生成随机样本时,若是简单的随机抽样,会有数据过度聚集的问题,拉丁超立方抽样解决了这个问题。
下面用图说明两者的区别:
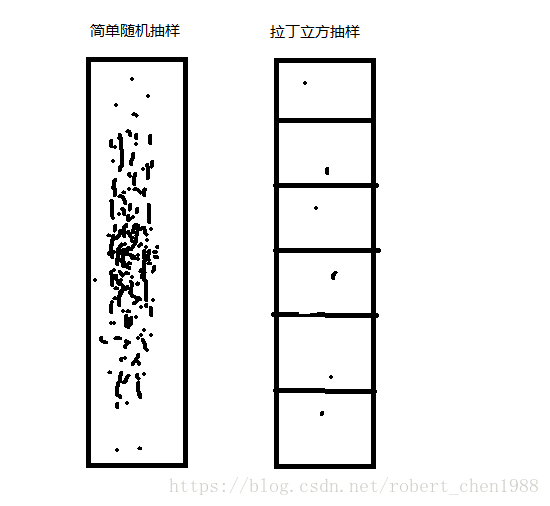
图中可以看出,简单随机抽样中的数据大部分在中间,而拉丁立方抽样则均匀产生在各个小区间内。
拉丁立方抽样必须首先明确生成的样本个数 n,拉丁立方抽样的步骤:
1. 将 [0, 1] 分为 n 等份,每个小区间内 [i/n, (i+1)/n] 内根据均匀分布随机产生一个数。
2. 将这 n 个随机数的顺序打乱。
3. 这 n 各数即为每个随机样本的概率,按照概率分布函数的反函数生成随机分布的值。
n 的值越大,生成的数据效果越好。Matlab 专门有一个 lhsdesign 函数生成拉丁立方抽样的概率矩阵。自己编写了一个 java 的代码如下,例子中生成了 1000 个两阶段的泊松分布样本。
import java.util.Arrays;
import umontreal.ssj.probdist.Distribution;
import umontreal.ssj.probdist.PoissonDist;
import umontreal.ssj.randvar.UniformGen;
import umontreal.ssj.randvar.UniformIntGen;
import umontreal.ssj.rng.MRG32k3aL;
import umontreal.ssj.rng.RandomStream;
/**
* @author chen zhen
* @version 创建时间:2018年4月11日 下午4:18:55
* @value 类说明: latin hypercube sampling
*/
public class LHS {
static RandomStream stream = new MRG32k3aL();
// 生成指定分布的样本
static double[][] generateLHSamples(Distribution[] distributions, int sampleNum){
int periodNum = distributions.length;
double[][] samples = new double[sampleNum][periodNum];
// 在每个[i/n, (i+1)/n] 内生成一个随机概率,然后根据概率得到指定分布的数
for (int i = 0; i < periodNum; i++)
for (int j = 0; j < sampleNum; j++) {
double randomNum = UniformGen.nextDouble(stream, 0, 1.0/sampleNum);
double lowBound = (double) j/ (double) sampleNum;
samples[j][i] = lowBound + randomNum;
samples[j][i] = distributions[i].inverseF(samples[j][i]);
}
shuffle(samples); // 打乱数组
return samples;
}
// 打乱一个二维数组
static double[][] shuffle(double[][] samples){
for(int i = 0; i < samples[0].length; i++)
for (int j = 0; j < samples.length; j++){
int mark = UniformIntGen.nextInt(stream, 0, samples.length - 1);
double temp = samples[j][i];
samples[j][i] = samples[mark][i];
samples[mark][i] = temp;
}
return samples;
}
public static void main(String[] args) {
int sampleNum = 1000;
double[] meanDemand = {20, 5};
PoissonDist[] distributions = new PoissonDist[meanDemand.length];
for (int i = 0; i < meanDemand.length; i++)
distributions[i] = new PoissonDist(meanDemand[i]);
double[][] samples = generateLHSamples(distributions, sampleNum);
System.out.println(Arrays.deepToString(samples));
for (int i = 0; i < meanDemand.length; i++) {
double sum = 0;
for (int j = 0; j < sampleNum; j++) {
sum += samples[j][i];
}
System.out.println(sum/sampleNum);
}
}
}生成样本的均值为 20.003, 4.998,非常接近所需泊松分布的均值。