慕课网与菜鸟教程笔记
MongoDB排序:
在MongoDB中使用使用sort()方法对数据进行排序,sort()方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列。
-- col集合中的数据按字段likes的降序排列
db.col.find({},{"title":1,_id:0}).sort({"likes":-1})MongoDB索引;
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种数据结构。
-- key是你要创建的索引字段,1为指定按升序创建索引,-1是按降序来创建索引
db.col.createIndex(keys,options)实例:
db.col.createIndex({"title":1})
-- 使用多个字段创建索引(关系型数据库中称为复合索引)
db.col.createIndex({"title":1,"description":-1})createIndex()接收可选参数,可选参数列表如下:
- background
- unique
- name
- dropDups
- sparse
- expireAfterScecond
- v
- weights
- default_language
- language_override
-- 通过在创建索引时加background:true的选项,让创建工作在后台执行
db.values.createIndex({open:1,close:1},{background:true})MongoDB聚合:
MongoDB聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的结果。有点类似sql语句中的count(*)。
-- MongoDB中聚合的方法使用aggregate()
db.col.aggregate(aggregate_operation)实例:
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by_user: 'runoob.com',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
_id: ObjectId(7df78ad8902d)
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: 'runoob.com',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 10
},
{
_id: ObjectId(7df78ad8902e)
title: 'Neo4j Overview',
description: 'Neo4j is no sql database',
by_user: 'Neo4j',
url: 'http://www.neo4j.com',
tags: ['neo4j', 'database', 'NoSQL'],
likes: 750
},
> db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
{
"result" : [
{
"_id" : "runoob.com",
"num_tutorial" : 2
},
{
"_id" : "Neo4j",
"num_tutorial" : 1
}
],
"ok" : 1
}
以上实例类似sql语句:select by_user,count(*) from mycol group by by_user
下表展示了一些聚合的表达式:
- $sum 计算总和
db.mycol.aggregate([{ $group:{_id:"$by_user",num_tutorial:{$sum:"$likes"} } }])
- $avg 计算平均值
db.mycol.aggregate([{ $group:{_id:"$by_user",num_tutorial:{$avg:"$likes"} } }])
- $min
db.mycol.aggregate([{ $group:{_id:"$by_user",num_tutorial:{$min:"$likes"} } }])
- $max
db.mycol.aggregate([{ $group:{_id:"$by_user",num_tutorial:{$max:"$likes"} } }])
- $push
db.mycol.aggregate([{ $group:{_id:"$by_user",num_tutorial:{$push:"$likes"} } }])
- $addToSet
db.mycol.aggregate([{ $group:{_id:"$by_user",num_tutorial:{$addToSet:"$likes"} } }])
- $first
db.mycol.aggregate([{ $group:{_id:"$by_user",num_tutorial:{$first:"$likes"} } }])
- $last
db.mycol.aggregate([{ $group:{_id:"$by_user",num_tutorial:{$last:"$likes"} } }])MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其他的文档。
MongoDB复制(副本集):
MongoDB复制是将数据同步在多个服务器的过程。
复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性,并可以保证数据的安全性。
复制还允许你从硬件故障和服务中断中恢复数据。
复制:
- 保障数据的安全性
- 数据高可用性(24*7)
- 灾难恢复
- 无需停机维护(如备份,重建索引,压缩)
- 分布式读取数据
MongoDB的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
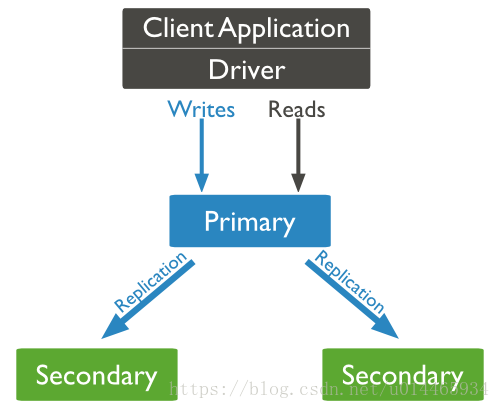
以上结构图中,客户端从主节点读取数据,在客户端写入数据到主节点时,主节点与从节点进行数据交互保障数据的一致性。
副本集特征:
- N个节点的集群
- 任何节点可作为主节点
- 所有写入操作都在主节点上
- 自动故障转移
- 自动恢复
MongoDB分片:
在Mongodb里面存在另一种集群,就是分片技术,可以满足MongoDB数据量大量增长的需求。
当MongoDB存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
为什么使用分片:
- 复制所有的写入操作到主节点
- 延迟的敏感数据会在主节点查询
- 单个副本集限制在12个节点
- 当请求量巨大时会出现内存不足
- 本地磁盘不足
- 垂直扩展价格昂贵
下图展示了在MongoDB中使用分片集群结构分布:
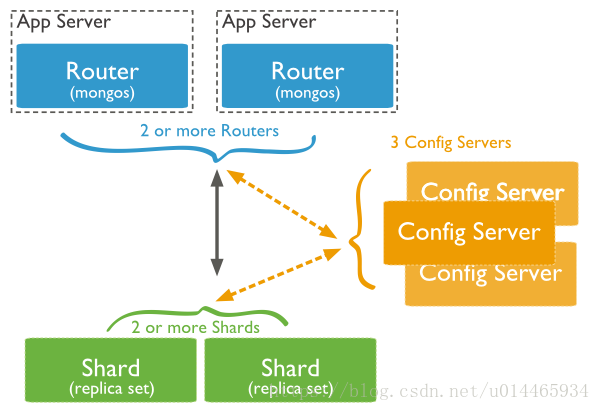
上图中主要有如下所述三个主要组件:
- Shard 用于存储实际的数据块,实际生产环境中一个Shard server角色可由几台机器组成一个replica set承担,防止主机单点故障
- Config Server mongod实例,存储了整个ClusterMetadata,其中包括chuck信息。
- Query Routers 前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
MongoDB备份与恢复:
在Mongodb中我们使用mongodump命令来备份MongoDB数据。该命令可以导出所有数据到指定目录中。
Mongodump命令可以通过参数指定导出的数据量级转存的服务器。
mongodump -h dbhost -d dbname -0 dbdirectory- -h MongoDB所在服务器地址
- -d 需要备份的数据库实例
- -o 备份的数据存放位置
mongodb使用mongorestore命令来恢复备份的数据。
mongorestore -h <hostname><:port> -d dbname <path> - -h<:port> MongoDB所在服务器地址
- -d 需要恢复的数据库实例
- < path > 设置备份数据所在位置,例如:c:\data\dump\test。
MongoDB监控:
在你已经安装部署并允许MongoDB服务后,你必须要了解MongoDB的运行情况,并查看MongoDB的性能。这样在大流量得情况下可以很好的应对并保证MongoDB正常运作。
MongoDB中提供了mongostat 和 mongotop 两个命令来监控MongoDB的运行情况。
mongosta是mongodb自带的状态检测工具,在命令行下使用。它会间隔固定时间获取mongodb的当前运行状态,并输出。
- 启动你的Mongod服务,进入到你安装的MongoDB目录下的bin目录,然后输入mongostat命令
D:\set up\mongod\bin>mongostatmongotop命令:
mongotop也是mongodb下的一个内置工具,mongotop提供了一个方法,用来跟踪一个MongoDB的实例,查看哪些大量的时间花费在读取和写入数据。mongotop提供每个集合的水平统计数据。默认情况下。mongotop返回值的每一秒。
启动你的Mongod服务,进入到你安装的MongoDB目录下的bin目录,然后输入mongotop命令,如下所示:
D:\set up\mongodb\bin >mongotop