定义cell
在很多用到rnn的paper中我们会看到类似的图:
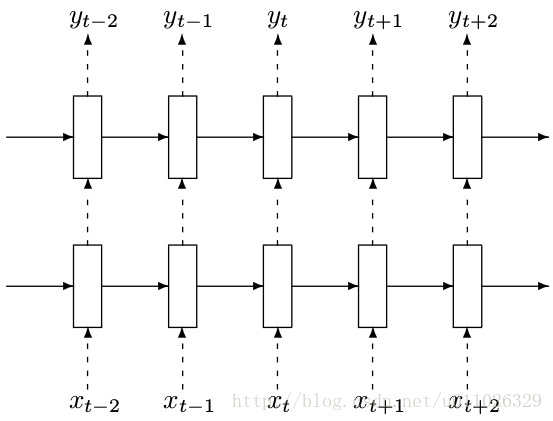
这其中的每个小长方形就表示一个cell。每个cell中又是一个略复杂的结构,如下图:
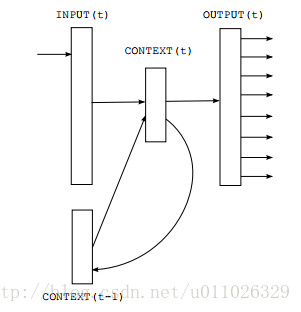
图中的context就是一个cell结构,可以看到它接受的输入有input(t),context(t-1),然后输出output(t),比如像我们这个任务中,用到多层堆叠的rnn cell的话,也就是当前层的cell的output还要作为下一层cell的输入,因此可推出每个cell的输入和输出的shape是一样。如果输入的shape=(None, n),加上context(t-1)同时作为输入部分(则输入变为shape=(None, 2n)),因此可以知道W的shape=(2n, n)。
说了这么多,其实我只是想表达一个重点,就是
别小看那一个小小的cell,它并不是只有1个neuron unit,而是n个hidden units
因此,我们注意到tensorflow中定义一个cell(BasicRNNCell/BasicLSTMCell/GRUCell/RNNCell/LSTMCell)结构的时候需要提供的一个参数就是hidden_units_size。
(1)BasicLSTMCell
Inherits From: RNNCell
Aliases:
- Class
tf.contrib.rnn.BasicLSTMCell - Class
tf.nn.rnn_cell.BasicLSTMCell
Basic LSTM recurrent network cell.
We add forget_bias (default: 1) to the biases of the forget gate in order to reduce the scale of forgetting in the beginning of the training.
It does not allow cell clipping, a projection layer, and does not use peep-hole connections: it is the basic baseline.
For advanced models, please use the full tf.nn.rnn_cell.LSTMCell that follows.
初始化:
__init__
__init__(
num_units,
forget_bias=1.0,
state_is_tuple=True,
activation=None,
reuse=None
)
Initialize the basic LSTM cell.
Args:
- num_units: int, The number of units in the LSTM cell.
- forget_bias: float, The bias added to forget gates (see above). Must set to
0.0manually when restoring from CudnnLSTM-trained checkpoints. - state_is_tuple: If True, accepted and returned states are 2-tuples of the
c_stateandm_state. If False, they are concatenated along the column axis. The latter behavior will soon be deprecated. - activation: Activation function of the inner states. Default:
tanh. - reuse: (optional) Python boolean describing whether to reuse variables in an existing scope. If not
True, and the existing scope already has the given variables, an error is raised.
(2)state_is_tuple=True是什么
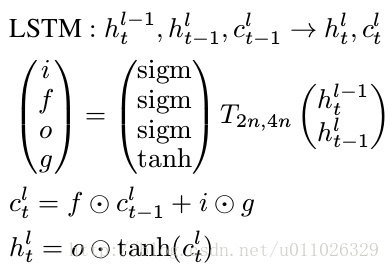
可以看到,每个lstm cell在t时刻都会产生两个内部状态
和 ,这两个状态在tensorflow中都要记录,记住这个就好理解了。
如果state_is_tuple=True,那么上面我们讲到的状态 和 就是分开记录,放在一个tuple中,如果这个参数没有设定或设置成False,两个状态就按列连接起来,成为[batch, 2n] (n是hidden units个数)返回。官方说这种形式马上就要被deprecated了,所有我们在使用LSTM的时候要加上state_is_tuple=True
因 Tensorflow 版本升级原因, state_is_tuple=True 将在之后的版本中变为默认. 对于 lstm 来说, state可被分为(c_state, h_state).
(3)forget_bias是什么
forget_bias (默认值为1)到遗忘门的偏置,为了减少在开始训练时遗忘的规模。
tf.nn.static_rnn
Aliases:
tf.contrib.rnn.static_rnntf.nn.static_rnn
static_rnn(
cell,
inputs,
initial_state=None,
dtype=None,
sequence_length=None,
scope=None
)Creates a recurrent neural network specified by RNNCell cell.
The simplest form of RNN network generated is:
state = cell.zero_state(...)
outputs = []
for input_ in inputs:
output, state = cell(input_, state)
outputs.append(output)
return (outputs, state)Args:
- cell: An instance of RNNCell.
- inputs: A length T list of inputs, each a
Tensorof shape[batch_size, input_size], or a nested tuple of such elements. - initial_state: (optional) An initial state for the RNN. If
cell.state_sizeis an integer, this must be aTensorof appropriate type and shape[batch_size, cell.state_size]. Ifcell.state_sizeis a tuple, this should be a tuple of tensors having shapes[batch_size, s] for s in cell.state_size. - dtype: (optional) The data type for the initial state and expected output. Required if initial_state is not provided or RNN state has a heterogeneous dtype.
- sequence_length: Specifies the length of each sequence in inputs. An int32 or int64 vector (tensor) size
[batch_size], values in[0, T). - scope: VariableScope for the created subgraph; defaults to “rnn”.
Returns:
A pair (outputs, state) where:
- outputs is a length T list of outputs (one for each input), or a nested tuple of such elements.
- state is the final state
tf.nn.dynamic_rnn
dynamic_rnn(
cell,
inputs,
sequence_length=None,
initial_state=None,
dtype=None,
parallel_iterations=None,
swap_memory=False,
time_major=False,
scope=None
)Args:
- cell: An instance of RNNCell.
- inputs: The RNN inputs. If
time_major == False(default), this must be aTensorof shape:[batch_size, max_time, ...], or a nested tuple of such elements. Iftime_major == True, this must be aTensorof shape:[max_time, batch_size, ...], or a nested tuple of such elements. This may also be a (possibly nested) tuple of Tensors satisfying this property. The first two dimensions must match across all the inputs, but otherwise the ranks and other shape components may differ. In this case, input tocellat each time-step will replicate the structure of these tuples, except for the time dimension (from which the time is taken). The input tocellat each time step will be aTensoror (possibly nested) tuple of Tensors each with dimensions[batch_size, ...]. - sequence_length: (optional) An int32/int64 vector sized
[batch_size]. Used to copy-through state and zero-out outputs when past a batch element’s sequence length. So it’s more for correctness than performance. - initial_state: (optional) An initial state for the RNN. If
cell.state_sizeis an integer, this must be aTensorof appropriate type and shape[batch_size, cell.state_size]. Ifcell.state_sizeis a tuple, this should be a tuple of tensors having shapes[batch_size, s] for s in cell.state_size. - dtype: (optional) The data type for the initial state and expected output. Required if initial_state is not provided or RNN state has a heterogeneous dtype.
- parallel_iterations: (Default: 32). The number of iterations to run in parallel. Those operations which do not have any temporal dependency and can be run in parallel, will be. This parameter trades off time for space. Values >> 1 use more memory but take less time, while smaller values use less memory but computations take longer.
- swap_memory: Transparently swap the tensors produced in forward inference but needed for back prop from GPU to CPU. This allows training RNNs which would typically not fit on a single GPU, with very minimal (or no) performance penalty.
- time_major: The shape format of the
inputsandoutputsTensors. If true, theseTensorsmust be shaped[max_time, batch_size, depth]. If false, theseTensorsmust be shaped[batch_size, max_time, depth]. Usingtime_major = Trueis a bit more efficient because it avoids transposes at the beginning and end of the RNN calculation. However, most TensorFlow data is batch-major, so by default this function accepts input and emits output in batch-major form. - scope: VariableScope for the created subgraph; defaults to “rnn”.
Returns:
A pair (outputs, state) where:
outputs: The RNN output
Tensor.If time_major == False (default), this will be a
Tensorshaped:[batch_size, max_time, cell.output_size].If time_major == True, this will be a
Tensorshaped:[max_time, batch_size, cell.output_size].Note, if
cell.output_sizeis a (possibly nested) tuple of integers orTensorShapeobjects, thenoutputswill be a tuple having the same structure ascell.output_size, containing Tensors having shapes corresponding to the shape data incell.output_size.state: The final state. If
cell.state_sizeis an int, this will be shaped[batch_size, cell.state_size]. If it is aTensorShape, this will be shaped[batch_size] + cell.state_size. If it is a (possibly nested) tuple of ints orTensorShape, this will be a tuple having the corresponding shapes. If cells areLSTMCellsstatewill be a tuple containing aLSTMStateTuplefor each cell.
如果使用tf.nn.dynamic_rnn(cell, inputs), 我们要确定 inputs 的格式. tf.nn.dynamic_rnn 中的 time_major 参数会针对不同 inputs 格式有不同的值.
- 如果
inputs为 (batches, steps, inputs) ==>time_major=False; - 如果
inputs为 (steps, batches, inputs) ==>time_major=True;
initial_state
# 使用 basic LSTM Cell.
lstm_cell = tf.contrib.rnn.BasicLSTMCell(n_hidden_units, forget_bias=1.0, state_is_tuple=True)
# 初始化全零 state
init_state = lstm_cell.zero_state(batch_size, dtype=tf.float32) zero_state
zero_state(
batch_size,
dtype
)
Return zero-filled state tensor(s).
Args:
- batch_size: int, float, or unit Tensor representing the batch size.
- dtype: the data type to use for the state.
Returns:
If state_size is an int or TensorShape, then the return value is a N-D tensor of shape [batch_size x state_size] filled with zeros.
If state_size is a nested list or tuple, then the return value is a nested list or tuple (of the same structure) of 2-D tensors with the shapes [batch_size x s] for each s in state_size.
static_rnn与dynamic_rnn的区别
batch_size = 128
n_inputs = 28 # MNIST data input (img shape: 28*28)
n_steps = 28 # time steps
n_hidden_units = 128 # neurons in hidden layer
n_classes = 10 # MNIST classes (0-9 digits)输入不同:
static_rnn输入为list, a list of ‘n_steps’ tensors of shape (batch_size, n_input)
dynamic_rnn输入为tensor,a tensor of shape (batch_size, n_steps, n_input)或者 (n_steps, batch_size, n_input)
输入不同:
static_rnn输出为list, a list of ‘n_steps’ tensors of shape (batch_size, n_hidden_units)
dynamic_rnn输入为tensor,a tensor of shape (batch_size, n_steps, n_hidden_units)或者 (n_steps, batch_size, n_hidden_units)
dynamic_rnn可以表示多层
dynamic-rnn可以允许不同batch的sequence length不同,但rnn不能。

示例
static_rnn
""" Recurrent Neural Network.
A Recurrent Neural Network (LSTM) implementation example using TensorFlow library.
This example is using the MNIST database of handwritten digits (http://yann.lecun.com/exdb/mnist/)
Links:
[Long Short Term Memory](http://deeplearning.cs.cmu.edu/pdfs/Hochreiter97_lstm.pdf)
[MNIST Dataset](http://yann.lecun.com/exdb/mnist/).
Author: Aymeric Damien
Project: https://github.com/aymericdamien/TensorFlow-Examples/
"""
from __future__ import print_function
import tensorflow as tf
from tensorflow.contrib import rnn
# Import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
'''
To classify images using a recurrent neural network, we consider every image
row as a sequence of pixels. Because MNIST image shape is 28*28px, we will then
handle 28 sequences of 28 steps for every sample.
'''
# Training Parameters
learning_rate = 0.001
training_steps = 10000
batch_size = 128
display_step = 200
# Network Parameters
num_input = 28 # MNIST data input (img shape: 28*28)
timesteps = 28 # timesteps
num_hidden = 128 # hidden layer num of features
num_classes = 10 # MNIST total classes (0-9 digits)
# tf Graph input
X = tf.placeholder("float", [None, timesteps, num_input])
Y = tf.placeholder("float", [None, num_classes])
# Define weights
weights = {
'out': tf.Variable(tf.random_normal([num_hidden, num_classes]))
}
biases = {
'out': tf.Variable(tf.random_normal([num_classes]))
}
def RNN(x, weights, biases):
# Prepare data shape to match `rnn` function requirements
# Current data input shape: (batch_size, timesteps, n_input)
# Required shape: 'timesteps' tensors list of shape (batch_size, n_input)
# Unstack to get a list of 'timesteps' tensors of shape (batch_size, n_input)
x = tf.unstack(x, timesteps, 1)
# Another method to tranpose (batch_size, timesteps, n_input) # to a list of 'timesteps' tensors of shape (batch_size, n_input)
# 把timesteps和batch_size交换下,矩阵变成[timesteps,batch_size,n_input]
# x = tf.transpose(x, [1, 0, 2])
# 再变成 (timesteps*batch_size, n_input),
# 此步可以进行线性变换,变为(timesteps*batch_size, num_hidden)
# x = tf.reshape(x, [-1, n_input])
# 拆成timesteps个 (batch_size, n_input)
# x = tf.split(0, timesteps, x)
# Define a lstm cell with tensorflow
lstm_cell = rnn.BasicLSTMCell(num_hidden, forget_bias=1.0)
# Initial state
init_state = lstm_cell.zero_state(batch_size, dtype=tf.float32)
# Get lstm cell output
outputs, states = rnn.static_rnn(lstm_cell, x, initial_state=init_state, dtype=tf.float32)
# Linear activation, using rnn inner loop last output
return tf.matmul(outputs[-1], weights['out']) + biases['out']
logits = RNN(X, weights, biases)
prediction = tf.nn.softmax(logits)
# Define loss and optimizer
loss_op = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
logits=logits, labels=Y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(loss_op)
# Evaluate model (with test logits, for dropout to be disabled)
correct_pred = tf.equal(tf.argmax(prediction, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initialize the variables (i.e. assign their default value)
init = tf.global_variables_initializer()
# Start training
with tf.Session() as sess:
# Run the initializer
sess.run(init)
for step in range(1, training_steps+1):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Reshape data to get 28 seq of 28 elements
batch_x = batch_x.reshape((batch_size, timesteps, num_input))
# Run optimization op (backprop)
sess.run(train_op, feed_dict={X: batch_x, Y: batch_y})
if step % display_step == 0 or step == 1:
# Calculate batch loss and accuracy
loss, acc = sess.run([loss_op, accuracy], feed_dict={X: batch_x,
Y: batch_y})
print("Step " + str(step) + ", Minibatch Loss= " + \
"{:.4f}".format(loss) + ", Training Accuracy= " + \
"{:.3f}".format(acc))
print("Optimization Finished!")
# Calculate accuracy for 128 mnist test images
test_len = 128
test_data = mnist.test.images[:test_len].reshape((-1, timesteps, num_input))
test_label = mnist.test.labels[:test_len]
print("Testing Accuracy:", \
sess.run(accuracy, feed_dict={X: test_data, Y: test_label}))dynamic_rnn
# create a BasicRNNCell
rnn_cell = tf.nn.rnn_cell.BasicRNNCell(hidden_size)
# 'outputs' is a tensor of shape [batch_size, max_time, cell_state_size]
# defining initial state
initial_state = rnn_cell.zero_state(batch_size, dtype=tf.float32)
# 'state' is a tensor of shape [batch_size, cell_state_size]
outputs, state = tf.nn.dynamic_rnn(rnn_cell, input_data,
initial_state=initial_state,
dtype=tf.float32)# create 2 LSTMCells
rnn_layers = [tf.nn.rnn_cell.LSTMCell(size) for size in [128, 256]]
# create a RNN cell composed sequentially of a number of RNNCells
multi_rnn_cell = tf.nn.rnn_cell.MultiRNNCell(rnn_layers)
# 'outputs' is a tensor of shape [batch_size, max_time, 256]
# 'state' is a N-tuple where N is the number of LSTMCells containing a
# tf.contrib.rnn.LSTMStateTuple for each cell
outputs, state = tf.nn.dynamic_rnn(cell=multi_rnn_cell,
inputs=data,
dtype=tf.float32)