纯当成笔记记录
#--*--coding:utf-8
import pandas as pd
import tensorflow as tf
import tensorlayer as tl
import urllib
from bs4 import BeautifulSoup
import re
url = "http://baike.baidu.com/item/%E6%A5%9A%E4%B9%94%E4%BC%A0/17156299#"
response = urllib.request.urlopen(url)
con = response.read()
cont = BeautifulSoup(con,from_encoding='utf-8')
content = cont.find('ul',{'id':'dramaSerialList'})
content = str(content)
content1 = re.sub(r'<[^>]+>','',content)
f = open('chuqiaozhuan.txt','w',encoding='utf-8')
f.write(content1)
f.close()
#爬取名字
f = open('chuqiao_name.txt','w',encoding='utf-8')
name_content = cont.find_all("dl",{'class':'info'})
name_list = []
for i in name_content:
name_d = i.get_text().strip().split('\n')[0]
names = name_d.split('\xa0')[2]
names = [name for name in names.split('/')]
name_list.extend(names)
# print(name_list)
name_all = '\n'.join(name_list)
f.write(name_all)
f.close()
import jieba
import jieba.analyse as analy
import jieba.posseg as pseg
jieba.load_userdict('chuqiao_dict.txt')
# analy.set_stop_words('StopwordsCN.txt')
stopword = [line.strip() for line in open('StopwordsCN.txt',encoding='utf-8').readlines()]
fr = open('chuqiaozhuan.txt','r',encoding='utf-8')
con = fr.readlines()
fw = open('chuqiao_content.txt','w',encoding='utf-8')
for i in con:
if len(i)<=20:
pass
else:
# words = pseg.cut(i)
# outstr = ''
# for word,flag in words:
# outstr += word
# outstr += ' '
# fw.write(outstr)
# fw.write('\n')
w1 = i.split("。")
for j in w1:
# w2 = re.sub(r',|。|?|:|“|”|!','',j.strip())
w3 = list(jieba.cut(j))
w4 = [w for w in w3 if w not in stopword]
outstr = ''
for word in w4:
outstr += word
outstr += ' '
fw.write(outstr.strip())
fw.write('\n')
fw.close()
from __future__ import unicode_literals
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
font_yahei_consolas = FontProperties('SimHei')
%matplotlib inline
with open('chuqiao_name.txt',encoding='utf-8') as f1:
data1 = f1.readlines()
with open('chuqiao_content.txt',encoding='utf-8') as f2:
data2 = f2.read()
count = []
for name in data1:
count.append([name.strip(),data2.count(name.strip())])
# print(count)
count.sort(key=lambda x:x[1])
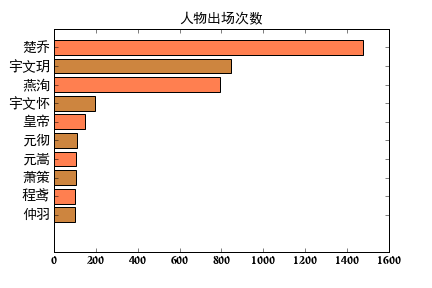
ay,ax = plt.subplots()
numbers = [x[1] for x in count[-10:]]
names = [x[0] for x in count[-10:]]
ax.barh(range(10),numbers,color=['peru','coral'],align='center')
ax.set_title('人物出场次数',fontsize=14,fontproperties=font_yahei_consolas)
ax.set_yticks(range(10))
ax.set_yticklabels(names,fontsize=14,fontproperties=font_yahei_consolas)
plt.savefig('fig/人物出场次数.png')
import networkx as nx
with open('chuqiao_name.txt',encoding='utf-8') as f1:
name_list = [name.strip('\n') for name in f1.readlines()]
with open('chuqiao_content.txt',encoding='utf-8') as f2:
line_contents = f2.readlines()
name_combination = []
for line in line_contents:
names = [name.strip('\n') for name in line.split(' ') if name.strip('\n') in name_list]
names = list(set(names))
size = len(names)
if size > 1:
# print(names)
for i in range(size):
for j in range(i+1,size):
name_combination.append((names[i],names[j]))
# #以下两句是显示中文的方法
# from matplotlib.pylab import *
# mpl.rcParams['font.sans-serif'] = ['SimHei'] #无效的方法
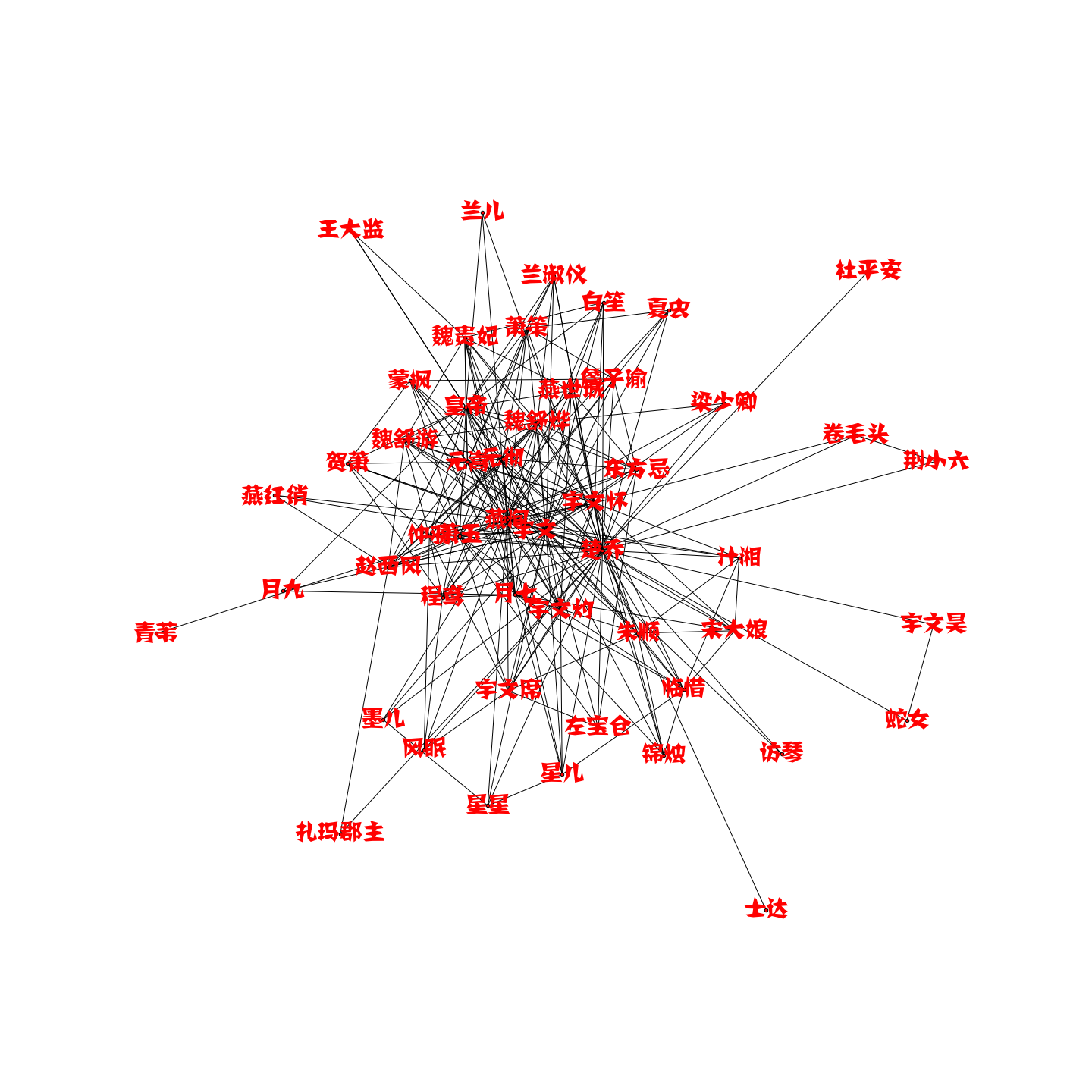
plt.figure(figsize=(20,20))
G = nx.Graph()
for ele in name_combination:
G.add_edge(ele[0],ele[1])
nx.draw(G,node_size=20,font_size=30,font_color='r',with_labels=True)
print(list(G.nodes()))
plt.savefig('fig/personage_relationship.png')

with open('chuqiao_content.txt',encoding='utf-8') as f2:
content = f2.read()
f2.close()
from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator
background_Image = plt.imread('fig/bgImage.jpg')
font = 'Vera.ttf'
wc = WordCloud(background_color='white',mask=background_Image,max_words=2000,stopwords=STOPWORDS,font_path=font,max_font_size=100,random_state=42,scale=3)
wc.generate(content)
image_colors = ImageColorGenerator(background_Image)
wc.recolor(color_func=image_colors)
plt.imshow(wc)
plt.savefig('fig/词云.png')
