Python爬虫+有道翻译
废话不多说,直接上步骤:
1.浏览器搜索进入有道翻译界面,接着【F12】或鼠标右键【检查】。
2.选择network,此时下面的调试框内还没有任何东西。这时,在上方翻译框中输入翻译文字。点击翻译,这时,调试框中会出现一个translate.....的文件。如下图:
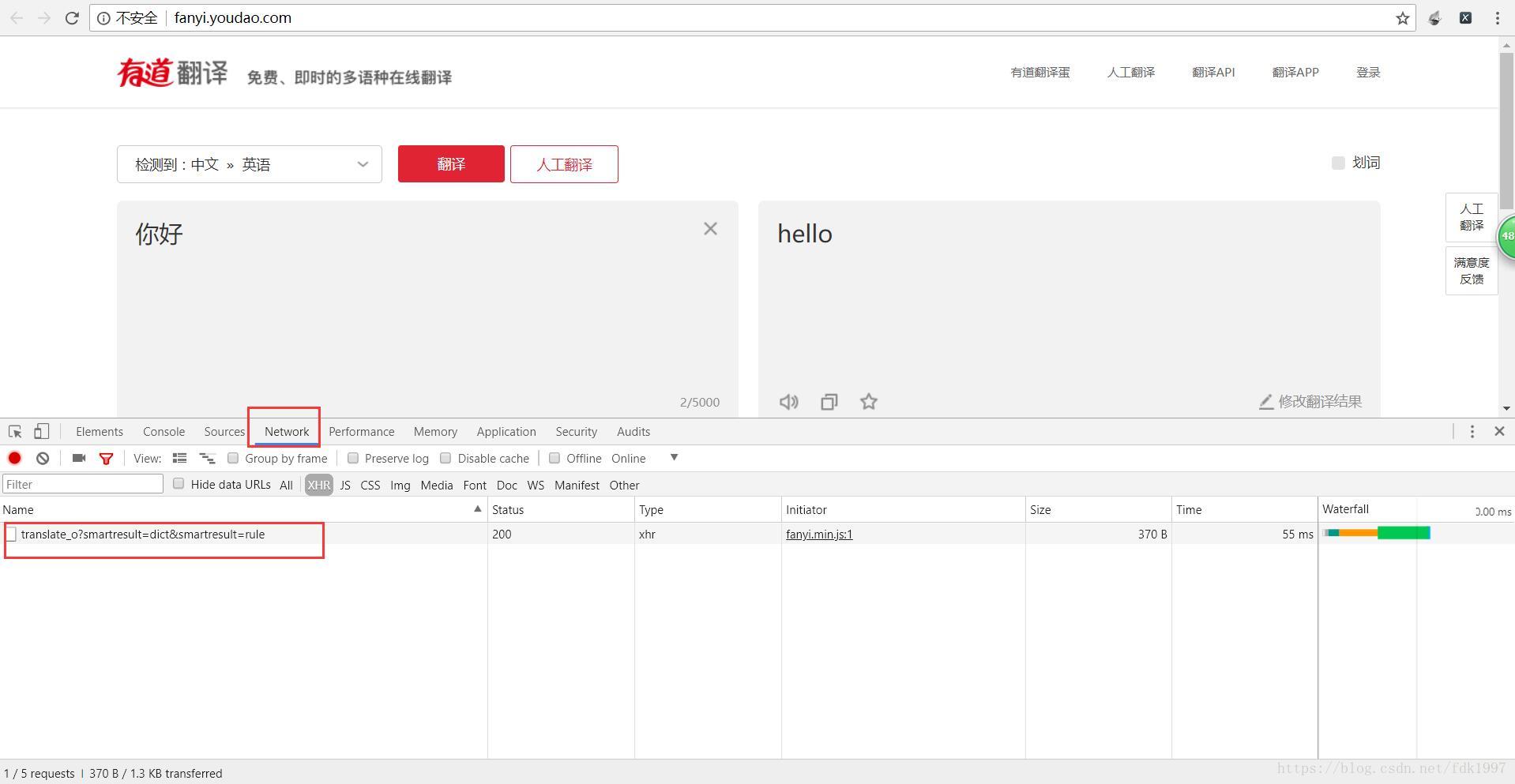
3.点击打开文件,会发现出现一堆数据,如下图:

在图中标注的2中,里面是翻译返回的json结果数据,我们只需要解析json,查找结果位置,就可以输出翻译结果了,如下图:

4.过程都说完了,还是比较简单的,下面就要直接上代码
import requests
import json
#1.获取post的url,及数据
#下面的链接不知道什么原因会出错,改成下下面一个链接就行了
#post_url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"--》不能用
while True:
post_url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
string = input("请输入要翻译的中英文词组(【:w】退出):")
if string != ':w':
post_tran = {
# 定义变量,接收手动传输的语句进行翻译
"i": string,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": "1530285791270",
"sign": "4f32f0fbfbc18150879032eb2b11cb4f",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_CLICKBUTTION",
"typoResult": "false"
}
# 添加浏览器请求头,伪装成浏览器
headers = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36"}
#2.发送请求,获取响应
r = requests.post(post_url,headers=headers,data=post_tran)
json_str = r.content.decode()
#3.json.loads()将json字符串转换成字典,提取数据,打印
dict_response = json.loads(json_str)
result = dict_response["translateResult"][0][0]["tgt"]
print('翻译结果是:{}'.format(result))
else:
print("退出成功!下次见...")
break