Python爬虫实例:自制翻译机
一起试试爬取有道翻译自制翻译器吧ლ(^ω^ლ) ,自己动手做个翻译器吧,一点都不难哦~
用post和json,短短几行(或者说二十几行)就可以做到!
要求实现功能:用户输入英文或中文,程序即可打印出来对应的译文。
实现一键翻译的功能,最简单的方案便是爬虫。在此,我们选择的网站是有道翻译:http://fanyi.youdao.com/
然后还是那套熟悉的流程:F12 --> Network --> 操作 --> 在新加载出来的请求中(判断数据是否在URL里)寻找我们需要的数据 --> 对比、找规律。
步骤
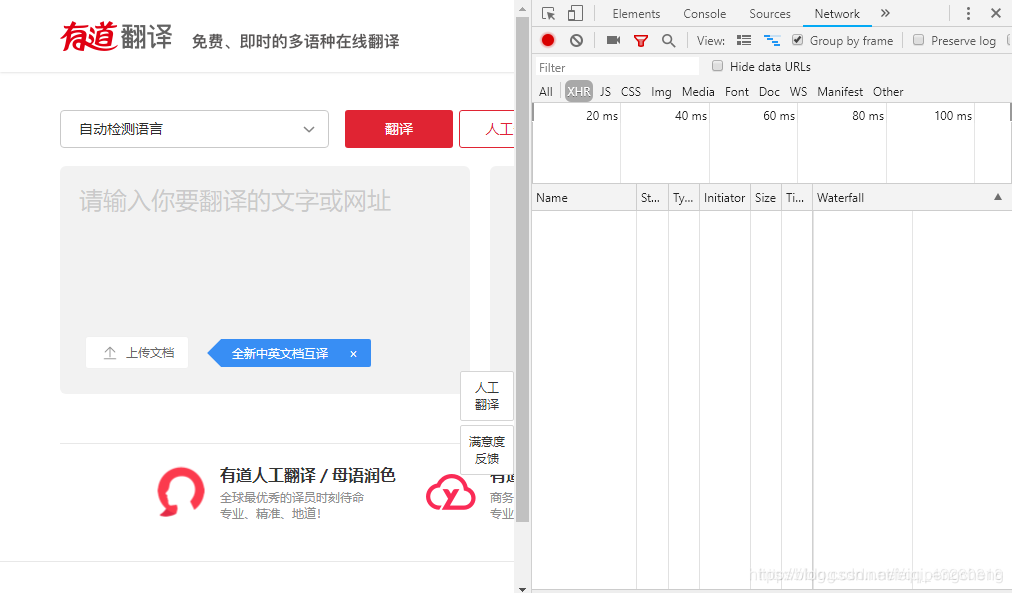
放一下我操作的流程图吧,易知要在XHR里找要的数据:
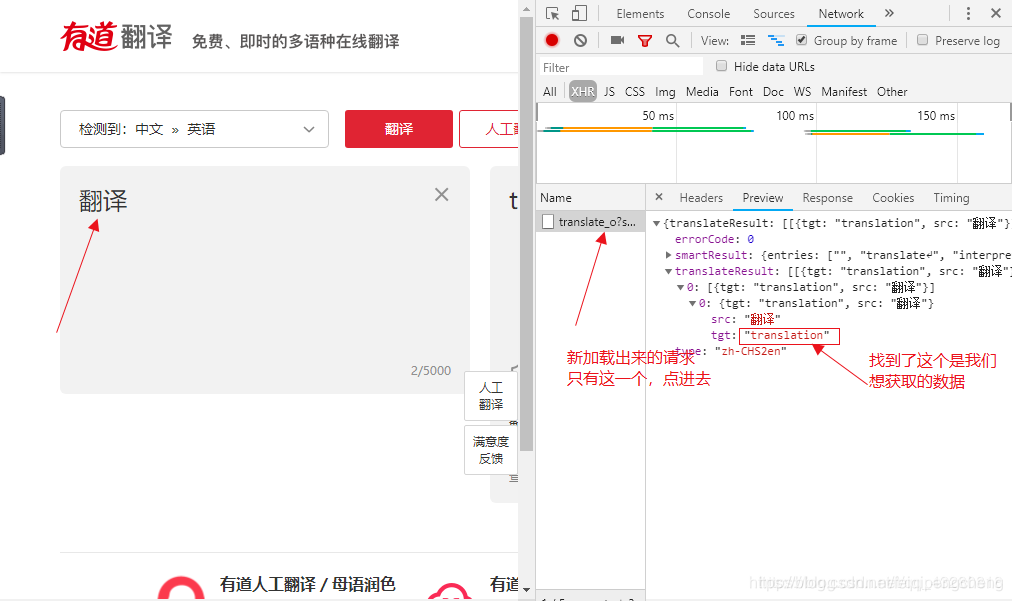
然后输入要翻译的文字,找到我们需要的数据:
然后我们要去看Header里面,找到我们真正要请求的URL。然后再操作几次,得到URL的规律:
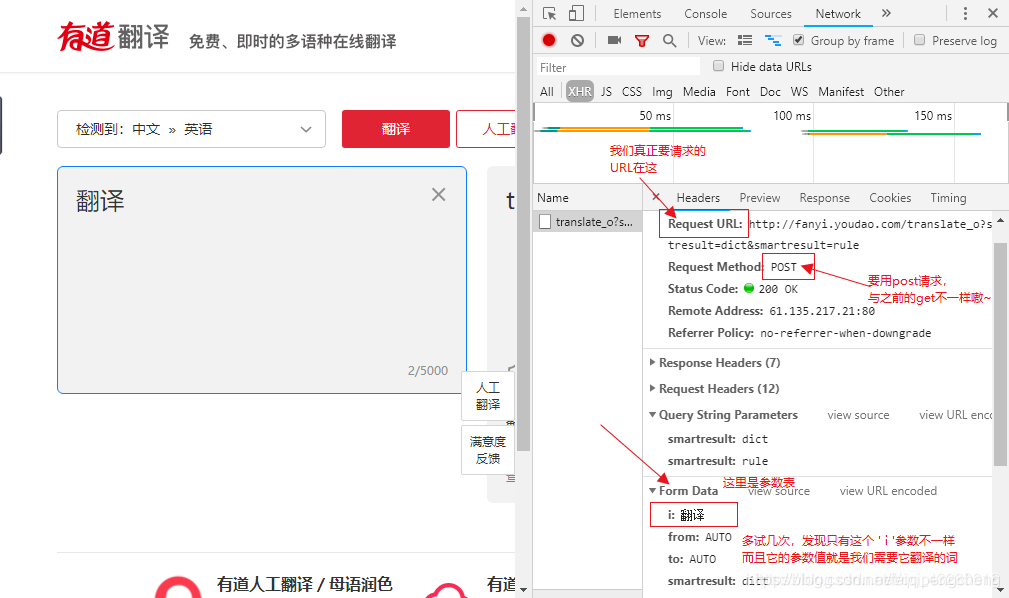
(有bug,往下看)
然后就可以写代码啦~~!封装成函数更好看嗷
解决反爬
但是我们会遇到一个问题,就是有道翻译有反爬虫机制,它使用了加密技术。你的程序可能会报错:{“errorCode”:50},它的解决方法基本都是删除url中的"_o",目的大概就是绕过有道翻译的反爬虫机制,也就是salt和sign。
在这里插入图片描述
当url中包含"_o"的时候会自动包含如下两个参数:salt,sign,仔细看的话,这两个参数值是会变的,只是变化不明显而已。所以我们不要它俩做参数就奥K。
import urllib.request
import urllib.parse
import json
f=input('翻译的句子:')
h={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0'}
d={"i":f,"from":"AUTO","to":"AUTO","smartresult":"dict","client":"fanyideskweb","salt":"15783143482231","sign":"acc6872ebb674de2ec8c5c2a941ad1be","ts":"1578314348223","bv":"e2a78ed30c66e16a857c5b6486a1d326","doctype":"json","version":"2.1","keyfrom":"fanyi.web","action":"FY_BY_CLICKBUTTION"}
d=urllib.parse.urlencode(d).encode('utf-8')
r=urllib.request.Request('http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule',d,h)
i=urllib.request.urlopen(r)
a=i.read().decode('utf-8')
b=json.loads(a)
print('翻译的结果'+b['translateResult'][0][0]['tgt'])
在这里插入代码片
