在之前,我已经在豆瓣电影top250中爬取了约6w条好评和差评,在此我们来利用这些数据,进行入门级别的文本分类。
一 数据清洗
数据在豆瓣电影top250提供下载,下载后能看到6W条好评和差评,由于爬取时未能完全清除符号,导致一部分毫无意义的颜文字评论混入其中,为了清除这些数据,我在(仅当数据量较小的情况下)excel中替换掉了肉眼可见的一些符号,然后转换成xlsx格式(csv中出现中文时bug太多,在此放弃使用csv格式)。如果数据量较大时,请使用正则表达式进行数据清洗。
二 数据的读取与分词
在此提供清洗完毕的数据下载,您可以下载后自行尝试。
使用xlrd库进行xlsx文件的读取,读取完毕后使用jieba分词工具进行分词。
import numpy as np
import pandas as pd
import re
import jieba
import xlrd
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from nltk.tokenize import word_tokenize
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from nltk.corpus import stopwords
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
# 载入数据
# 从Excel文件中读取出Book对象,并定位到sheet1,也就是具体的数据
douban_data_input = xlrd.open_workbook(r"./douban_xlsx.xlsx").sheet_by_index(0)
douban_data = [[0 for i in range(2)] for j in range(douban_data_input.nrows)]
for i in range(douban_data_input.nrows):
douban_data[i][0] = bool(douban_data_input.cell_value(rowx=i, colx=0))
str = douban_data_input.cell_value(rowx=i, colx=1)
douban_data[i][1] = " ".join(jieba.cut(str, cut_all=False, HMM=True))三 数据的TF-IDF计算
TF-IDF可以将一段文字映射到多维向量空间中,具体的解释请参见《数学之美》(吴军 著)P104开始的TF-IDF解释。
总的来说,就是把一段话的每个词都配之以重要性指标,某个词在这段话的出现次数多时,它就更重要。比如一段话中提到了三次“中国”,就比另一段只提到了一次的重要。
此外,当这个词在所有话中出现的次数多时(比如“苹果”,“乔布斯”等不常见词),这个词就更加的重要;当这个词在所有的段落中出现次数都多时(比如“的”,“这”等常见词),这个词的重要性下降。
对于每个词都计算这样的重要性并写成一个向量后,映射就完成了。
具体代码:
# 由于内存不够大,只取其中的一部分进行测试
all_star_list = [x[0] for x in douban_data] # 提取出第一列来
all_star_list = all_star_list[20000:34000]
all_comment_list = [x[1] for x in douban_data] # 提取出第二列来
all_comment_list = all_comment_list[20000:34000]
# 数据的TF-IDF信息计算
vectorizer = CountVectorizer() # 该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j],表示j词在i类文本下的词频
transformer = TfidfTransformer() # 该类会统计每个词语的tf-idf权值
# 第一个fit_transform是计算tf-idf,第二个fit_transform是将文本转为词频矩阵
tfidf = transformer.fit_transform(vectorizer.fit_transform(all_comment_list))
word = vectorizer.get_feature_names() # 获取词袋模型中的所有词语
weight = tfidf.toarray() # 将tf-idf矩阵抽取出来,元素weight[i][j]表示j词在i类文本中的tf-idf权重,4w条评论需要4GB内存四 模型拟合
简单起见,只调用最简单的逻辑回归进行拟合,拆分4成数据作为CV集
# 拆分数据为训练集,交叉验证集合
x_train, x_vc, y_train, y_vc = train_test_split(weight, all_star_list, test_size=0.4, random_state=0)
# 开始训练
clf = LogisticRegression()
clf.fit(x_train, y_train)
y_pre = clf.predict(x_vc)
train_scores = clf.score(x_train, y_train)
valid_scores = accuracy_score(y_pre, y_vc)
print(c, train_scores, valid_scores)结果:训练集上0.888452380952381 ,CV集上0.85,结果还算可以。
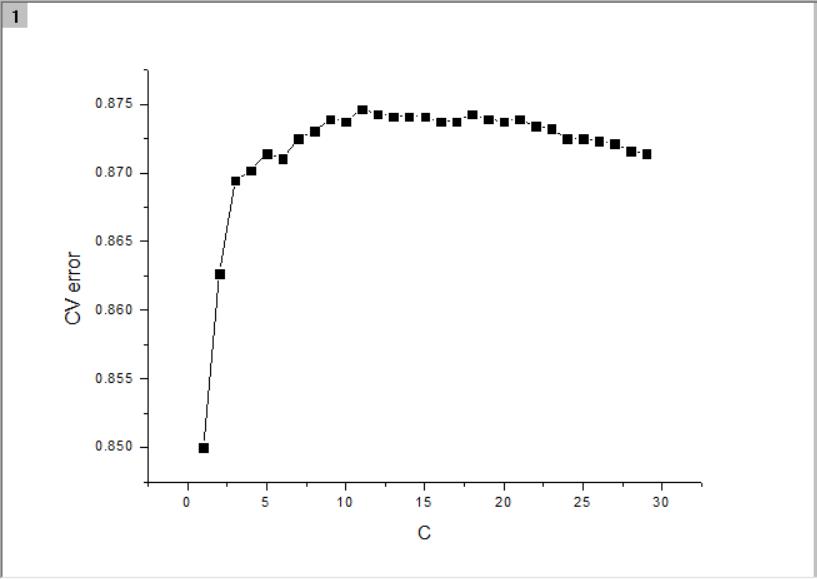
调整正则化强度:将
clf = LogisticRegression()替换为(C从1到30计算多次,取最大值)
clf = LogisticRegression(C=10.0)训练集上0.9907142857142858,CV集上0.87375,提升2.3%