Serving Framework
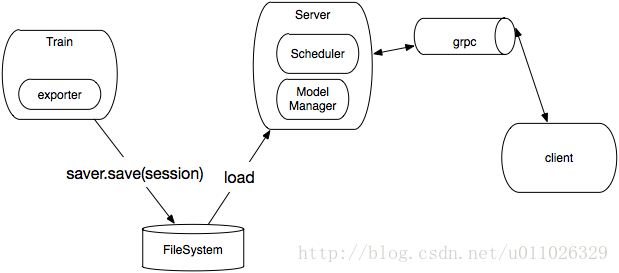
- Train:训练模型的过程
- exporter:负责将训练好的模型导出
- Sever:负责存储操作,例如将对象存储到磁盘
- Server:提供grpc server,组织request调用Module,将结果response client
- ModuleManager:负责加载训练好的模型
- Scheduler:负责请求的调度,例如BatchScheduler(buffer 某一批数据才发给Service)
- client:负责发送Request请求接收Response
TensorFlow Serving 1.0的特性包括:多种批量处理(Batching)选项;一个用于生命周期管理的模型管理器;为同一模型的多版本同时提供服务;支持子任务;数据源定义标准化,用于可插拔、可调用的模型存储。
TensorFlow社区中的一个核心挑战,是如何将模型从磁盘上取出并被服务调用,进而实现为可重生流水线的一部分。TensorFlow Serving允许用户原生地推出同一模型的多个版本,并同时地运行它们,而且可在不额外使用独立CI/CD工具的情况下还原更改。
TensorFlow Serving 1.0将会在小版本上与所有的TensorFlow的发布保存同步,同时也通过apt-get提供得到维护的Debian软件包。
TensorFlow Serving具有三个主要组件。
第一个组件是一系列的C++软件库,支持使用标准的“保存并导出”格式保存和加载TensorFlow模型。
第二个组件是一个通用的“配置驱动”核心平台,提供了与其它机器学习平台在某种层次上的互操作性,但是报告中并未对此做详细介绍。核心平台中打包了可执行的二进制和托管服务,其中二进制使用了据估计最优的默认设置,并经实践得以改进。
第三个组件是通过Cloud ML所提供的一些商业选项。
核心平台关注的是低延迟的请求和响应时间,以及更优的计算时间分配。对于GPU/TPU和CPU密集型任务,TensorFlow Serving使用独立的线程库对请求做小批量(mini-batching)处理,提供了更少的往返调用,以及更高效的资源分配。
软件库是经过优化的,主要针对使用“读取-拷贝-更新”(read-copy-update)模式的高性能处理、服务器启动时的模型快速加载以及引用计数(reference count)指针。软件库为指针提供了容错,以追踪指定时刻一个模型在图模型中的执行状态。
TensorFlow Serving提供非阻塞的模型加载和推理服务,这是通过独立的线程池处理的。具有队列的小批量(Mini-batching)处理是TensorFlow Serving中的一个重要概念。其中,异步请求被一并小批量处理,并传递给一个TensorFlow Session,由该Session去协调Manager处理请求。推理请求也被一并小批量处理,以降低延迟。请求处理使用ServableHandle实现,ServableHandle是一个指向特定客户请求的指针。
SessionBundle模型格式已被弃用,取而代之的是新的SavedModel格式。TensorFlow Serving中引入了MetaGraph这一概念,其中包括处理器架构的信息,经训练的模型将运行在该处理器架构上。MetaGraph包含了模型的词汇、嵌入(Embedding)、训练权重及其它一些模型参数。SavedModel对象由MetaGraphs组成,设计为可移植的并且可调用的工件(Artifact)。SavedModel抽象可用于训练、部署服务(Serving)和离线评估,并可在新的CLI上运行。SignatureDef是SavedModel的一个组件,帮助实现图模型中各层的标注(Annotate)和特征化。
TensorFlow Serving提供了数据源(Source)库的API,并为模型类型提供了SourceAdapter。Source模块为SavedModels发射出Loader,并估计内存需求情况。Source API发射元数据到Manager模块,由Manager模块为模型加载数据,并加载该模型本身。Fiedel指出,通过封装通用代码模式为一个用于注入(Injection)的配置文件,新的ServerCore实现将模板(Biolerplate)的代码行数(LOC,Line Of Code)从约300行减少到10行。
新的Inference API为通用用例提供了多个可重用的组件。其中,Predict组件用于预测配置和部署服务(Serving),Regress组件用于回归模型,Classify组件用于分类算法,Multi-inference组件用于将Regress组件和Classify组件的API组合在一起使用。
现在TensorFlow Serving还支持Multi-headed inferencing。Multi-headed inferencing是新出现于机器学习领域中的一个研究热点,试图解决存在并发一致请求的问题。通过去除被识别为错误的或重复的请求,Mutil-headed Inferencing可进一步提高小批量处理(Mini-batch)的效率。 一些产生错误的数据源所生成的输入量非常大,并且代价高昂。具有对这样数据源的弹性,有助于阻止资源消费和数据质量上的负面级联效应。
Google推荐使用针对GCP客户做了优化的静态二进制,以更好地利用对gRPC函数默认设置的最优估计。为使用户可尽快上手TensorFlow Serving ,1.0版本还提供了Docker镜像以及K8教程。