队列一般可以用链表来模拟,用两个指针,分别指向头节点和尾节点。尾节点指向插入数据的方向,头节点指向消耗数据的方向。skynet全局消息队列也用到了上面的数据结构:
struct message_queue {
struct spinlock lock;
uint32_t handle;
int cap;
int head;
int tail;
int release;
int in_global;
int overload;
int overload_threshold;
struct skynet_message *queue;
struct message_queue *next;
};
struct global_queue {
struct message_queue *head;
struct message_queue *tail;
struct spinlock lock;
};每个节点的类型是message_queue,实际上他也是个消息队列,称为次级消息队列。重点说一下这个次级消息队列的数据结构与算法。
次级消息队列,实际上是一个数组,也就是缓冲区。他有两个哨兵,分别指向他的头部和尾部(head和tail)。次级消息队列中消息的push和pop实际上用到的是所谓的环形队列,他的思想是,刚开始时head和tail都为0,当有push数据后,tail开始移动,如图1所示。黄色表示环形缓冲区中的数据,白色表示环形缓冲区没有使用的区域。当消耗消息后变成图2所示。消息的大小等于tail - head
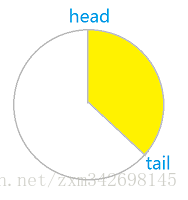

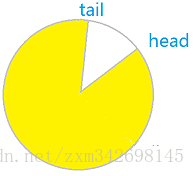
图1 图2 图3
注意,tail指针的值也有可能小于head的。为什么呢?正如时钟一样,当指针指向12点之后,又会重新回到0点。所以当tail指针的值大于了容量cap,他又会绕回到0,此时他一定小于等于head。如图3所示。此时消息的大小等于tail + cap - head。
还有一个需要注意的问题是,当head与tail指针重合时说明缓冲区已满,需要扩大缓冲区,并拷贝原来的数据,如图4所示:
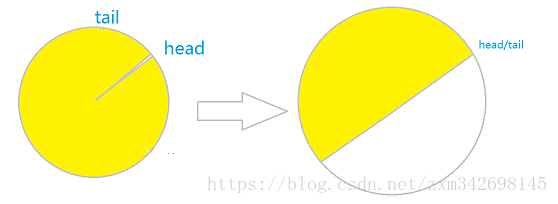
图4
以上过程用代码实现为:
skynet_mq_pop(struct message_queue *q, struct skynet_message *message) {
int ret = 1;
SPIN_LOCK(q)
if (q->head != q->tail) {
*message = q->queue[q->head++];
ret = 0;
int head = q->head;
int tail = q->tail;
int cap = q->cap;
if (head >= cap) {
q->head = head = 0;
}
int length = tail - head;
if (length < 0) {
length += cap;
}
while (length > q->overload_threshold) {
q->overload = length;
q->overload_threshold *= 2;
}
} else {
// reset overload_threshold when queue is empty
q->overload_threshold = MQ_OVERLOAD;
}
if (ret) {
q->in_global = 0;
}
SPIN_UNLOCK(q)
return ret;
}
static void
expand_queue(struct message_queue *q) {
struct skynet_message *new_queue = skynet_malloc(sizeof(struct skynet_message) * q->cap * 2);
int i;
for (i=0;i<q->cap;i++) {
new_queue[i] = q->queue[(q->head + i) % q->cap];
}
q->head = 0;
q->tail = q->cap;
q->cap *= 2;
skynet_free(q->queue);
q->queue = new_queue;
}
void
skynet_mq_push(struct message_queue *q, struct skynet_message *message) {
assert(message);
SPIN_LOCK(q)
q->queue[q->tail] = *message;
if (++ q->tail >= q->cap) {
q->tail = 0;
}
if (q->head == q->tail) {
expand_queue(q);
}
if (q->in_global == 0) {
q->in_global = MQ_IN_GLOBAL;
skynet_globalmq_push(q);
}
SPIN_UNLOCK(q)
好了,消息队列中用到的数据结构基本原理讲清楚了,下面说说消息的产生,消耗以及调度。
消息是如何写入到消息队列中去的呢?我们要向一个服务发消息,最终是通过调用skynet.send接口,将消息插入到该服务专属的次级消息队列的,次级消息队列的内容,并不是context结构的一部分(context只是引用了他的指针),因此,在一个服务执行callback的同时,其他服务(可能是多个线程内执行callback的其他服务)可以向它的消息队列里push消息,而mq的push操作,是加了一个自旋锁,以避免多个线程,同时操作一个消息队列。lua层的skynet.send接口,最终会调到c层的skynet_context_push。这个接口实质上,是通过handle将context指针取出来,然后再往消息队列里push消息。
worker线程则负责对消息队列进行调度(worker线程的数量,可以通过配置表指定)。skynet在启动时,会创建若干条worker线程(由配置指定)。消息调度规则是,每条worker线程,每次从全局消息队列global_mq中pop出一个次级消息队列,并从次级消息队列中pop出一条消息,并找到该次级消息队列的所属服务,将消息传给该服务的callback函数,执行指定业务,当逻辑执行完毕时,再将次级消息队列push回全局消息队列中。因为每个服务只有一个次级消息队列,每当一条worker线程,从全局消息队列中pop出一个次级消息队列时,其他线程是拿不到同一个服务,并调用callback函数,因此不用担心一个服务同时在多条线程内消费不同的消息,一个服务执行,不存在并发,线程是安全的。
整个worker线程的消费流程是:
a) worker线程每次,从global_mq中弹出一个次级消息队列,如果次级消息队列为空,则该worker线程投入睡眠,timer线程每隔2.5毫秒会唤醒一条睡眠中的worker线程,并重新尝试从全局消息队列中pop一个次级消息队列出来,当次级消息队列不为空时,进入下一步
b) 根据次级消息的handle,找出其所属的服务(一个skynet_context实例)指针,从次级消息队列中,pop出n条消息(受weight值影响),并且将其作为参数,传给skynet_context的cb函数,并调用它
c) 当完成callback函数调用时,就从global_mq中再pop一个次级消息队列中,供下一次使用,并将本次使用的次级消息队列push回global_mq的尾部
d) 返回第a步