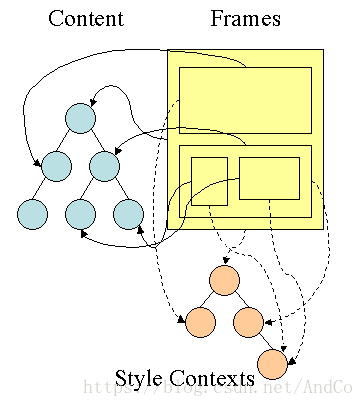
注:Webkit不像Firefox要用两个树来干这个,Webkit也有Style对象,它直接把这个Style对象存在了相应的DOM结点上了。
渲染
渲染的流程基本上如下(黄色的四个步骤):
- 计算CSS样式
- 构建Render Tree
- Layout – 定位坐标和大小,是否换行,各种position, overflow, z-index属性 ……
- 正式开画
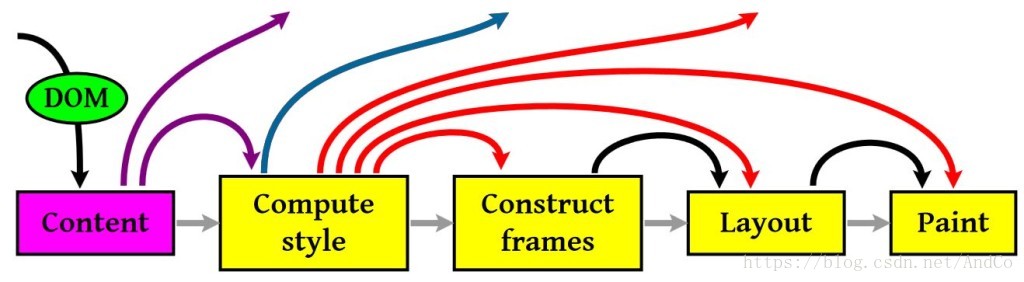
注意:上图流程中有很多连接线,这表示了Javascript动态修改了DOM属性或是CSS属会导致重新Layout,有些改变不会,就是那些指到天上的箭头,比如,修改后的CSS rule没有被匹配到,等。
浏览器渲染过程
- 用户输入网址(假设是个html页面,并且是第一次访问),浏览器向服务器发出请求,服务器返回html文件;
- 浏览器开始载入html代码,发现标签内有一个标签引用外部CSS文件;
- 浏览器又发出CSS文件的请求,服务器返回这个CSS文件;
- 浏览器继续载入html中部分的代码,并且CSS文件已经拿到手了,可以开始渲染页面了;
- 浏览器在代码中发现一个!img标签引用了一张图片,向服务器发出请求。此时浏览器不会等到图片下载完,而是继续渲染后面的代码;
- 服务器返回图片文件,由于图片占用了一定面积,影响了后面段落的排布,因此浏览器需要回过头来重新渲染这部分代码;
- 浏览器发现了一个包含一行JavaScript代码的
reflow(回流)和repaint(重绘)
reflow(回流),与repaint区别就是他会影响到dom的结构渲染,同时他会触发repaint,他会改变他本身与所有父辈元素(祖先),这种开销是非常昂贵的,导致性能下降是必然的,页面元素越多效果越明显。
repaint(重绘) ,repaint发生更改时,元素的外观被改变,且在没有改变布局的情况下发生,如改变outline,visibility,background color,不会影响到dom结构渲染。
何时发生:
- DOM元素的添加、修改(内容)、删除( Reflow + Repaint)
- 仅修改DOM元素的字体颜色(只有Repaint,因为不需要调整布局)
- 应用新的样式或者修改任何影响元素外观的属性
- Resize浏览器窗口、滚动页面
- 读取元素的某些属性(offsetLeft、offsetTop、offsetHeight、offsetWidth、 scrollTop/Left/Width/Height、clientTop/Left/Width/Height、 getComputedStyle()、currentStyle(in IE))
如何避免:
如果想设定元素的样式,通过改变元素的 class 名 (尽可能在 DOM 树的最末端)
避免设置多项内联样式
应用元素的动画,使用 position 属性的 fixed 值或 absolute 值
权衡平滑和速度
避免使用table布局
避免使用CSS的JavaScript表达式 (仅 IE 浏览器)
尽可能在DOM树的最末端改变class
回流可以自上而下,或自下而上的回流的信息传递给周围的节点。回流是不可避免的,但可以减少其影响。尽可能在DOM树的里面改变class,可以限制了回流的范围,使其影响尽可能少的节点。例如,你应该避免通过改变对包装元素类去影响子节点的显示。面向对象的CSS始终尝试获得它们影响的类对象(DOM节点或节点),但在这种情况下,它已尽可能的减少了回流的影响,增加性能优势。
避免设置多层内联样式
我们都知道与DOM交互很慢。我们尝试在一种无形的DOM树片段组进行更改,然后整个改变应用到DOM上时仅导致了一个回流。同样,通过style属性设置样式导致回流。避免设置多级内联样式,因为每个都会造成回流,样式应该合并在一个外部类,这样当该元素的class属性可被操控时仅会产生一个reflow。
动画效果应用到position属性为absolute或fixed的元素上
动画效果应用到position属性为absolute或fixed的元素上,它们不影响其他元素的布局,所它他们只会导致重新绘制,而不是一个完整回流。这样消耗会更低。
牺牲平滑度换取速度
Opera还建议我们牺牲平滑度换取速度,其意思是指您可能想每次1像素移动一个动画,但是如果此动画及随后的回流使用了100%的CPU,动画就会看上去是跳动的,因为浏览器正在与更新回流做斗争。动画元素每次移动3像素可能在非常快的机器上看起来平滑度低了,但它不会导致CPU在较慢的机器和移动设备中抖动。
避免使用table布局
避免使用table布局。可能您需要其它些避免使用table的理由,在布局完全建立之前,table经常需要多个关口,因为table是个和罕见的可以影响在它们之前已经进入的DOM元素的显示的元素。想象一下,因为表格最后一个单元格的内容过宽而导致纵列大小完全改变。这就是为什么所有的浏览器都逐步地不支持table表格的渲染(感谢Bill Scott提供)。然而有另外一个原因为什么表格布局时很糟糕的主意,根据Mozilla,即使一些小的变化将导致表格(table)中的所有其他节点回流。
避免使用CSS的JavaScript表达式
这项规则较过时,但确实是个好的主意。主要的原因,这些表现是如此昂贵,是因为他们每次重新计算文档,或部分文档、回流。正如我们从所有的很多事情看到的:引发回流,它可以每秒产生成千上万次。当心!
浏览器缓存
缓存的概念
缓存的分类
在Web应用领域,Web缓存大致可以分为以下几种类型:
1.数据库数据缓存
Web应用,特别是社交网络服务类型的应用,往往关系比较复杂,数据库表繁多,如果频繁进行数据库查询,很容易导致数据库不堪重荷。为了提供查询的性能,会将查询后的数据放到内存中进行缓存,下次查询时,直接从内存缓存直接返回,提供响应效率。比如常用的缓存方案有memcached,redis等。
2.服务器端缓存
- 代理服务器缓存
代理服务器是浏览器和源服务器之间的中间服务器,浏览器先向这个中间服务器发起Web请求,经过处理后(比如权限验证,缓存匹配等),再将请求转发到源服务器。代理服务器缓存的运作原理跟浏览器的运作原理差不多,只是规模更大。可以把它理解为一个共享缓存,不只为一个用户服务,一般为大量用户提供服务,因此在减少相应时间和带宽使用方面很有效,同一个副本会被重用多次。常见代理服务器缓存解决方案有Squid,Nginx,Apache等。
- CDN缓存
CDN(Content delivery networks)缓存,也叫网关缓存、反向代理缓存。CDN缓存一般是由网站管理员自己部署,为了让他们的网站更容易扩展并获得更好的性能。浏览器先向CDN网关发起Web请求,网关服务器后面对应着一台或多台负载均衡源服务器,会根据它们的负载请求,动态将请求转发到合适的源服务器上。虽然这种架构负载均衡源服务器之间的缓存没法共享,但却拥有更好的处扩展性。从浏览器角度来看,整个CDN就是一个源服务器,浏览器和服务器之间的缓存机制,在这种架构下同样适用。
3.浏览器端缓存
浏览器缓存根据一套与服务器约定的规则进行工作,在同一个会话过程中会检查一次并确定缓存的副本足够新。如果你浏览过程中,比如前进或后退,访问到同一个图片,这些图片可以从浏览器缓存中调出而即时显现。
4.Web应用层缓存
应用层缓存指的是从代码层面上,通过代码逻辑和缓存策略,实现对数据,页面,图片等资源的缓存,可以根据实际情况选择将数据存在文件系统或者内存中,减少数据库查询或者读写瓶颈,提高响应效率。
什么是浏览器缓存
- 浏览器缓存 是指一个Web资源(如html页面,图片,js,数据等)存在于Web服务器和客户端(浏览器)之间的副本。缓存会根据进来的请求保存输出内容的副本;当下一个请求来到的时候,如果是相同的URL,缓存会根据缓存机制决定是直接使用副本响应访问请求,还是向源服务器再次发送请求。比较常见的就是浏览器会缓存访问过网站的网页,当再次访问这个URL地址的时候,如果网页没有更新,就不会再次下载网页,而是直接使用本地缓存的网页。只有当网站明确标识资源已经更新,浏览器才会再次下载网页。至于浏览器和网站服务器是如何标识网站页面是否更新的机制,将在后面介绍。
- 浏览器缓存 这个概念,对于经常用浏览器来浏览信息的用户来说并不十分陌生。用户也许在用浏览器浏览信息时,经常使用”返回”和”后退”的浏览功能,调用你以前阅读过的页面,这时,你会发现显示速度是很快的,其实这些你刚调出来的内容就放在计算机的缓存中,而不需要再次从Internet上重新传输数据,这样就会给用户造成了一种访问速度被提高的错觉。 所以浏览器缓存其实就是指在本地使用的计算机中开辟一个内存区,同时也开辟一个硬盘区作为数据传输的缓冲区,然后用这个缓冲区来暂时保存用户以前访问过的信息。既然缓存存在于硬盘之中,那么它肯定是以文件夹的形式出现的(查看各浏览器本地缓存位置)。
浏览器缓存的作用
使用Web缓存的作用其实是非常显而易见的:
减少网络带宽消耗
无论对于网站运营者或者用户,带宽都代表着金钱,过多的带宽消耗,只会便宜了网络运营商。当Web缓存副本被使用时,只会产生极小的网络流量,可以有效的降低运营成本。
降低服务器压力
给网络资源设定有效期之后,用户可以重复使用本地的缓存,减少对源服务器的请求,间接降低服务器的压力。同时,搜索引擎的爬虫机器人也能根据过期机制降低爬取的频率,也能有效降低服务器的压力。
减少网络延迟,加快页面打开速度
带宽对于个人网站运营者来说是十分重要,而对于大型的互联网公司来说,可能有时因为钱多而真的不在乎。那Web缓存还有作用吗?答案是肯定的,对于最终用户,缓存的使用能够明显加快页面打开速度,达到更好的体验。
现在的大型网站,随便一个页面都是一两百个请求,每天 pv 都是亿级别,如果没有缓存,用户体验会急剧下降、同时服务器压力和网络带宽都面临严重的考验。 缓存和重用以前获取的资源的是优化网页性能很重要的一个方面。
缺点也是有的:
缓存没有清理机制:这些缓存的文件会永久性地保存在机器上,在特定的时间内,这些文件可能是帮了你大忙,但是时间一长,我们已经不再需要浏览之前的这些网页,这些文件就成了无效或者无用的文件,它们存储在用户硬盘中只会占用空间而没有任何用处,如果要缓存的东西非常多,那就会撑暴整个硬盘空间。
给开发带来的困扰:明明修改了样式文件、图片、视频或脚本,刷新页面或部署到站点之后看不到修改之后的效果。
所以在产品开发的时候我们总是想办法避免缓存产生,而在产品发布之时又在想策略管理缓存提升网页的访问速度。了解浏览器的缓存命中原理和清除方法,对我们大有裨益。
浏览器缓存的类型
1、非HTTP协议定义的缓存机制
浏览器缓存机制,其实主要就是HTTP协议定义的缓存机制(如: Expires; Cache-control等)。但是也有非HTTP协议定义的缓存机制,如使用HTML Meta 标签,Web开发者可以在HTML页面的节点中加入标签,代码如下:
1、Expires(期限)
说明:可以用于设定网页的到期时间。一旦网页过期,必须到服务器上重新传输。
用法:
Html代码
<meta http-equiv="expires" content="Wed, 20 Jun 2007 22:33:00 GMT">注意:必须使用GMT的时间格式。
2、Pragma(cache模式)
说明:是用于设定禁止浏览器从本地机的缓存中调阅页面内容,设定后一旦离开网页就无法从Cache中再调出
用法:
Html代码
<META HTTP-EQUIV="Pragma" CONTENT="no-cache">注意:这样设定,访问者将无法脱机浏览。
更多设置:参看Meta http-equiv属性详解
2、HTTP协议定义的缓存机制。
浏览器缓存机制图
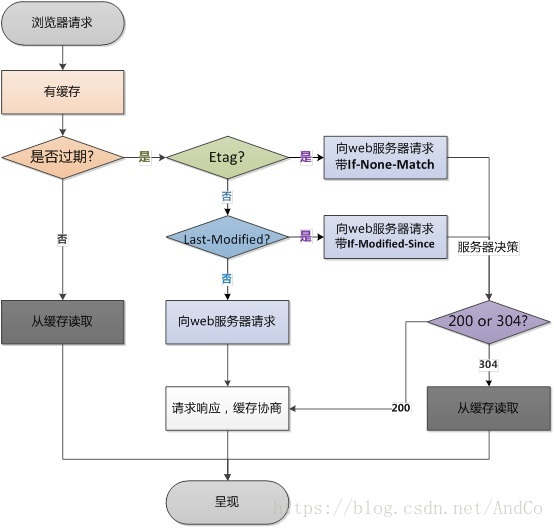
浏览器缓存机制策略
3、其他主流浏览器缓存机制
- websql
- indexDB
- cookie
- localstorage
- sessionstorage
- application cache
- cacheStorage
较多的缓存机制目前主流浏览器并不兼容,不过可以使用polyfill的方法来处理。
https://github.com/Modernizr/Modernizr/wiki/HTML5-Cross-Browser-Polyfills
http协议下的缓存机制
1. http协议缓存基本认识
它分为强缓存和协商缓存:
1)浏览器在加载资源时,先根据这个资源的一些http header判断它是否命中强缓存,强缓存如果命中,浏览器直接从自己的缓存中读取资源,不会发请求到服务器。比如某个css文件,如果浏览器在加载它所在的网页时,这个css文件的缓存配置命中了强缓存,浏览器就直接从缓存中加载这个css,连请求都不会发送到网页所在服务器;
2)当强缓存没有命中的时候,浏览器一定会发送一个请求到服务器,通过服务器端依据资源的另外一些http header验证这个资源是否命中协商缓存,如果协商缓存命中,服务器会将这个请求返回,但是不会返回这个资源的数据,而是告诉客户端可以直接从缓存中加载这个资源,于是浏览器就又会从自己的缓存中去加载这个资源;
3)强缓存与协商缓存的共同点是:如果命中,都是从客户端缓存中加载资源,而不是从服务器加载资源数据;区别是:强缓存不发请求到服务器,协商缓存会发请求到服务器。
4)当协商缓存也没有命中的时候,浏览器直接从服务器加载资源数据。
2. 强缓存的原理
当浏览器对某个资源的请求命中了强缓存时,返回的http状态为200,在chrome的开发者工具的network里面size会显示为from cache
强缓存是利用Expires或者Cache-Control这两个http response header实现的,它们都用来表示资源在客户端缓存的有效期。
Expires是http1.0提出的一个表示资源过期时间的header,它描述的是一个绝对时间,由服务器返回,用GMT格式的字符串表示,如:Expires:Thu, 31 Dec 2017 23:55:55 GMT,它的缓存原理是:
1)浏览器第一次跟服务器请求一个资源,服务器在返回这个资源的同时,在respone的header加上Expires的header,
2)浏览器在接收到这个资源后,会把这个资源连同所有response header一起缓存下来(所以缓存命中的请求返回的header并不是来自服务器,而是来自之前缓存的header);
3)浏览器再请求这个资源时,先从缓存中寻找,找到这个资源后,拿出它的Expires跟当前的请求时间比较,如果请求时间在Expires指定的时间之前,就能命中缓存,否则就不行。
4)如果缓存没有命中,浏览器直接从服务器加载资源时,Expires Header在重新加载的时候会被更新。
Expires是较老的强缓存管理header,由于它是服务器返回的一个绝对时间,在服务器时间与客户端时间相差较大时,缓存管理容易出现问题,比如随意修改下客户端时间,就能影响缓存命中的结果。
所以在http1.1的时候,提出了一个新的header,就是Cache-Control,这是一个相对时间,在配置缓存的时候,以秒为单位,用数值表示,如:Cache-Control:max-age=315360000,它的缓存原理是:
1)浏览器第一次跟服务器请求一个资源,服务器在返回这个资源的同时,在respone的header加上Cache-Control的header
2)浏览器在接收到这个资源后,会把这个资源连同所有response header一起缓存下来;
3)浏览器再请求这个资源时,先从缓存中寻找,找到这个资源后,根据它第一次的请求时间和Cache-Control设定的有效期,计算出一个资源过期时间,再拿这个过期时间跟当前的请求时间比较,如果请求时间在过期时间之前,就能命中缓存,否则就不行。
4)如果缓存没有命中,浏览器直接从服务器加载资源时,Cache-Control Header在重新加载的时候会被更新。
Cache-Control描述的是一个相对时间,在进行缓存命中的时候,都是利用客户端时间进行判断,所以相比较Expires,Cache-Control的缓存管理更有效,安全一些。
这两个header可以只启用一个,也可以同时启用,当response header中,Expires和Cache-Control同时存在时,Cache-Control优先级高于Expires:
3. 强缓存的管理
在实际应用中我们会碰到需要强缓存的场景和不需要强缓存的场景,通常有2种方式来设置是否启用强缓存:
1)通过代码的方式,在web服务器返回的响应中添加Expires和Cache-Control Header;
java.util.Date date = new java.util.Date();
response.setDateHeader("Expires",date.getTime()+20000); //Expires:过时期限值
response.setHeader("Cache-Control", "public"); //Cache-Control来控制页面的缓存与否,public:浏览器和缓存服务器都可以缓存页面信息;
response.setHeader("Pragma", "Pragma"); //Pragma:设置页面是否缓存,为Pragma则缓存,no-cache则不缓存设置不缓存:
response.setHeader( "Pragma", "no-cache" );
response.setDateHeader("Expires", 0);
response.addHeader( "Cache-Control", "no-cache" );//浏览器和缓存服务器都不应该缓存页面信息2)通过配置web服务器的方式,让web服务器在响应资源的时候统一添加Expires和Cache-Control Header。
tomcat还提供了一个ExpiresFilter专门用来配置强缓存,具体使用的方式可参考tomcat的官方文档:http://tomcat.apache.org/tomcat-7.0-doc/config/filter.html#Expires_Filter
比如在javaweb里面,我们可以使用类似下面的代码设置强缓存:
4. 强缓存的应用
强缓存是前端性能优化最有力的工具,没有之一,对于有大量静态资源的网页,一定要利用强缓存,提高响应速度。通常的做法是,为这些静态资源全部配置一个超时时间超长的Expires或Cache-Control,这样用户在访问网页时,只会在第一次加载时从服务器请求静态资源,其它时候只要缓存没有失效并且用户没有强制刷新的条件下都会从自己的缓存中加载,比如前面提到过的京东首页缓存的资源,它的缓存过期时间都设置到了2027年
然而这种缓存配置方式会带来一个新的问题,就是发布时资源更新的问题,比如某一张图片,在用户访问第一个版本的时候已经缓存到了用户的电脑上,当网站发布新版本,替换了这个图片时,已经访问过第一个版本的用户由于缓存的设置,导致在默认的情况下不会请求服务器最新的图片资源,除非他清掉或禁用缓存或者强制刷新,否则就看不到最新的图片效果
5. 协商缓存的原理
当浏览器对某个资源的请求没有命中强缓存,就会发一个请求到服务器,验证协商缓存是否命中,如果协商缓存命中,请求响应返回的http状态为304并且会显示一个Not Modified的字符串。
协商缓存是利用的是【Last-Modified,If-Modified-Since】和【ETag、If-None-Match】这两对Header来管理的。
Last-Modified,If-Modified-Since的控制缓存的原理是:
1)浏览器第一次跟服务器请求一个资源,服务器在返回这个资源的同时,在respone的header加上Last-Modified的header,这个header表示这个资源在服务器上的最后修改时间
2)浏览器再次跟服务器请求这个资源时,在request的header上加上If-Modified-Since的header,这个header的值就是上一次请求时返回的Last-Modified的值:
3)服务器再次收到资源请求时,根据浏览器传过来If-Modified-Since和资源在服务器上的最后修改时间判断资源是否有变化,如果没有变化则返回304 Not Modified,但是不会返回资源内容;如果有变化,就正常返回资源内容。当服务器返回304 Not Modified的响应时,response header中不会再添加Last-Modified的header,因为既然资源没有变化,那么Last-Modified也就不会改变
4)浏览器收到304的响应后,就会从缓存中加载资源。
5)如果协商缓存没有命中,浏览器直接从服务器加载资源时,Last-Modified Header在重新加载的时候会被更新,下次请求时,If-Modified-Since会启用上次返回的Last-Modified值。
Last-Modified -> ETag
【Last-Modified,If-Modified-Since】都是根据服务器时间返回的header,一般来说,在没有调整服务器时间和篡改客户端缓存的情况下,这两个header配合起来管理协商缓存是非常可靠的,但是有时候也会服务器上资源其实有变化,但是最后修改时间却没有变化的情况,而这种问题又很不容易被定位出来,而当这种情况出现的时候,就会影响协商缓存的可靠性。所以就有了另外一对header来管理协商缓存,这对header就是【ETag、If-None-Match】。
ETag、If-None-Match的缓存管理的方式是:
1)浏览器第一次跟服务器请求一个资源,服务器在返回这个资源的同时,在respone的header加上ETag的header,这个header是服务器根据当前请求的资源生成的一个唯一标识,这个唯一标识是一个字符串,只要资源有变化这个串就不同,跟最后修改时间没有关系,所以能很好的补充Last-Modified的问题
2)浏览器再次跟服务器请求这个资源时,在request的header上加上If-None-Match的header,这个header的值就是上一次请求时返回的ETag的值
3)服务器再次收到资源请求时,根据浏览器传过来If-None-Match和然后再根据资源生成一个新的ETag,如果这两个值相同就说明资源没有变化,否则就是有变化;如果没有变化则返回304 Not Modified,但是不会返回资源内容;如果有变化,就正常返回资源内容。与Last-Modified不一样的是,当服务器返回304 Not Modified的响应时,由于ETag重新生成过,response header中还会把这个ETag返回,即使这个ETag跟之前的没有变化
4)浏览器收到304的响应后,就会从缓存中加载资源。
6. 协商缓存的管理
如果没有协商缓存,每个到服务器的请求,就都得返回资源内容,这样服务器的性能会极差。
【Last-Modified,If-Modified-Since】和【ETag、If-None-Match】一般都是同时启用,这是为了处理Last-Modified不可靠的情况。有一种场景需要注意:
分布式系统里多台机器间文件的Last-Modified必须保持一致,以免负载均衡到不同机器导致比对失败;
分布式系统尽量关闭掉ETag(每台机器生成的ETag都会不一样);
协商缓存需要配合强缓存使用,你看前面这个截图中,除了Last-Modified这个header,还有强缓存的相关header,因为如果不启用强缓存的话,协商缓存根本没有意义。
7. 浏览器行为对缓存的影响
8、代码避免浏览器缓存的几种方法总结
meta方法
//不缓存
<META HTTP-EQUIV="pragma" CONTENT="no-cache">
<META HTTP-EQUIV="Cache-Control" CONTENT="no-cache, must-revalidate">
<META HTTP-EQUIV="expires" CONTENT="0">jquery ajax清除浏览器缓存
方式一:用ajax请求服务器最新文件,并加上请求头If-Modified-Since和Cache-Control,如下:
$.ajax({
url:'www.jb51.net',
dataType:'json',
data:{},
beforeSend :function(xmlHttp){
xmlHttp.setRequestHeader("If-Modified-Since","0");
xmlHttp.setRequestHeader("Cache-Control","no-cache");
},
success:function(response){
//操作
}
async:false
});
方法二,直接用cache:false,
$.ajax({
url:'www.jb51.net',
dataType:'json',
data:{},
cache:false,
ifModified :true ,
success:function(response){
//操作
}
async:false
});ajax 跨域请求设置headers :
http://blog.csdn.net/WRian_Ban/article/details/70257261
方法三:用随机数,随机数也是避免缓存的一种很不错的方法
URL 参数后加上 “?ran=” + Math.random(); //当然这里参数 ran可以任意取了
方法四:用随机时间,和随机数一样。
在 URL 参数后加上 “?timestamp=” + new Date().getTime();
HTML5教程之本地存储Web Storage
在HTML5中,一个新增的非常重要的功能就是客户端本地保存数据的功能,我们知道在过去本地存储数据基本都是使用cookies保存一些简单的数据,但是通过长期的实际使用下来,咱们不难发现使用cookies存储永久数据存在一下几个问题:
1、cookies的大小被限制在4KB;
2、cookies是随HTTP事务一起发送的,因此会浪费一部分发送cookies时所使用的带宽;
3、cookies操作繁琐复杂;
Web Storage是什么?
Web Storage功能,顾名思义,就是在Web上针对客户端本地储存数据的功能,具体来说Web Storage分为两种;
sessionStorage:
将数据保存在session对象中,所谓session是指用户在浏览某个网站时,从进入网站到浏览器关闭所经过的这段时间,也就是用户浏览这个网站所花费的时间。session对象可以用来保存在这段时间内所要求保存的任何数据。
localStorage:
将数据保存在客户端本地的硬件设备(通常指硬盘,当然可以是其他的硬件设备)中,即是浏览器被关闭了,该数据仍然存在,下次打开浏览器访问网站时,仍然可以继续使用。
localStorage自带的方法:
| 名称 | 说明 |
|---|---|
| clear | 清空localStorage上存储的数据 |
| getItem | 读取数据 |
| hasOwnProperty | 检查localStorage上是否保存了变量x,需要传入x |
| key | 读取第i个数据的名字或称为键值(从0开始计数) |
| length | localStorage存储变量的个数 |
| propertyIsEnumerable | 用来检测属性是否属于某个对象的 |
| removeItem | 删除某个具体变量 |
| setItem | 存储数据 |
| toLocaleString | 将(数组)转为本地字符串 |
| valueOf | 获取所有存储的数据 |
清空localStorage
localStorage.clear() // undefined
localStorage // Storage {length: 0}存储数据
localStorage.setItem("name","caibin") //存储名字为name值为caibin的变量
localStorage.name = "caibin"; // 等价于上面的命令
localStorage // Storage {name: "caibin", length: 1}读取数据
localStorage.getItem("name") //caibin,读取保存在localStorage对象里名为name的变量的值
localStorage.name // "caibin"
localStorage.valueOf() //读取存储在localStorage上的所有数据
localStorage.key(0) // 读取第一条数据的变量名(键值)
//遍历并输出localStorage里存储的名字和值
for(var i=0; i<localStorage.length;i++){
console.log('localStorage里存储的第'+i+'条数据的名字为:'+localStorage.key(i)+',值为:'+localStorage.getItem(localStorage.key(i)));
}删除某个变量
localStorage.removeItem("name"); //undefined
localStorage // Storage {length: 0} 可以看到之前保存的name变量已经从localStorage里删除了检查localStorage里是否保存某个变量
// 这些数据都是测试的,是在我当下环境里的,只是demo哦~
localStorage.hasOwnProperty('name') //
truelocalStorage.hasOwnProperty('sex') // false将数组转为本地字符串
var arr = ['aa','bb','cc']; // ["aa","bb","cc"]
localStorage.arr = arr //["aa","bb","cc"]
localStorage.arr.toLocaleString(); // "aa,bb,cc"将JSON存储到localStorage里
var students = {
xiaomin: {
name: "xiaoming",
grade: 1
},
teemo: {
name: "teemo",
grade: 3
}
}
students = JSON.stringify(students); //将JSON转为字符串存到变量里
console.log(students);
localStorage.setItem("students",students);//将变量存到localStorage里
var newStudents = localStorage.getItem("students");
newStudents = JSON.parse(students); //转为JSON
console.log(newStudents); // 打印出原先对象设置localStorage的过期时间
<script type="text/javascript">
//封装过期控制代码
function set(key,value){
var curTime = new Date().getTime();
localStorage.setItem(key,JSON.stringify({data:value,time:curTime}));
}
function get(key,exp){
var data = localStorage.getItem(key);
var dataObj = JSON.parse(data);
if (new Date().getTime() - dataObj.time>exp) {
console.log('信息已过期');
//alert("信息已过期")
}else{
//console.log("data="+dataObj.data);
//console.log(JSON.parse(dataObj.data));
var dataObjDatatoJson = JSON.parse(dataObj.data)
return dataObjDatatoJson;
}
}
</script>SessionStorage
SessionStorage:
将数据保存在session对象中,所谓session是指用户在浏览某个网站时,从进入网站到浏览器关闭所经过的这段时间会话,也就是用户浏览这个网站所花费的时间就是session的生命周期。session对象可以用来保存在这段时间内所要求保存的任何数据。
localStorage和sessionStorage区别
- localStorage和sessionStorage一样都是用来存储客户端临时信息的对象。
- 他们均只能存储字符串类型的对象(虽然规范中可以存储其他原生类型的对象,但是目前为止没有浏览器对其进行实现)。
- localStorage生命周期是永久,这意味着除非用户显示在浏览器提供的UI上清除localStorage信息,否则这些信息将永远存在。
- sessionStorage生命周期为当前窗口或标签页,一旦窗口或标签页被永久关闭了,那么所有通过sessionStorage存储的数据也就被清空了。
- 不同浏览器无法共享localStorage或sessionStorage中的信息。相同浏览器的不同页面间可以共享相同的 localStorage(页面属于相同域名和端口),但是不同页面或标签页间无法共享sessionStorage的信息。这里需要注意的是,页面及标 签页仅指顶级窗口,如果一个标签页包含多个iframe标签且他们属于同源页面,那么他们之间是可以共享sessionStorage的。
- 同源的判断规则:
https://www.test.com (不同源,因为协议不同)
http://my.test.com (不同源,因为主机名不同)
http://www.test.com:8080 (不同源,因为端口不同)
- localStorage和sessionStorage使用时使用相同的API:
localStorage.setItem("key","value");//以“key”为名称存储一个值“value”
localStorage.getItem("key");//获取名称为“key”的值
枚举localStorage的方法:
for(var i=0;i<localStorage.length;i++){
var name = localStorage.key(i);
var value = localStorage.getItem(name);
}
删除localStorage中存储信息的方法:
localStorage.removeItem("key");//删除名称为“key”的信息。
localStorage.clear();//清空localStorage中所有信息示例:
滚动时保存滚动位置
var scrollTop=document.body.scrollTop
sessionStorage.setItem("offsetTop", scrollTop);//保存滚动位置
document.body.scrollTop= sessionStorage.getItem("offsetTop")cookie
1、cookie的作用:
我们在浏览器中,经常涉及到数据的交换,比如你登录邮箱,登录一个页面。我们经常会在此时设置30天内记住我,或者自动登录选项。那么它们是怎么记录信息的呢,答案就是今天的主角cookie了,Cookie是由HTTP服务器设置的,保存在浏览器中,但HTTP协议是一种无状态协议,在数据交换完毕后,服务器端和客户端的链接就会关闭,每次交换数据都需要建立新的链接。就像我们去超市买东西,没有积分卡的情况下,我们买完东西之后,超市没有我们的任何消费信息,但我们办了积分卡之后,超市就有了我们的消费信息。cookie就像是积分卡,可以保存积分,商品就是我们的信息,超市的系统就像服务器后台,http协议就是交易的过程。
2、机制的区别:
session机制采用的是在服务器端保持状态的方案,而cookie机制则是在客户端保持状态的方案,cookie又叫会话跟踪机制。打开一次浏览器到关闭浏览器算是一次会话。说到这里,讲下HTTP协议,前面提到,HTTP协议是一种无状态协议,在数据交换完毕后,服务器端和客户端的链接就会关闭,每次交换数据都需要建立新的链接。此时,服务器无法从链接上跟踪会话。cookie可以跟踪会话,弥补HTTP无状态协议的不足。
3、cookie的分类:
cookie分为会话cookie和持久cookie,会话cookie是指在不设定它的生命周期expires时的状态,前面说了,浏览器的开启到关闭就是一次会话,当关闭浏览器时,会话cookie就会跟随浏览器而销毁。当关闭一个页面时,不影响会话cookie的销毁。会话cookie就像我们没有办理积分卡时,单一的买卖过程,离开之后,信息则销毁。
持久cookie则是设定了它的生命周期expires,此时,cookie像商品一样,有个保质期,关闭浏览器之后,它不会销毁,直到设定的过期时间。对于持久cookie,可以在同一个浏览器中传递数据,比如,你在打开一个淘宝页面登陆后,你在点开一个商品页面,依然是登录状态,即便你关闭了浏览器,再次开启浏览器,依然会是登录状态。这就是因为cookie自动将数据传送到服务器端,在反馈回来的结果。持久cookie就像是我们办理了一张积分卡,即便离开,信息一直保留,直到时间到期,信息销毁。
离线缓存之Application Cache
1、应用场景
离线访问对基于网络的应用而言越来越重要。虽然所有浏览器都有缓存机制,但它们并不可靠,也不一定总能起到预期的作用。HTML5 使用ApplicationCache 接口解决了由离线带来的部分难题。前提是你需要访问的web页面至少被在线访问过一次。
2、使用缓存接口可为您的应用带来以下三个优势:
- 离线浏览 – 用户可在离线时浏览您的完整网站
- 速度 – 缓存资源为本地资源,因此加载速度较快。
- 服务器负载更少 – 浏览器只会从发生了更改的服务器下载资源。
3、离线本地存储和传统的浏览器缓存有什么不同呢?
离线存储为整个web提供服务,浏览器缓存只缓存单个页面;
离线存储可以指定需要缓存的文件和哪些文件只能在线浏览,浏览器缓存无法指定;
离线存储可以动态通知用户进行更新。
4、如何实现
实现:
http://blog.csdn.net/fwwdn/article/details/8082433
机制:
http://www.cnblogs.com/yexiaochai/p/4271834.html
更新:
http://www.oschina.net/question/28_44911?sort=time
websql
http://blog.csdn.net/wjb820728252/article/details/71246522?locationNum=6&fps=1
indexDB
http://blog.csdn.net/wjb820728252/article/details/71246522?locationNum=6&fps=1
大公司里怎样开发和部署前端代码解决强缓存问题?
参考地址:
http://www.zhihu.com/question/20790576
概括一下:
大公司的静态资源优化方案,基本上要实现这么几个东西:
- 配置超长时间的本地缓存 ——节省带宽,提高性能
- 采用内容摘要作为缓存更新依据 ——精确的缓存控制
- 静态资源CDN部署 ——优化网络请求
- 资源发布路径实现非覆盖式发布 ——平滑升级
这篇文章提到的“大公司里怎样开发和部署前端代码”的几个解决方案的进阶关系:
问题1:对于大公司来说,那些变态的访问量和性能指标,将会让前端一点也不“好玩”
答案1:强制浏览器使用本地缓存(cache-control/expires)200(from cache),不要和服务器通信。好了,请求方面的优化已经达到变态级别,
问题2:那问题来了:你都不让浏览器发资源请求了,这缓存咋更新?
答案2:通过更新页面中引用的资源路径,让浏览器主动放弃缓存,加载新资源类似于:
<script src="${context_path}/js/imgSlide.js?v=1.0.1" type="text/javascript"></script>下次上线,把链接地址改成新的版本,就更新资源了,那么新问题来了
问题3:页面引用了3个css,而某次上线只改了其中的a.css,如果所有链接都更新版本,就会导致b.css,c.css的缓存也失效,那岂不是又有浪费了?
答案3:要解决这种问题,必须让url的修改与文件内容关联,也就是说,只有文件内容变化,才会导致相应url的变更,从而实现文件级别的精确缓存控制。这回再有文件修改,就只更新那个文件对应的url了,想到这里貌似很完美了。你觉得这就够了么?
问题4:当我要更新静态资源的时候,同时也会更新html中的引用,如果同时改了页面结构和样式,也更新了静态资源对应的url地址,现在要发布代码上线,那么咱们是先上线页面,还是先上线静态资源?
先部署谁都不成!都会导致部署过程中发生页面错乱的问题。
答案4:解决它也好办,就是实现 非覆盖式发布。用文件的摘要信息来对资源文件进行重命名,把摘要信息放到资源文件发布路径中,这样,内容有修改的资源就变成了一个新的文件发布到线上,不会覆盖已有的资源文件。上线过程中,先全量部署静态资源,再灰度部署页面,整个问题就比较完美的解决了
TypeScript
函数
介绍
函数是JavaScript应用程序的基础。 它帮助你实现抽象层,模拟类,信息隐藏和模块。在TypeScript里,虽然已经支持类,命名空间和模块,但函数仍然是主要的定义 行为的地方。 TypeScript为JavaScript函数添加了额外的功能,让我们可以更容易地使用。
示例说明
函数定义
function max(x: number, y: number): number {
return x > y ? x : y;
}可选参数
function max(x: number, y?: number): number {
if (y) {
return x > y ? x : y;
} else {
return x;
}
}
let result1 = max(2); //ok
let result2 = max(2, 4, 7); //报错
let result3 = max(2, 4); //ok可选参数必须放在必选参数的后面
默认参数
function max(x: number, y: number = 8): number {
if (y) {
return x > y ? x : y;
} else {
return x;
}
}
let result1 = max(5); //ok
let result2 = max(5, undefined); //ok
let result3 = max(5, 3); //ok带默认值的参数不必放在必选参数的后面,但如果默认参数放到了必选参数的前,用户必须显式地传入undefined
function max(x: number = 3, y: number): number {
if (y) {
return x > y ? x : y;
} else {
return x;
}
}
let result1 = max(5); //报错
let result2 = max(undefined, 5); //ok
let result3 = max(5, 7); //ok剩余参数
function sum(result: number = 0, ...restNum: number[]): number {
restNum.forEach((item) => result += item);
return result;
}
let result1 = sum(10, 1, 2, 3, 4); //ok
let a: number[] = [1, 2, 3];
let result2 = sum(undefined, ...a); //ok
let result3 = sum(); //ok剩余参数可以理解为个数不限的可选参数,个数可以为零到任意个
函数重载
编译器会根据参数类型来判断该调用哪个函数。TypeScript的函数重载通过查找重载列表来实现匹配,根据定义的优先顺序来依次匹配。 因此,在定义重载的时候,建议把最精确的定义放在最前面。
function test(input: string);
function test(input: number);
function test(input: any) {
if (typeof input === 'string') {
return `input is string type, ${input}`;
} else if (typeof input === 'number') {
return `input is number type, ${input}`;
}
}
let result1 = test(7);function test(input: any)并不是重载列表的一部分,因此这里只有两个重载:一个是接收字符串另一个接收数字。 以其它参数调用test会产生错误。
类
介绍
传统的JavaScript程序使用函数和基于原型的继承来创建可重用的组件,但对于熟悉使用面向对象方式的程序员来讲就有些棘手,因为他们用的是基于类的继承并且对象是由类构建出来的。 从ECMAScript 2015,也就是ECMAScript 6开始,JavaScript程序员将能够使用基于类的面向对象的方式。
示例说明
class Car {
engine: string;
constructor(engine: string) {
this.engine = engine;
}
drive(distance: number = 100) {
console.log(`A ${this.engine} car runs ${distance}m`);
}
}
let myCar = new Car('petrol');
myCar.drive();继承
使用extends关键字即可方便地实现继承
class MotoCar extends Car {
constructor(engine: string) {
super(engine);
}
}
class Jeep extends Car {
constructor(engine: string) {
super(engine);
}
drive(distance: number) {
console.log(`Jeep...`);
super.drive(distance);
}
}
let tesla = new MotoCar("electricity");
let landRover: Car = new Jeep("petrol");
tesla.drive(); //调用父类的drive方法
landRover.drive(200); //调用子类的的drive方法派生类构造函数必须调用super(),它会执行父类的构造方法。
修饰符
在类中的修饰符可以分为公共(public)、私有(private)、受保护(protected)三种类型,每个成员默认为public,可以被自由地访问。
public修饰符
class Car {
public constructor(public engine: string) {}
public drive(distance: number = 100) {
console.log(`A ${this.engine} car runs ${distance}m`);
}
}
let myCar = new Car('petrol');
myCar.drive();private修饰符
private成员只能在类内部访问
class Car {
constructor(private engine: string) {}
}
let myCar = new Car('petrol');
console.log(myCar.engine); //报错protected修饰符
protected成员能在派生类中和类内部访问
class Car {
constructor(protected engine: string) {}
drive(distance: number = 0) {
console.log(`A ${this.engine} car runs ${distance}m`);
}
}
class MotoCar extends Car {
constructor(engine: string) {
super(engine);
}
drive(distance: number = 50) {
super.drive(distance);
}
}
let tesla = new MotoCar("electricity");
console.log(tesla.engine); //报错
tesla.drive();readonly修饰符
使用readonly关键字将属性设置为只读的。只读属性只能在声明时或构造函数里被初始化。
class Car {
constructor(readonly engine: string) {}
drive(distance: number = 0) {
console.log(`A ${this.engine} car runs ${distance}m`);
}
}
let myCar = new Car("petrol");
myCar.engine = "diesel"; //报错
myCar.drive();readonly VS const
最简单判断该用readonly还是const的方法是看要把它做为变量使用还是做为一个属性。 做为变量使用的话用 const,若做为属性则使用readonly。
静态属性
使用static关键字来定义类的静态成员。类的静态成员存在于类本身而不是类的实例上,如同在实例属性上使用this.前缀来访问属性一样,我们使用类名.来访问静态属性。
class Grid {
static origin = {x: 0, y: 0};
calculateDistance(point: {x: number; y: number;}) {
let xDist = (point.x - Grid.origin.x);
let yDist = (point.y - Grid.origin.y);
return Math.sqrt(xDist * xDist + yDist * yDist) / this.scale;
}
constructor (public scale: number) {}
}
let grid1 = new Grid(1.0);
let grid2 = new Grid(5.0);
console.log(grid1.calculateDistance({x: 10, y: 10}));
console.log(grid2.calculateDistance({x: 10, y: 10}));抽象类
抽像类作为其他派生类的基类使用,一般不会直接被实例化。使用abstract关键字定义抽象类和抽象类内部定义抽象方法。抽象类中的抽象方法不包含具体实现并且必须在派生类中实现。与接口方法相似,两者都是定义方法签名但不包含方法体。
abstract class Person {
abstract speak(): void; //必须在派生类中实现
walking(): void {
console.log('Walking on the road');
}
}
class Male extends Person {
speak(): void {
console.log('How are you?');
}
}
let person: Person; //创建一个抽象类引用
person = new Person(); //报错
person = new Male(); //ok
person.speak();
person.walking();接口
介绍
TypeScript的核心原则之一是对值所具有的结构进行类型检查。 它有时被称做“鸭式辨型法”或“结构性子类型化”。 在TypeScript里,接口的作用就是为这些类型命名和为你的代码或第三方代码定义契约。
接口能够描述JavaScript中对象拥有的各种各样的类型:
- 属性类型
- 函数类型
- 可索引的类型
- 类类型
示例说明
属性类型接口
interface FullName {
firstName: string;
secondName: string;
}
function printName(name: FullName) {
console.log(`${name.firstName} ${name.secondName}`);
}
let myObj = {sex: "Male", firstName: "Jim", secondName: "Lee"};
printName(myObj);类型检查器不会去检查属性的顺序,只要相应的属性存在并且类型也是对的就可以。
- 可选属性
interface FullName {
firstName: string;
secondName?: string;
}
function printName(name: FullName) {
console.log(`${name.firstName} ${name.secondName}`);
}
let myObj = {firstName: "Jim"};
printName(myObj);- 只读属性 readonly
interface Point {
readonly x: number;
readonly y: number;
}
let p1: Point = { x: 10, y: 20 }; //只能在对象创建时修改其值
p1.x = 5; //报错- 只读数组 ReadonlyArray
TypeScript具有ReadonlyArray类型,它与Array相似,可以确保数组创建后再也不能被修改
let arr: ReadonlyArray<number> = [1, 2, 3, 4];
arr[0] = 12; //报错
arr.push(5); //报错
arr.length = 100; //报错函数类型接口
除了描述带有属性的普通对象外,接口也可以描述函数类型。定义函数类型接口时,需要明确定义函数的参数列表和返回值类型,且参数列表的每个参数都要有参数名和类型。
let arr: ReadonlyArray<number> = [1, 2, 3, 4];
arr[0] = 12; //报错
arr.push(5); //报错
arr.length = 100; //报错可索引类型接口
可索引类型接口用来描述能够“通过索引得到”的类型,比如a[10]或objMap[“daniel”]。 它包含一个索引签名,表示用来索引的类型和返回值类型,即通过特定的索引来得到指定类型的返回值。
索引签名支持字符串和数字两种数据类型。
interface StringArray {
[index: number]: string;
}
interface StringObject {
[index: string]: string;
}
let myArray: StringArray;
myArray = ["Bob", "Fred"];
console.log(myArray[0]);
let myObject: StringObject;
myObject = {"name": "David"};
console.log(myObject["name"]);类类型接口
类类型接口用来规范一个类的内容。
interface ClockInterface {
currentTime: Date;
setTime(d: Date);
}
class Clock implements ClockInterface {
currentTime: Date;
setTime(d: Date) {
this.currentTime = d;
}
showTime() {
console.log(this.currentTime);
}
}
let clock = new Clock();
clock.setTime(new Date(2017, 9, 1));
clock.showTime();继承接口
和类一样,接口也可以相互继承。 这让我们能够从一个接口里复制成员到另一个接口里,可以更灵活地将接口分割到可重用的模块里。
一个接口可以继承多个接口,创建出多个接口的合成接口。
interface Shape {
color: string;
}
interface PenStroke {
penWidth: number;
}
interface Square extends Shape, PenStroke {
sideLength: number;
}
let square: Square;
square = {color: "blue", sideLength: 10, penWidth: 5.0};
console.log(square);泛型
介绍
软件工程中,有时需要支持不特定的数据类型,而泛型就是用来实现这样的效果。
在像C#和Java这样的语言中,可以使用泛型来创建可重用的组件,一个组件可以支持多种类型的数据。 这样用户就可以以自己的数据类型来使用组件。
示例说明
interface Icalc<T> {
add(): T;
}
class Calc implements Icalc<number> {
constructor(public x: number, public y: number) { }
add() {
return this.x + this.y;
}
}
let myAdd = new Calc(5, 8);
let result = myAdd.add();概述
TypeScript是一种由微软开发的自由和开源的编程语言,由C#语言之父安德斯•海尔斯伯格主导开发的,2012年微软发布了首个公开版本。TypeScript是JavaScript的超集,它扩展了JavaScript的语法,遵循ES6的规范,因此现有的JavaScript代码无需做任何修改便可与TypeScript一起使用,要运行TypeScript程序需先编译成浏览器能识别的JavaScript代码,编译后可以在任何浏览器、任何操作系统、任何计算机运行。它添加了可选的静态类型,提供了类、接口和模块来帮助构建组件,能够帮助开发者编写出更出色的JavaScript代码。
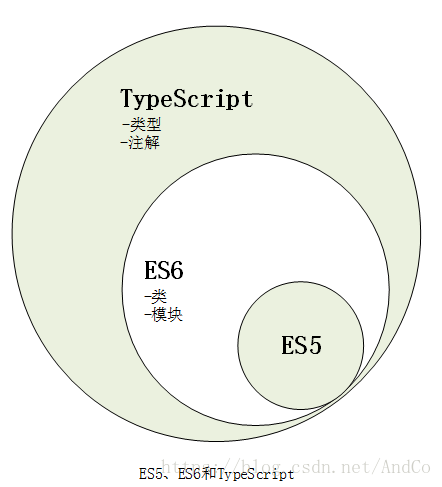
使用TypeScript的好处
一、静态类型
1.1、类型批注
TypeScript是静态类型语言,需要编译,拥有编译时类型检查的特性,在编译过程中,到达运行时间前可以捕获所有类型的错误。
TypeScript的类型是设计为批注,而不是定义,所以和C#的类型写在前面不同,类型是以可选的形式写在后面的。
let foo: string;foo = true; //报错1.2、IDE支持
比如VisualStudio,编写TypeScript文件时,就比编写JavaScript要聪明的多,方便开发更智能的自动完成功能,实际上TypeScript的各种开发工具都做得很不错。这就是静态类型带来的好处。
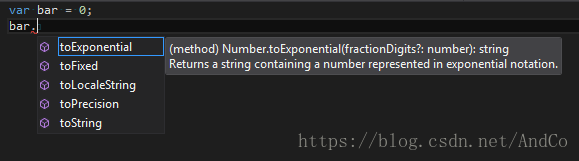
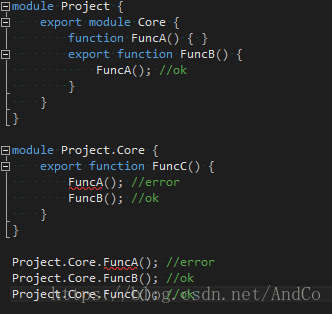
二、模块化
由于模块、命名空间和强大的面向对象编程支持,使构建大型复杂应用程序的代码库更加容易。
利用TypeScript的关键词module,可以达到类似于命名空间的效果,而export可以控制是否被外部访问。
编译
一. 本地方式
1、通过npm安装
npm install -g typescript
2、构建一个TypeScript文件,文件扩展名为.ts
3、编译代码
在命令行上,运行TypeScript编译器
tsc abc.ts
此时会在同个目录下生成一个同名js文件abc.js,该文件中的代码是基于ES5标准的,可以直接在浏览器中运行。
二、在线方式
http://www.typescriptlang.org/play/index.html
TypeScript官网
英文:http://www.typescriptlang.org/
中文:https://tslang.cn/
官网Vue示例
<!-- src/components/Hello.vue -->
<template>
<div>
<div class="greeting">Hello {{name}}{{exclamationMarks}}</div>
<button @click="decrement">-</button>
<button @click="increment">+</button>
</div>
</template>
<script lang="ts">
import Vue from "vue";
export default Vue.extend({
props: ['name', 'initialEnthusiasm'],
data() {
return {
enthusiasm: this.initialEnthusiasm,
}
},
methods: {
increment() { this.enthusiasm++; },
decrement() {
if (this.enthusiasm > 1) {
this.enthusiasm--;
}
},
},
computed: {
exclamationMarks(): string {
return Array(this.enthusiasm + 1).join('!');
}
}
});
</script>
<style>
.greeting {
font-size: 20px;
}
</style>完整示例参考: https://github.com/Barry215/Gobang
基本数据类型
介绍
在TypeScript中,提供了以下基础数据类型:
- 布尔类型(boolean)
- 数字类型(number)
- 字符串类型(string)
- 数组类型(array)
- 元组类型(tuple)
- 枚举类型(enum)
- 任意值类型(any)
- null和undefined
- void类型
- never类型
示例说明
https://tslang.cn/docs/handbook/basic-types.html
ES5,css3新特性
WebSocket
WebSocket是Html5一系列新的API,或者说新规范,新技术中的一部分。
定义
WebSocket协议是基于TCP的一种新的网络协议。它实现了浏览器与服务器全双工(full-duplex)通信——允许服务器主动发送信息给客户端。
WebSocket通信协议于2011年被IETF定为标准RFC 6455。
- WebSocket是HTML5出的东西(协议),也就是说HTTP协议没有变化
首先HTTP有1.1和1.0之说,也就是所谓的keep-alive,把多个HTTP请求合并为一个,但是Websocket其实是一个新协议,跟HTTP协议基本没有关系,只是为了兼容现有浏览器的握手规范而已,也就是说它是HTTP协议上的一种补充。
WebSocket 本质上跟 HTTP 完全不一样,只不过为了兼容性,WebSocket 的握手是以 HTTP 的形式发起的,如果服务器或者代理不支持 WebSocket,它们会把这当做一个不认识的 HTTP 请求从而优雅地拒绝掉。
产生背景
简单的说,WebSocket协议之前,双工通信和长连接都是通过某种手段模拟实现的。
模拟全双工通信
为了在半双工HTTP的基础上模拟全双工通信,目前的许多解决方案都是使用了两个连接:一个用于下行数据流,另一个用于上行数据流。HTTP 协议中所谓的 keep-alive connection,就是指在一次 TCP 连接中完成多个 HTTP 请求,但是对每个请求仍然要单独发 header,这导致了效率低下。
模拟长连接
实现实时信息传递的长连接,一般会用long poll 和 ajax轮询。通常会造成HTTP轮询的滥用: 客户端(一般就是浏览器)不断主动的向服务器发 HTTP 请求查询是否有新数据。
ajax轮询
ajax轮询 的原理非常简单,让浏览器隔个几秒就发送一次请求,询问服务器是否有新信息。
场景再现:
客户端:啦啦啦,有没有新信息(Request)
服务端:没有(Response)
客户端:啦啦啦,有没有新信息(Request)
服务端:没有。。(Response)
客户端:啦啦啦,有没有新信息(Request)
服务端:你好烦啊,没有啊。。(Response)
客户端:啦啦啦,有没有新消息(Request)
服务端:好啦好啦,有啦给你。(Response)
客户端:啦啦啦,有没有新消息(Request)
服务端:。。。。。没。。。。没。。。没有(Response)—— loop
long poll
long poll 其实原理跟 ajax轮询 差不多,都是采用轮询的方式,不过采取的是阻塞模型(一直打电话,没收到就不挂电话),也就是说,客户端发起连接后,如果没消息,就一直不返回Response给客户端。直到有消息才返回,返回完之后,客户端再次建立连接,周而复始。
场景再现
客户端:啦啦啦,有没有新信息,没有的话就等有了才返回给我吧(Request)
服务端:额。。 等待到有消息的时候。。来 给你(Response)
客户端:啦啦啦,有没有新信息,没有的话就等有了才返回给我吧(Request) -loop
上面这两种都是非常消耗资源的。因为HTTP是非状态性的,服务器和客户端要不断地建立、关闭HTTP协议(HTTP协议的被动性),服务端不能主动联系客户端,只能有客户端发起。除了真正的数据部分外,每次都要在 HTTP header中重新传输identity info(鉴别信息),信息交换效率很低。
一个更简单的解决方案是使用单个TCP连接双向通信。这就是WebSocket协议所提供的功能。结合WebSocket API ,WebSocket协议提供了一个用来替代HTTP轮询实现网页到远程主机的双向通信的方法。
优点
持久化的协议
WebSocket 解决的第一个问题是,通过第一个 HTTP request 建立了 TCP 连接之后,之后的交换数据都不需要再发 HTTP request了,使得这个长连接变成了一个真.长连接。他解决了HTTP的被动性,当服务器完成协议升级后(HTTP->Websocket),服务端就可以主动推送信息给客户端啦。
使用WebSockets,上面的情景可以做如下修改。
客户端:啦啦啦,我要建立Websocket协议,需要的服务:chat,Websocket协议版本:17(HTTP Request)
服务端:ok,确认,已升级为Websocket协议(HTTP Protocols Switched)
客户端:麻烦你有信息的时候推送给我噢。。
服务端:ok,有的时候会告诉你的。
服务端:balabalabalabala
服务端:balabalabalabala
服务端:哈哈哈哈哈啊哈哈哈哈
服务端:笑死我了哈哈哈哈哈哈哈
就变成了这样,只需要经过一次HTTP请求,就可以做到源源不断的信息传送了。这样的协议解决了上面同步有延迟,而且还非常消耗资源的这种情况。
全双工通信
WebSocket 还是一个双通道的连接,在同一个 TCP 连接上既可以发也可以收信息。
缺点
- 对开发者要求高了许多。
对前端开发者,往往要具备数据驱动使用javascript的能力,且需要维持住ws连接(否则消息无法推送);
对后端开发者而言,难度增大了很多,一是长连接需要后端处理业务的代码更稳定(不要随便把进程和框架都crash掉),二是推送消息相对复杂一些,三是成熟的http生态下有大量的组件可以复用,websocket则太新了一点。 - 服务器长期维护长连接需要一定的成本。
- 浏览器可能不一定支持。
运行机制
传统HTTP客户端与服务器请求响应模式如下图所示:
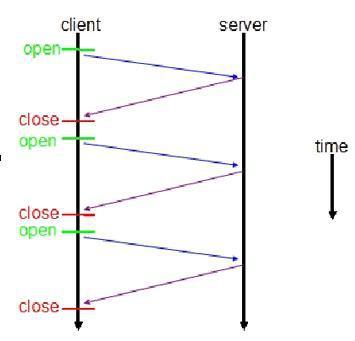
WebSocket模式客户端与服务器请求响应模式如下图:
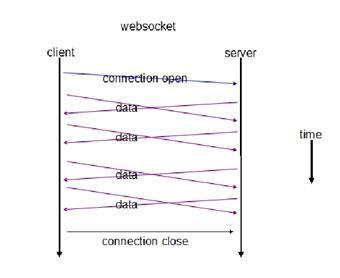
一旦WebSocket连接建立后,后续数据都以帧序列的形式传输。在客户端断开WebSocket连接或Server端中断连接前,不需要客户端和服务端重新发起连接请求。在海量并发及客户端与服务器交互负载流量大的情况下,极大的节省了网络带宽资源的消耗,有明显的性能优势,且客户端发送和接受消息是在同一个持久连接上发起,实时性优势明显。
握手协议例子
Websocket是基于HTTP协议的,或者说借用了HTTP的协议来完成一部分握手,也就是说,在握手阶段是一样的。
首先我们来看个典型的Websocket握手。
Request Headers
GET /chat HTTP/1.1
Host: server.example.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: x3JJHMbDL1EzLkh9GBhXDw==
Sec-WebSocket-Protocol: chat, superchat
Sec-WebSocket-Version: 13
Origin: http://example.com这段类似HTTP协议的握手请求中,多了几个东西。
Upgrade: websocket
Connection: Upgrade这个就是Websocket的核心了,告诉Apache、Nginx等服务器:注意啦,窝发起的是Websocket协议,快点帮我找到对应的助理处理~不是那个老土的HTTP。
Sec-WebSocket-Key: x3JJHMbDL1EzLkh9GBhXDw==
Sec-WebSocket-Protocol: chat, superchat
Sec-WebSocket-Version: 13- Sec-WebSocket-Key 是一个Base64 encode的值,这个是浏览器随机生成的,告诉服务器:泥煤,不要忽悠窝,我要验证尼是不是真的是Websocket助理。
- Sec_WebSocket-Protocol 是一个用户定义的字符串,用来区分同URL下,不同的服务所需要的协议。简单理解:我要服务A,别搞错啦~
- Sec-WebSocket-Version 是告诉服务器所使用的Websocket Draft(协议版本),在最初的时候,Websocket各种奇奇怪怪的协议都有,而且还有很多奇奇怪怪不同的东西,什么Firefox和Chrome用的不是一个版本之类的,不过现在还好,已经定下来啦~
- 另外,可能包括Sec-WebSocket-Extensions, 协议扩展, 某类协议可能支持多个扩展,通过它可以实现协议增强。
然后服务器会返回下列东西,表示已经接受到请求, 成功建立Websocket啦!
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: HSmrc0sMlYUkAGmm5OPpG2HaGWk=
Sec-WebSocket-Protocol: chat- Upgrade: websocket
Connection: Upgrade
告诉客户端即将升级的是Websocket协议。 - Sec-WebSocket-Accept 这个则是经过服务器确认,并且加密过后的 Sec-WebSocket-Key。服务器:好啦好啦,知道啦,给你看我的ID CARD来证明行了吧。。
- Sec-WebSocket-Protocol 则是表示最终使用的协议。至此,HTTP已经完成它所有工作了,接下来就是完全按照Websocket协议进行了。
HTML5 Web Socket API
基本API语句如下:
创建对象
var ws = new WebSocket(url,name);
url为WebSocket服务器的地址,name为发起握手的协议名称,为可选择项。
发送文本消息
ws.send(msg);
msg为文本消息,对于其他类型的可以通过二进制形式发送。
接收消息
ws.onmessage = (function(){…})();
错误处理
ws.onerror = (function(){…})();
关闭连接
ws.close();
浏览器以及语言支持
所有主流浏览器都支持RFC6455。但是具体的WebSocket版本有区别。websocket api在浏览器端的广泛实现似乎只是一个时间问题了。
C C++ Node.js php jetty netty ruby Kaazing nginx python Tomcat Django erlang netty .net等语言均可以用来实现支持WebSocket的服务器。对于JAVA开发人员Tomcat是最熟悉的,在Tomcat8中已经实现了WebSocket API 1.0。 值得注意的是服务器端没有标准的api, 各个实现都有自己的一套api, 并且tcp也没有类似的提案, 所以使用websocket开发服务器端有一定的风险.可能会被锁定在某个平台上或者将来被迫升级。
许多语言、框架和服务器都提供了 WebSocket 支持,例如:
- 基于 C 的 libwebsocket.org
- 基于 Node.js 的 Socket.io
- 基于 Python 的 ws4py
- 基于 C++ 的 WebSocket++
- Apache 对 WebSocket 的支持: Apache Module mod_proxy_wstunnel
- Nginx 对 WebSockets 的支持: NGINX as a WebSockets Proxy 、 NGINX Announces Support for WebSocket Protocol 、WebSocket proxying
- lighttpd 对 WebSocket 的支持:mod_websocket
ES5,ES6对比研究
js的前世今生
JavaScript
JavaScript一种直译式脚本语言,是一种动态类型、弱类型、基于原型的语言,内置支持类型。它的解释器被称为JavaScript引擎,为浏览器的一部分,广泛用于客户端的脚本语言,最早是在HTML(标准通用标记语言下的一个应用)网页上使用,用来给HTML网页增加动态功能。
在1995年时,由Netscape公司的Brendan Eich,在网景导航者浏览器上首次设计实现而成。因为Netscape与Sun合作,Netscape管理层希望它外观看起来像Java,因此取名为JavaScript。但实际上它的语法风格与Self及Scheme较为接近。为了取得技术优势,微软推出了JScript,CEnvi推出ScriptEase,与JavaScript同样可在浏览器上运行。为了统一规格,因为JavaScript兼容于ECMA标准,因此也称为ECMAScript。
ECMAScript 和 JavaScript 的关系
一个常见的问题是,ECMAScript 和 JavaScript 到底是什么关系?
要讲清楚这个问题,需要回顾历史。1996年11月,JavaScript 的创造者 Netscape 公司,决定将 JavaScript 提交给国际标准化组织ECMA,希望这种语言能够成为国际标准。次年,ECMA 发布262号标准文件(ECMA-262)的第一版,规定了浏览器脚本语言的标准,并将这种语言称为 ECMAScript,这个版本就是1.0版。
该标准从一开始就是针对 JavaScript 语言制定的,但是之所以不叫 JavaScript,有两个原因。一是商标,Java 是 Sun 公司的商标,根据授权协议,只有 Netscape 公司可以合法地使用 JavaScript 这个名字,且 JavaScript 本身也已经被 Netscape 公司注册为商标。二是想体现这门语言的制定者是 ECMA,不是 Netscape,这样有利于保证这门语言的开放性和中立性。
因此,ECMAScript 和 JavaScript 的关系是,前者是后者的规格,后者是前者的一种实现(另外的 ECMAScript 方言还有 Jscript 和 ActionScript)。日常场合,这两个词是可以互换的。(以上摘自阮一峰《ES6入门》)
ES6 与 ECMAScript 2015 的关系
ECMAScript 2015(简称 ES2015)这个词,也是经常可以看到的。它与 ES6 是什么关系呢?
2011年,ECMAScript 5.1版发布后,就开始制定6.0版了。因此,ES6 这个词的原意,就是指 JavaScript 语言的下一个版本。
标准委员会最终决定,标准在每年的6月份正式发布一次,作为当年的正式版本。接下来的时间,就在这个版本的基础上做改动,直到下一年的6月份,草案就自然变成了新一年的版本。这样一来,就不需要以前的版本号了,只要用年份标记就可以了。
ES6 的第一个版本,就这样在2015年6月发布了,正式名称就是《ECMAScript 2015标准》(简称 ES2015)。2016年6月,小幅修订的《ECMAScript 2016标准》(简称 ES2016)如期发布,这个版本可以看作是 ES6.1 版,因为两者的差异非常小(只新增了数组实例的includes方法和指数运算符),基本上是同一个标准。根据计划,2017年6月发布 ES2017 标准。
因此,ES6 既是一个历史名词,也是一个泛指,含义是5.1版以后的 JavaScript 的下一代标准,涵盖了ES2015、ES2016、ES2017等等,而ES2015 则是正式名称,特指该年发布的正式版本的语言标准。本书中提到 ES6 的地方,一般是指 ES2015 标准,但有时也是泛指“下一代 JavaScript 语言”。(以上摘自阮一峰《ES6入门》)
ECMA
这个组织的目标是评估,开发和认可电信和计算机标准。大家决定把ECMA的总部设在日内瓦是因为这样能够让它与其它与之协同工作的标准制定组织更接近一些,比方说国际标准化组织(ISO)和国际电子技术协会(IEC)。ECMA是“European Computer Manufactures Association”的缩写,中文称欧洲计算机制造联合会。是1961年成立的旨在建立统一的电脑操作格式标准—包括程序语言和输入输出的组织。
ES5,ES6对比
ECMAScript6入门:http://es6.ruanyifeng.com/#README
ES5传送门:http://www.w3school.com.cn/js/index.asp
MDN火狐开发者网络中心:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript
ES6新增:
let 和 const 命令
Symbol
Set 和 Map 数据结构
变量的解构赋值
Decorator
Class 的基本语法
Reflect
Proxy
Promise 对象
Generator 函数的语法
Iterator 和 for…of 循环
ES6各种扩展:
字符串的扩展:模板字符串
正则的扩展:RegExp 构造函数
数值的扩展:Number.parseInt(), Number.parseFloat()
数组的扩展:扩展运算符,Arrary.from(),includes()
函数的扩展:箭头函数
对象的扩展:Object.assign()
与js语言相关:
模块化与Module 的加载实现
1.js的模块化,服务器端首先实现
2.浏览器端实现模块化:requirejs,seajs
3.CMD,AMD,CommonJS与ES6三个模块化规范的差异(主要是commonjs):
a.CommonJS 模块是运行时加载,ES6 模块是编译时输出接口
b.CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。
4.ES6模块化:
编程风格
读懂规格
二进制数组
SIMD
推荐:你所不知道的js
JavaScript单线程和异步
JavaScript运行机制
同步与异步
介绍异步之前,回顾一下,所谓同步编程,就是计算机一行一行按顺序依次执行代码,当前代码任务耗时执行会阻塞后续代码的执行。
同步编程,即是一种典型的请求-响应模型,当请求调用一个函数或方法后,需等待其响应返回,然后执行后续代码。
一般情况下,同步编程,代码按序依次执行,能很好的保证程序的执行,但是在某些场景下,比如读取文件内容,或请求服务器接口数据,需要根据返回的数据内容执行后续操作,读取文件和请求接口直到数据返回这一过程是需要时间的,网络越差,耗费时间越长,如果按照同步编程方式实现,在等待数据返回这段时间,JavaScript是不能处理其他任务的,此时页面的交互,滚动等任何操作也都会被阻塞,这显然是及其不友好,不可接受的,而这正是需要异步编程大显身手的场景,如下图,耗时任务A会阻塞任务B的执行,等到任务A执行完才能继续执行B:

异步编程,不同于同步编程的请求-响应模式,其是一种事件驱动编程,请求调用函数或方法后,无需立即等待响应,可以继续执行其他任务,而之前任务响应返回后可以通过状态、通知和回调来通知调用者。
javascript实现异步
JavaScript执行异步任务时,不需要等待响应返回,可以继续执行其他任务,而在响应返回时,会得到通知,执行回调或事件处理程序
1:首要要知道JavaScript语言是单线程的:
JavaScript语言的一大特点就是单线程,也就是说,同一个时间只能做一件事。那么,为什么JavaScript不能有多个线程呢?这样能提高效率啊。
JavaScript的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变。
为了利用多核CPU的计算能力,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质。
2:事件和回调函数
“任务队列”是一个事件的队列(也可以理解成消息的队列),IO设备完成一项任务,就在”任务队列”中添加一个事件,表示相关的异步任务可以进入”执行栈”了。主线程读取”任务队列”,就是读取里面有哪些事件。
“任务队列”中的事件,除了IO设备的事件以外,还包括一些用户产生的事件(比如鼠标点击、页面滚动等等)。只要指定过回调函数,这些事件发生时就会进入”任务队列”,等待主线程读取。
所谓”回调函数”(callback),就是那些会被主线程挂起来的代码。异步任务必须指定回调函数,当主线程开始执行异步任务,就是执行对应的回调函数。
3:事件循环(Event Loop)
以下是event-loop的简单介绍
http://www.ruanyifeng.com/blog/2013/10/event_loop.html
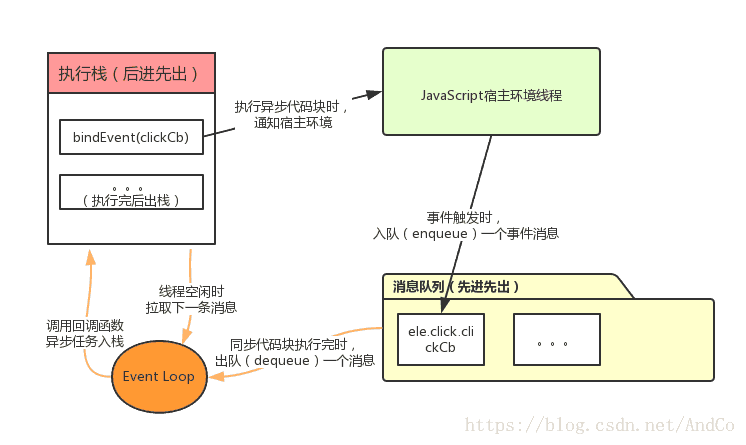
(1)所有同步任务都在主线程上执行,形成一个执行栈
(2)主线程之外,还存在一个”任务队列”。只要异步任务有了运行结果,就在”任务队列”之中放置一个事件。
(3)一旦”执行栈”中的所有同步任务执行完毕,系统就会读取”任务队列”,看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
(4)主线程不断重复上面的第三步。
/*示例*/
//以下是在引入jq环境下运行的脚本
console.log(new Date()) //打印当前电脑时间
console.time("计数") //计数开始
console.log("通知请求线程进行加载,请求成功将把回调push到消息队列中")
$.ajax({
type: "get",
async: false,
url: "https://biaozhunshijian.51240.com/web_system/51240_com_www/system/file/biaozhunshijian/time.js/?v=1501641667339",
dataType: "jsonp",
jsonp: "callback",
jsonpCallback:"baidu_time",//自定义的jsonp回调函数名称,默认为jQuery自动生成的随机函数名,也可以写"?",jQuery会自动为你处理数据
success: function(json){
console.timeEnd("计数")
console.log(new Date(json.time))
},
error: function(){
alert('fail');
}
});
for(var i=0;i<90000;i++){ //当前js线程一直在做循环 只有当js线程空余下来 才会去读取消息队列中的回调函数
console.log("执行")
}4:常见的异步场景
1:http请求
2:DOM事件(事件绑定)
3:定时器
消息队列中除了放置异步任务的事件,”任务队列”还可以放置定时事件,即指定某些代码在多少时间之后执行。这叫做”定时器”(timer)功能,也就是定时执行的代码。
定时器功能主要由setTimeout()和setInterval()这两个函数来完成,它们的内部运行机制完全一样,区别在于前者指定的代码是一次性执行,后者则为反复执行。
javascript线程和浏览器线程的关系??
浏览器是多线程的
Javascript是单线程的
javascript引擎线程是浏览器多个线程中的一个,它本身是单线程的。浏览器还包括很多其他线程,如GUI渲染线程,浏览器事件触发线程,Http请求线程等。
js可以操作DOM元素,进而会影响到GUI的渲染结果,因此JS引擎线程与GUI渲染线程是互斥的。也就是说当JS引擎线程处于运行状态时,GUI渲染线程将处于冻结状态。
Promise的简单分析
1:官方解释
Promise 是异步编程的一种解决方案,比传统的解决方案——回调函数和事件——更合理和更强大。它由社区最早提出和实现,ES6 将其写进了语言标准,统一了用法,原生提供了Promise对象。
new Promise(function(resolve,reject){
console.log('Pending') //此时的promise的状态是正在执行 Pending
resolve(); //代表状态变成了 ‘resolve’ 将执行resolve的对应函数
//reject(); //代表状态变成了 是 ‘reject’ 将执行reject的对应函数
}).then(function(){ //直接在实例后点then(); 分别对应resolve 和reject函数
console.log('resolve')
},function(){
console.log('reject')
}) //promise的状态一旦发生改变 就不可逆Promise实例生成以后,可以用then方法分别指定Resolved状态和Rejected状态的回调函数。
2:ES5.0实现Promise
function MyPromise(fn) { //声明一个构造函数
this.value;
this.status = 'pending'; //默认状态是pending状态
this.resolveFunc = function() {};
this.rejectFunc = function() {};
fn(this.resolve.bind(this), this.reject.bind(this)); //执行传进来的函数 分别给与二个函数名提供调用
}
MyPromise.prototype.resolve = function(val) { //在原型上增加resolve方法
var self = this;
if (this.status == 'pending') {
this.status = 'resolved';
this.value=val;
setTimeout(function() {
self.resolveFunc(self.value);
}, 0);
}
}
MyPromise.prototype.reject = function(val) { //在原型上增加reject方法
var self = this;
if (this.status == 'pending') {
this.status = 'rejected';
this.value=val;
setTimeout(function() {
self.rejectFunc(self.value);
}, 0);
}
}
MyPromise.prototype.then = function(resolveFunc, rejectFunc) { //在原型上增加then方法
this.resolveFunc = resolveFunc;
this.rejectFunc = rejectFunc;
}