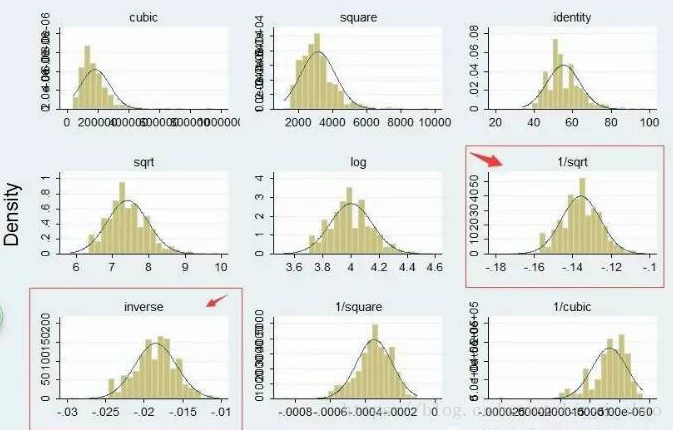
机器学习初学者常常会将拿来的数据,直接喂入算法训练,不得不说,再进一步深入研究中,数据标准化是他们不得不搞清楚的难题。什么是数据标准化,标准化的作用是啥,什么情况下应该对应什么方法尼?
一、关于什么标准化,这里就不阐述了,帖子太多了。我需要说明的是,数据标准化和归一化其实是一回事,只是归一化常为将数据转换到(0-1)之间,标准化则不一定。
二、数据标准化:四作用一缺点(注意:不同方法,实现的作用不尽相同哦,后面有整理)
1、消除量纲;2、让不同指标具有可比性;3、提高迭代求解精度
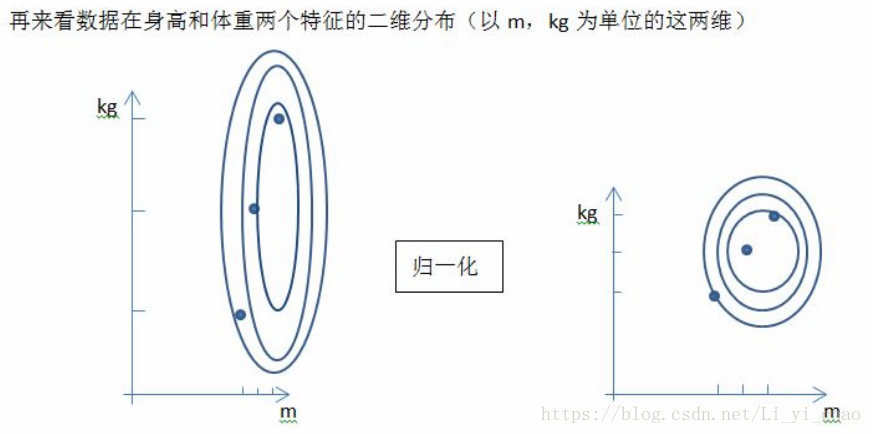
一个图诠释这三个作用:
千克与米的量纲统一,使得体重与身高对目标变量的权重趋同。
若算法涉及距离计算时(如欧氏距离),图中x2的取值范围比较小,涉及到距离计算时其对结果的影响远比x1带来的小,所以这就会造成精度的损失。所以标准化可以让各个特征对结果做出的贡献相同。
4、数据标准化还有一个容易被忽略的好处是:提升模型的收敛速度
导致在梯度下降时,梯度的方向为垂直等高线的方向而走之字形路线,这样会使迭代很慢,相比之下,右图的迭代就会很快(理解:也就是步长走多走少方向总是对的,不会走偏)


5、缺点:当数据已某种方式被压缩时,可能导致部分数据信息的损失
三、什么情况下需要标准化
这才是重点,但如果你顾全了标准化的优缺点,这一点自然应用自如。这里我说下自己的见解
1、基于树模型的算法,如果没有强制要求,不需要做标准化(信息损失)
2、基于平方损失的最小二乘法OLS不需要标准化。
3、聚类、分类、回归等,涉及到距离计算的模型需要标准化。
四、标准化方法及适用情况:
1、 min-max标准化——可提升模型的收敛速度;但无消除量纲的效果;缺陷是当有新数据时,max、min可能变化,
在不涉及距离度量、协方差计算、数据不符合正态分布的时候适用,如RGB图像转换为灰度图像后,将值限定在[0-255]。
2、 z-score 标准化——实现标准化所有效果;但要求原始数据近似为高斯分布,否则归一化的效果会变得很糟糕。
在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,Z-score standardization表现更好。
五、说明
如果你需要z-score转换,但原始数据不满足正态分布,需要先做正态分布转换,传统方法有九种,需要尝试一种适用数据满足正态分布的方式出来,再z-score标准化。