1.指数衰减函数的参数和计算方程:
tensorflow提供了一个灵活的学习率设置方法,指数衰减函数tf.train.exponential_decay(),它的计算实现如下: decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps)
其中decay_rate是衰减系数(取值小于1,比如0.1), global_steps是当前迭代次数,decay_steps是总的迭代次数,learning_rate是初始学习率。
2. onehot=True
在多类场景下,onehot=true表示,只有一个元素的值是1,其他元素的值是0, 一个长度为n的数组,只有一个元素是1.0,其他元素是0.0。
onehot=False则没有这样的限制。
3. Tensorflow交叉熵函数:cross_entropy
以下交叉熵计算函数输入中的
logits
都不是softmax或sigmoid的输出,因为它在函数内部进行了sigmoid或softmax操作
tf.nn.sigmoid_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, name=None)
_sentinel:本质上是不用的参数,不用填
labels:一个和logits具有相同的数据类型(type)和尺寸形状(shape)的张量(tensor)
shape:[batch_size,num_classes],单样本是[num_classes]
logits:一个数据类型(type)是float32或float64的张量
name:操作的名字,可填可不填
它对于输入的logits先通过sigmoid函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出
它适用于每个类别相互独立但互不排斥的情况:例如一幅图可以同时包含一条狗和一只大象
tf.nn.softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, dim=-1, name=None)
_sentinel:本质上是不用的参数,不用填
labels:每一行labels[i]必须是一个有效的概率分布,
one_hot=True(向量中只有一个值为1,其他值为0)
logits:labels和logits具有相同的数据类型(type)和尺寸(shape)
shape:[batch_size,num_classes],单样本是[num_classes]
name:操作的名字,可填可不填
它对于输入的logits先通过softmax函数计算
它适用于每个类别相互独立且排斥的情况,一幅图只能属于一类,而不能同时包含一条狗和一只大象
tf.nn.sparse_softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, name=None)
_sentinel:本质上是不用的参数,不用填
labels:shape为[batch_size],labels[i]是[0,num_classes)的一个索引, type为int32或int64
logits:shape为[batch_size,num_classes],type为float32或float64
name:操作的名字,可填可不填
它适用于每个类别相互独立且排斥的情况,一幅图只能属于一类,而不能同时包含一条狗和一只大象
tf.nn.weighted_cross_entropy_with_logits(labels, logits, pos_weight, name=None)
计算具有权重的sigmoid交叉熵
sigmoid_cross_entropy_with_logits()
_sentinel:本质上是不用的参数,不用填
labels:一个和logits具有相同的数据类型(type)和尺寸形状(shape)的张量(tensor)
shape:[batch_size,num_classes],单样本是[num_classes]
logits:一个数据类型(type)是float32或float64的张量
pos_weight:正样本的一个系数
name:操作的名字,可填可不
计算公式: pos_weight*labels * -log(sigmoid(logits)) + (1 - labels) * -log(1 - sigmoid(logits))
Having two different functions is a convenience, as they produce the same result.
The difference is simple:
- For
sparse_softmax_cross_entropy_with_logits, labels must have the shape [batch_size] and the dtype int32 or int64. Each label is an int in range [0, num_classes-1].
- For
softmax_cross_entropy_with_logits, labels must have the shape [batch_size, num_classes] and dtype float32 or float64.
Labels used in softmax_cross_entropy_with_logits are the one hot version of labels used in sparse_softmax_cross_entropy_with_logits.
Another tiny difference is that with sparse_softmax_cross_entropy_with_logits, you can give -1 as a label to have loss 0 on this label.
看下图就明白了

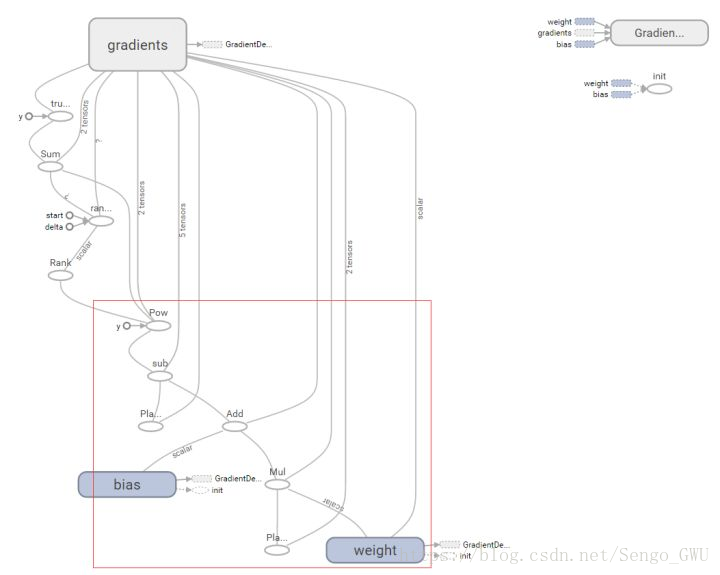
答案就是上面那个 gradients!!!
这张图里面 gradients 看上去只是小小的一个框,代码里面也只有 tf.train.GradientDescentOptimizer() 这么一句,但是如果我们把这个框展开。