简述
能力调度器在生产实践中是用的较多的一种模式,今天单机来实践一下。hadoop版本我这里选用了3.1.2,spark是用的2.4.3
配置
- yarn-site.xml
这里主要配置yarn.resourcemanager.scheduler.class属性就好。
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>dc-sit-225</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>0.0.0.0:8081</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>18432</value>
<discription>每个节点可用内存,单位MB,默认是8g,这里调整为18g</discription>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
<discription>单个任务可申请最少内存,默认1024MB</discription>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
<discription>单个任务可申请最大内存,默认8192MB,</discription>
</property>
</configuration>
- capacity-scheduler.xml
我们分别配置三个队列default、api、dev
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,api,dev</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.capacity</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.acl_administer_queue</name>
<value>root</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.acl_submit_applications</name>
<value>root</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>30</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>35</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.api.capacity</name>
<value>45</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.api.maximum-capacity</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>25</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>30</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.api.acl_administer_queue</name>
<value>root,hadoop1</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.api.acl_submit_applications</name>
<value>root,hadoop1</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.acl_administer_queue</name>
<value>root,hadoop2</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.acl_submit_applications</name>
<value>root,hadoop2</value>
</property>
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
</property>
</configuration>
- sbin/start-yarn.sh 及sbin/stop-yarn.sh
如果是root启动、上诉文件开头添加
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
测试
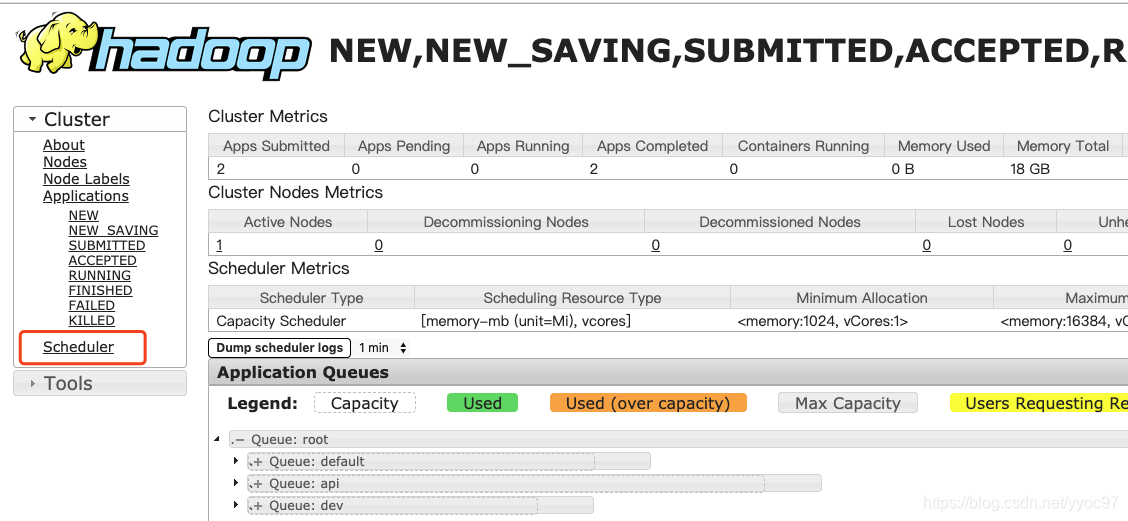
通过sbin/start-yarn.sh启动,之后我们使用jps查看ResourceManager 和NodeManager是否存在。如果没有则需要查看对应的日志。然后我们打开yarn的web-ui界面,默认端口是8088,我这里配置的8081。点击Scheduler如果看到root下有三个子Queue,说明我们的配置是正常的。
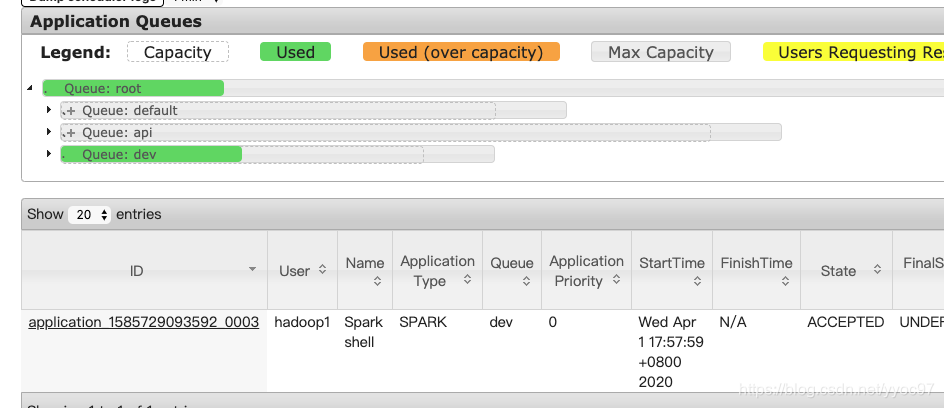
之后可以通过spark-shell来指定yarn中的队列。
[hadoop1@dc-sit-225 spark-2.4.3]$ bin/spark-shell --master yarn-client --queue dev
Warning: Master yarn-client is deprecated since 2.0. Please use master "yarn" with specified deploy mode instead.
2020-04-01 16:20:13,878 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
2020-04-01 16:20:18,334 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
Spark context Web UI available at http://dc-sit-225:4040
Spark context available as 'sc' (master = yarn, app id = application_1585729093592_0002).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.3
/_/
Using Scala version 2.12.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171)
Type in expressions to have them evaluated.
Type :help for more information.
scala> :quit
[hadoop1@dc-sit-225 spark-2.4.3]$
然后在ui中查看会发现dev队列中有任务在执行说明正常。
异常
下面说着过程中遇到的主要异常。
- 异常1
2020-04-01 15:09:25,370 INFO org.apache.hadoop.conf.Configuration: found resource capacity-scheduler.xml at file:/data/server/hadoop-3.1.2/etc/hadoop/capacity-sch
eduler.xml
2020-04-01 15:09:25,380 ERROR org.apache.hadoop.conf.Configuration: error parsing conf java.io.BufferedInputStream@7ceb3185
com.ctc.wstx.exc.WstxParsingException: Illegal processing instruction target ("xml"); xml (case insensitive) is reserved by the specs.
at [row,col {unknown-source}]: [2,5]
at com.ctc.wstx.sr.StreamScanner.constructWfcException(StreamScanner.java:621)
at com.ctc.wstx.sr.StreamScanner.throwParseError(StreamScanner.java:491)
at com.ctc.wstx.sr.BasicStreamReader.readPIPrimary(BasicStreamReader.java:4019)
at com.ctc.wstx.sr.BasicStreamReader.nextFromProlog(BasicStreamReader.java:2141)
at com.ctc.wstx.sr.BasicStreamReader.next(BasicStreamReader.java:1181)
at org.apache.hadoop.conf.Configuration$Parser.parseNext(Configuration.java:3277)
at org.apache.hadoop.conf.Configuration$Parser.parse(Configuration.java:3071)
at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:2964)
at org.apache.hadoop.conf.Configuration.loadResources(Configuration.java:2930)
at org.apache.hadoop.conf.Configuration.getProps(Configuration.java:2805)
at org.apache.hadoop.conf.Configuration.<init>(Configuration.java:822)
at org.apache.hadoop.yarn.server.resourcemanager.reservation.ReservationSchedulerConfiguration.<init>(ReservationSchedulerConfiguration.java:64)
at org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacitySchedulerConfiguration.<init>(CapacitySchedulerConfiguration.java:374)
at org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.conf.FileBasedCSConfigurationProvider.loadConfiguration(FileBasedCSConfigurationProvid
er.java:60)
上面这个是因为我拷贝网上的配置,可能一些空格编码或者tab健的影响、我把xml中每行的空格去重,然后手动格式化后正常。
- 异常2
2020-04-01 16:14:03,503 ERROR org.apache.hadoop.yarn.server.nodemanager.containermanager.AuxServices: Failed to initialize spark2_shuffle
java.lang.RuntimeException: No class defined for spark2_shuffle
at org.apache.hadoop.yarn.server.nodemanager.containermanager.AuxServices.serviceInit(AuxServices.java:274)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.service.CompositeService.serviceInit(CompositeService.java:108)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.ContainerManagerImpl.serviceInit(ContainerManagerImpl.java:318)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.service.CompositeService.serviceInit(CompositeService.java:108)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.serviceInit(NodeManager.java:477)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.initAndStartNodeManager(NodeManager.java:933)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.main(NodeManager.java:1013)
上诉是因为我在yarn.nodemanager.aux-services属性中多配置了spark2_shuffle的原因,记得之前的hadoop版本是要加这个配置的。现在好像只需要mapreduce_shuffle就可以了。
- 异常3
Warning: Master yarn-client is deprecated since 2.0. Please use master "yarn" with specified deploy mode instead.
2020-04-01 16:18:32,393 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
2020-04-01 16:18:36,924 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
yarn提交任务后一直卡在这个位置,但是用spark自身的master就不会,resources和spark master均无异常日志。我们找了下原因才发现是NodeManager并没有正常启动,所以yarn一直没有节点可以分配任务。yarn node -all -list查看节点总数为0,所以说每做一步后进行测试还是很有必要的。NodeManager没启动成功的原因正是异常2中spark2_shuffle配置的原因。
结尾
上述使用到了多个队列的指定,能够进行资源隔离。但是用户层面的隔离还需要借助Kerberos等身份认证组件。
配置参考 https://www.cnblogs.com/xiaodf/p/6266201.html#221
