YARN的调度器和调度算法总是一个让人感兴趣的方面。比如FIFO,capacity和fair调度算法。每个调度算法都有其自己的特征,而调度的决策受许多因素影响,如公平性、容量保证和资源的可靠性等。在部署一个调度算法到生产集群之前,评估一个调度算法是非常重要的,不幸的是,评估一个调度算法不是那么容易的,评估一个实际的集群是非常耗费时间和成本的,并且很难找到一个足够大的集群用来评测。因此,在一些特定负载下,设计一个能够评估调度算法的模拟器是非常有用的。
YARN 模拟器是一个能够在一台机器上装载应用程序,模拟一个大规模的YARN 集群的工具。模拟器使用实际的YARN ResourceManager,在相同的JAVA 虚拟内,通过处理和调度NM/AMs 心跳事件,模拟NodeManager 和ApplicationMaster 来移除网络因素。
集群的规模和应用负载可以从配置文件中加载,这些配置文件可以利用 Apache Rumen 从JobHistory Files 中直接生成。
模拟器将在执行时生成实时指标,包括:
1.整个集群和每个队列的资源使用率,它们可以用于配置集群和队列的容量。
2.详细的应用程序执行跟踪记录(在模拟时被记录)可以用来分析,以便理解和验证调度器的行为(包括个人工作的周转时间、生产量、公平性、容量保证等)。
3.调度器算法的几个关键指标,比如每个调度器操作的时间成本(分配、处理等等),这些都可以帮助Hadoop开发人员找出影响其可伸缩性和性能的代码。
这些指标都可以通过web页面展现出来。
目标:
1.使用真实的工作跟踪,在没有实际集群的情况下测试调度器的性能。
2.能够模拟实际的工作负载。
架构:
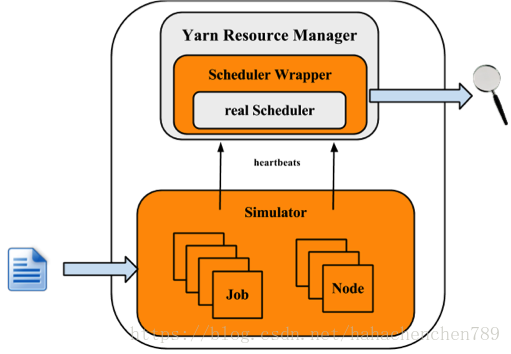
可以看出,模拟器主要模拟的是Job和Node,但RM和调度算法是真实的。
模拟器得到负载跟踪的输入,并获取到集群和应用的信息。对每个NM 和AM,构造一个模拟器来模拟它们的运行,所有的NM 和AM 模拟器都在一个线程池中运行。模拟器再利用RM,并在调度器外构建一个Wrapper,这个Scheduler Wrapper 可以跟踪Scheduler。
使用
sls的功能实现主要在/share/hadoop/tools/sls中,sls文件夹包括四个文件夹:bin,html,sample-conf,sample-data。
bin: 包含了sls的运行脚本,也就是启动命令
html:包含html、css、js文件,来实现实时追踪和web显示。
sample-conf:sls的配置文件
sample-data:提供了一个rumen trace的示例文件,可以用来作为sls的输入。
步骤一:配置hadoop和sls
hadoop的配置文件都在/etc/hadoop目录下,具体配置可参考博文:
https://blog.csdn.net/hahachenchen789/article/details/79917316
而对于sls的配置,hadoop也给出了几个示例:/share/hadoop/tools/sls/sample-conf/
默认而言,sls会加载/share/hadoop/tools/sls/sample-conf/sls-runner.xml文件。
接下来详细说明sls-runner.xml配置文件中的配置选项:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- SLSRunner configuration -->
<property>
<name>yarn.sls.runner.pool.size</name>
<value>100</value>
</property>
<!-- Nodes configuration -->
<property>
<name>yarn.sls.nm.memory.mb</name>
<value>10240</value>
</property>
<property>
<name>yarn.sls.nm.vcores</name>
<value>10</value>
</property>
<property>
<name>yarn.sls.nm.heartbeat.interval.ms</name>
<value>1000</value>
</property>
<!-- Apps configuration -->
<property>
<name>yarn.sls.am.heartbeat.interval.ms</name>
<value>1000</value>
</property>
<property>
<name>yarn.sls.am.type.mapreduce</name>
<value>org.apache.hadoop.yarn.sls.appmaster.MRAMSimulator</value>
</property>
<!-- Containers configuration -->
<property>
<name>yarn.sls.container.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.sls.container.vcores</name>
<value>1</value>
</property>
<!-- metrics -->
<property>
<name>yarn.sls.metrics.switch</name>
<value>ON</value>
</property>
<property>
<name>yarn.sls.metrics.web.address.port</name>
<value>10001</value>
</property>
<property>
<name>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fifo.FifoScheduler</name>
<value>org.apache.hadoop.yarn.sls.scheduler.FifoSchedulerMetrics</value>
</property>
<property>
<name>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</name>
<value>org.apache.hadoop.yarn.sls.scheduler.FairSchedulerMetrics</value>
</property>
<property>
<name>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</name>
<value>org.apache.hadoop.yarn.sls.scheduler.CapacitySchedulerMetrics</value>
</property>
</configuration>
接下来逐条分析:
yarn.sls.runner.pool.size
sls采用线程池来模拟NM和AM的运行,该参数设定了线程池中最大的线程数量。
yarn.sls.nm.memory.mb
每一个NM的总内存
yarn.sls.nm.vcores
每一个NM的总vCores,总虚拟核心?
yarn.sls.nm.heartbeat.interval.ms
NM的心跳间隔信息
yarn.sls.am.heartbeat.interval.ms
AM的心跳间隔信息
yarn.sls.am.type.mapreduce
AM对于MapReduce的具体实现,用户也可以采用其他应用实现。这里就采用MapReduce作为例子。
yarn.sls.container.memory.mb
对于每一个container容器的内存需求
yarn.sls.container.vcores
对于每一个container容器的vCores数量。
yarn.sls.runner.metrics.switch
SLS已整合了 Metrics来衡量关键组件和操作的行为,包括运行应用程序和容器、集群可用资源,调度器操作时间成本,等。如果开关yarn.sls.runner.metrics.switch设置为ON,Metrics将运行并把它输出在用户指定的输出目录(-output-dir)中。用户可以在模拟器运行期间跟踪这些信息,还可以在运行之后分析这些日志,以评估调度程序的性能。
yarn.sls.metrics.web.address.port
SLS提供给用户观察实时监控的端口,默认值为10001
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fifo.FifoSchedulerFIFO调度器的具体实现
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
Fair调度器的具体实现
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
Capacity调度器的具体实现
步骤二:运行SLS
SLS支持两种类型的input files:rumen traces和sls traces。slsrun.sh脚本负责运行sls:
$ cd $HADOOP_ROOT/share/hadoop/tools/sls
$ bin/slsrun.sh
--input-rumen |--input-sls=<TRACE_FILE1,TRACE_FILE2,...>
--output-dir=<SLS_SIMULATION_OUTPUT_DIRECTORY> [--nodes=<SLS_NODES_FILE>]
[--track-jobs=<JOBID1,JOBID2,...>] [--print-simulation]
--input-rumen: 输入是rumen trace文件,示例为/share/hadoop/tools/sls/sample-data/2jobs2min-rumen-jh.json.
--input-sls: 输入是sls自己的格式文件,sls file。sls提供了一个工具来将rumen traces文件转换为sls trace:rumen2sls.sh(/share/hadoop/tools/sls/bin/)。关于SLS输入JSON文件的示例,见最后。
--output-dir: 输出监控数据和日志的目录
--nodes: 集群的拓扑结构,默认情况下,sls采用input json file中的拓扑,用户也可以指定一个新的拓扑结构。
--track-jobs: 在模拟器运行过程中跟踪的特定任务,由逗号分隔。
--print-simulation: 该参数决定了是否在模拟器运行前打印仿真信息,包括每个应用程序的节点、应用程序、任务和信息的数量。如果需要,只需要添加上该参数即可。
例子:
采用rumen traces输入:
$ bin/slsrun.sh --input-sls=./my-input/sls-jobs.json --nodes=./my-input/sls-nodes.json --output-dir=./my-logs/ --track-jobs=job_1369942127770_1205,job_1369942127770_1206 --print-simulation
采用sls输入:
$ bin/slsrun.sh --input-sls=./my-input/sls-jobs.json --nodes=./my-input/sls-nodes.json --output-dir=./my-logs/ --print-simulation
可以看出,sls输入更为简单。
那么rumen2sls.sh工具如何使用呢:
$ bin/rumen2sls.sh
--rumen-file=<RUMEN_FILE>
--output-dir=<SLS_OUTPUT_DIRECTORY>
[--output-prefix=<SLS_FILE_PREFIX>]
--rumen-file: rumen 的输入文件
--output-dir: 生成sls格式文件的目录,包含两个文件,sls trace file :包含所有job和task的信息,该文件用于slsrun的input-sls参数。另一个文件则是slsrun的-node参数的文件,也就是集群拓扑文件。
数据收集:
有两种数据收集方式,一种是offline,也就是slsrun命令的output-dir指定的文件。
该目录下会生成如下文件和文件夹:
realtimetrack.json: 每隔1秒记录所有实时跟踪日志。
jobruntime.csv: 在模拟器中记录所有作业的开始和结束时间。
metrics文件夹:metric生成的日志
web实时数据收集
可通过http://host:port/simulate实时追踪运行参数和数据。
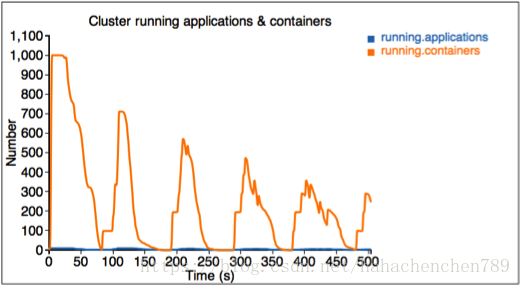
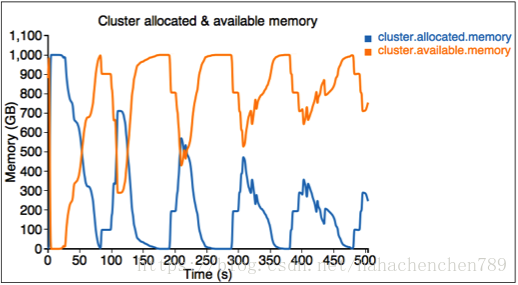
附录:
sls json input file:
该文件是slsrun中的-input-sls输入的文件,也是rumen2sls生成的sls文件:
包含2个job,第一个job有3个tasks,第二个job有2个tasks:
{
"am.type" : "mapreduce",
"job.start.ms" : 0,
"job.end.ms" : 95375,
"job.queue.name" : "sls_queue_1",
"job.id" : "job_1",
"job.user" : "default",
"job.tasks" : [ {
"container.host" : "/default-rack/node1",
"container.start.ms" : 6664,
"container.end.ms" : 23707,
"container.priority" : 20,
"container.type" : "map"
}, {
"container.host" : "/default-rack/node3",
"container.start.ms" : 6665,
"container.end.ms" : 21593,
"container.priority" : 20,
"container.type" : "map"
}, {
"container.host" : "/default-rack/node2",
"container.start.ms" : 68770,
"container.end.ms" : 86613,
"container.priority" : 20,
"container.type" : "map"
} ]
}
{
"am.type" : "mapreduce",
"job.start.ms" : 105204,
"job.end.ms" : 197256,
"job.queue.name" : "sls_queue_2",
"job.id" : "job_2",
"job.user" : "default",
"job.tasks" : [ {
"container.host" : "/default-rack/node1",
"container.start.ms" : 111822,
"container.end.ms" : 133985,
"container.priority" : 20,
"container.type" : "map"
}, {
"container.host" : "/default-rack/node2",
"container.start.ms" : 111788,
"container.end.ms" : 131377,
"container.priority" : 20,
"container.type" : "map"
} ]
}
input topology file:
slsrun的-node参数,集群拓扑结构 输入。也是rumen2sls生成的第二个文件。
下面表示1个机架上三个节点:
{
"rack" : "default-rack",
"nodes" : [ {
"node" : "node1"
}, {
"node" : "node2"
}, {
"node" : "node3"
}]
}