Processes
The classic definition of a process is an instance of a program in execution.
Each program in the system runs in the context of some process.
The context consists of the state that the program needs to run correctly.
This state includes the program’s code and data stored in memory, its stack, the contents of its general- purpose registers, its program counter, environment variables, and the set of open file descriptors.
Each time a user runs a program by typing the name of an executable object file to the shell,
the shell creates a new process and then runs the executable object file in the context of this new process.
Application programs can also create new processes and run either their own code or other applications in the context of the new process.
Logical Control Flow
This sequence of PC values is known as a logical control flow, or simply logical flow.
The only evidence to the contrary is that if we were to precisely measure the elapsed time of each instruction,
we would notice that the CPU appears to peri- odically stall between the execution of some of the instructions in our program.
However, each time the processor stalls, it subsequently resumes execution of our program without any change to the contents of the program’s memory locations or registers.
Concurrent Flows
Logical flows take many different forms in computer systems.
Exception handlers, processes, signal handlers, threads, and Java processes are all examples of logical flows.
A logical flow whose execution overlaps in time with another flow is called a concurrent flow, and the two flows are said to run concurrently.
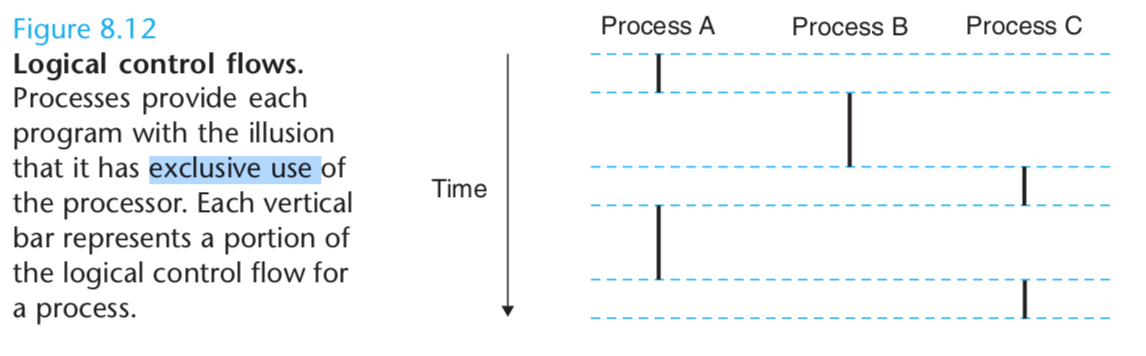
For example, in Figure 8.12, processes A and B run concurrently, as do A and C.
On the other hand, B and C do not run concurrently.
The general phenomenon of multiple flows executing concurrently is known as concurrency.
The notion of a process taking turns with other processes is also known as multitasking.
Each time period that a process executes a portion of its flow is called a time slice.
Thus, multitasking is also referred to as time slicing.
Notice that the idea of concurrent flows is independent of the number of processor cores or computers that the flows are running on.
If two flows overlap in time, then they are concurrent, even if they are running on the same processor.
If two flows are running concurrently on different processor cores or computers, then we say that they are parallel flows, that they are running in parallel, and have parallel execution.
Private Address Space
This space(for each process) is private in the sense that a byte of memory associated with a particular address in the space cannot in general be read or written by any other process.
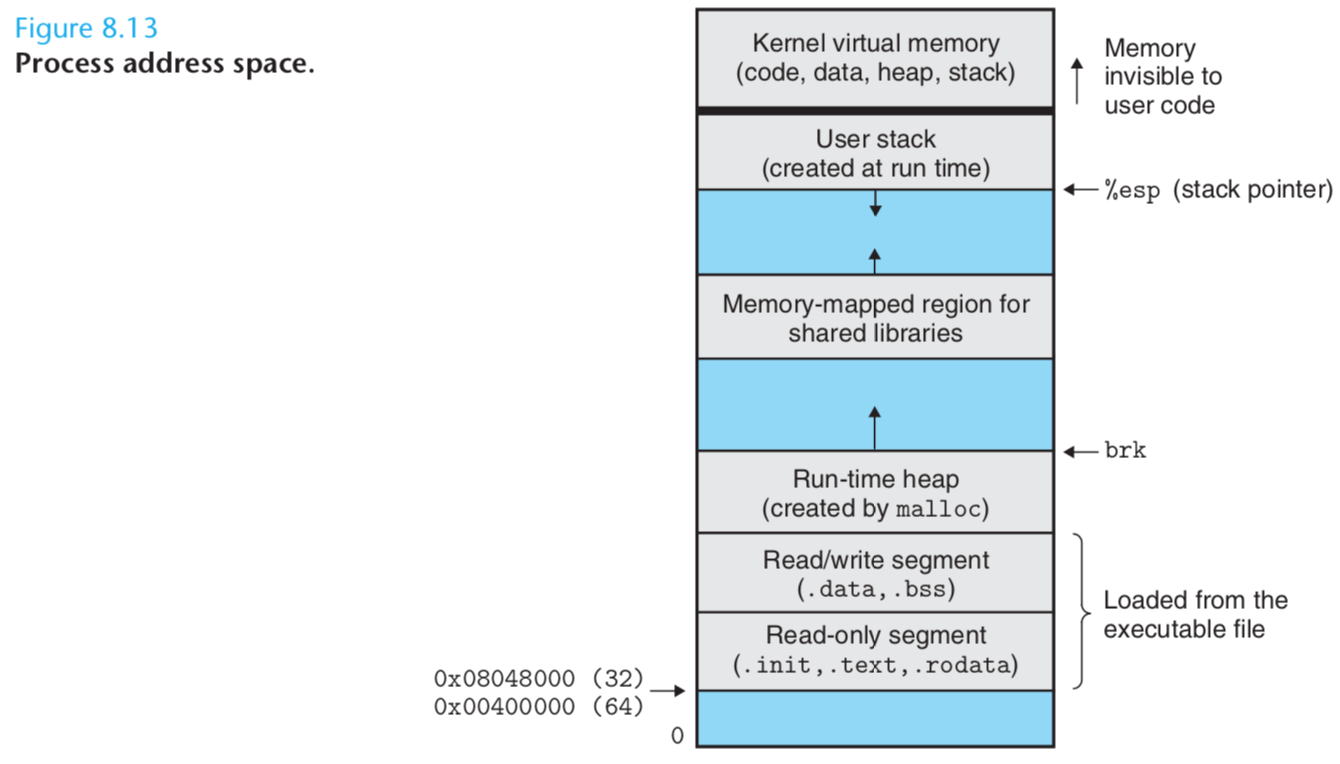
For example, Figure 8.13 shows the organization of the address space for an x86 Linux process.
The bottom portion of the address space is reserved for the user program, with the usual text, data, heap, and stack segments.
Code segments begin at address 0x08048000 for 32-bit processes, and at address 0x00400000 for 64-bit processes.
The top portion of the address space is reserved for the kernel.
This part of the address space(the top portion) contains the code, data, and stack that the kernel uses when it executes instructions on behalf of the process (e.g., when the application program executes a system call).
User and Kernel Modes
Processors typically provide this capability with a mode bit in some control register that characterizes the privileges that the process currently enjoys.
When the mode bit is set, the process is running in kernel mode (sometimes called supervisor mode).
A process running in kernel mode can execute any instruction in the instruction set and access any memory location in the system.
When the mode bit is not set, the process is running in user mode.
A process in user mode is not allowed to execute privileged instructions that do things such as halt the processor, change the mode bit, or initiate an I/O operation.
Nor is it allowed to directly reference code or data in the kernel area of the address space.
Any such attempt results in a fatal protection fault.
User programs must instead access kernel code and data indirectly via the system call interface.
A process running application code is initially in user mode.
The only way for the process to change from user mode to kernel mode is via an exception such as an interrupt, a fault, or a trapping system call.
When the exception occurs, and control passes to the exception handler, the processor changes the mode from user mode to kernel mode.
The handler runs in kernel mode. When it returns to the application code, the processor changes the mode from kernel mode back to user mode.
Linux provides a clever mechanism, called the /proc filesystem, that allows user mode processes to access the contents of kernel data structures.
The /proc filesystem exports the contents of many kernel data structures as a hierarchy of text files that can be read by user programs.
For example, you can use the /proc filesys- tem to find out general system attributes such as CPU type (/proc/cpuinfo),
or the memory segments used by a particular process (/proc/<process id>/maps).
The 2.6 version of the Linux kernel introduced a /sys filesystem, which exports additional low-level information about system buses and devices.
Context Switches
The operating system kernel implements multitasking using a higher-level form of exceptional control flow known as a context switch.
The kernel maintains a context for each process.
The context is the state that the kernel needs to restart a preempted process.
It consists of the values of objects such as the general purpose registers, the floating-point registers, the program counter,
user’s stack, status registers, kernel’s stack, and various kernel data structures such as a page table that characterizes the address space,
a process table that contains information about the current process, and a file table that contains information about the files that the process has opened.
At certain points during the execution of a process, the kernel can decide to preempt the current process and restart a previously preempted process.
This decision is known as scheduling, and is handled by code in the kernel called the scheduler.
When the kernel selects a new process to run, we say that the kernel has scheduled that process.
After the kernel has scheduled a new process to run, it preempts the current process and transfers control to the new process using a mechanism called a context switch that
(1) saves the context of the current process, (2) restores the saved context of some previously preempted process, and (3) passes control to this newly restored process.
A context switch can occur while the kernel is executing a system call on behalf of the user.
If the system call blocks because it is waiting for some event to occur, then the kernel can put the current process to sleep and switch to another process.
For example, if a read system call requires a disk access, the kernel can opt to perform a context switch and run another process instead of waiting for the data to arrive from the disk.
Another example is the sleep system call, which is an explicit request to put the calling process to sleep.
In general, even if a system call does not block, the kernel can decide to perform a context switch rather than return control to the calling process.
A context switch can also occur as a result of an interrupt.
For example, all systems have some mechanism for generating periodic timer interrupts, typically every 1 ms or 10 ms.
Each time a timer interrupt occurs, the kernel can decide that the current process has run long enough and switch to a new process.
An example for context switching:
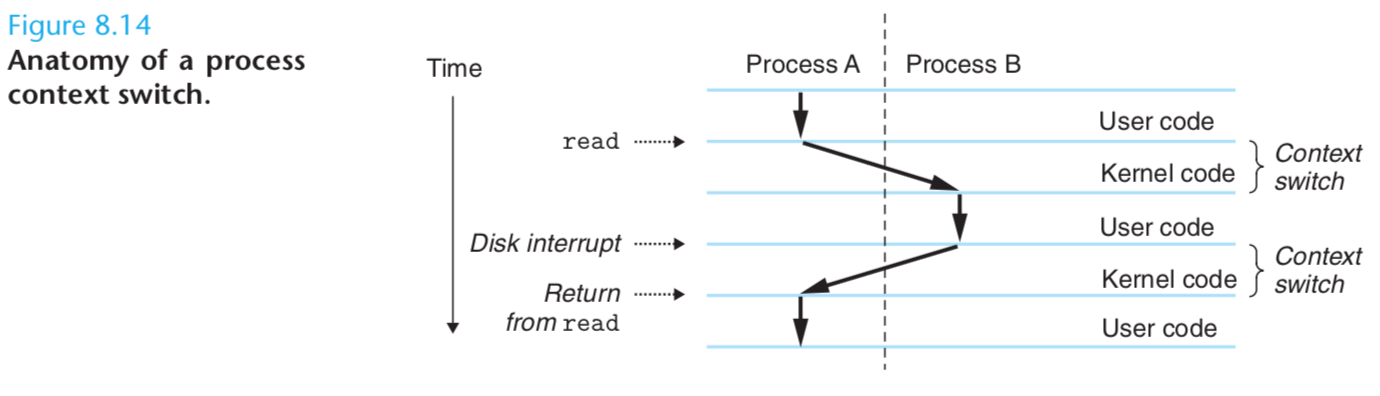
In this example, initially process A is running in user mode until it traps to the kernel by executing a read system call.
The trap handler in the kernel requests a DMA transfer from the disk controller and arranges for the disk to interrupt the processor after the disk controller has finished transferring the data from disk to memory.
The disk will take a relatively long time to fetch the data (on the order of tens of milliseconds), so instead of waiting and doing nothing in the interim, the kernel performs a context switch from process A to B.
Note that before the switch, the kernel is executing instructions in user mode on behalf of process A.
During the first part of the switch, the kernel is executing instructions in kernel mode on behalf of process A.
Then at some point it begins executing instructions (still in kernel mode) on behalf of process B.
And after the switch, the kernel is executing instructions in user mode on behalf of process B.
Process B then runs for a while in user mode until the disk sends an interrupt to signal that data has been transferred from disk to memory.
The kernel decides that process B has run long enough and performs a context switch from process B to A,
returning control in process A to the instruction immediately following the read system call.
Process A continues to run until the next exception occurs, and so on.
Some details about cache pollution
In general, hardware cache memories do not interact well with exceptional control flows such as interrupts and context switches.
If the current process is interrupted briefly by an interrupt, then the cache is cold for the interrupt handler.
If the handler accesses enough items from main memory, then the cache will also be cold for the interrupted process when it resumes.
In this case, we say that the handler has polluted the cache.
A similar phenomenon occurs with context switches. When a process resumes after a context switch, the cache is cold for the application program and must be warmed up again.