【数据结构与算法】第五章:散列
标签(空格分隔): 【数据结构与算法】
第五章:散列
- 散列表(hash table):只支持二叉查找树所允许的一部分操作.
- 散列(hashing):一种用于以常数平均时间执行插入,删除和查找的级数.
5.1 一般想法
- 理想的散列表数据结构只不过是一个包含有关键字的具体固定大小的数组.一般而言,这个关键字就是带有一个相关之的字符串.
- 我们把表的大小记作 ,并将其理解为散列数据结构的一部分而不仅仅是浮动于全局的某个变量.通常的习惯是让表从 到 变化.
- 散列函数(hash function):每个关键字映射到从 到 这个范围中的某个数,并且被放到适当额单元中.最理想的情况是,运算简单并且任何两个不同的关键字映射到不同的单元.但是这是不可能的,因为单元的数目是有限的,而关键字是用不完的.
- 冲突(collision):当两个关键字散列到同一个值的时候.
5.2 散列函数
- 当关键字是整数时,我们保证表的大小是一个素数,可以直接返回
- 当关键字是字符串时,散列函数需要仔细选择.
- 一种选择方法是可以将字符串中的字符的 ASCII 码值相加起来.如下
//将字符逐个相加来处理整个字符串
typedef unsigned int Index;
Index Hash( const char *Key, int TableSize){
unsigned int HashVal = 0;
while( *Key != '\0')
HashVal += *Key++;
return HashVal % TableSize;
}上述散列函数描述起来简单并且能够很快的算出答案.但是,如果表很大,那么函数并不能很好的分配关键字. 当 并假设所有的关键字之多 8 个字符长,那么由于 类型的变量值最多为127,因此散列函数的取值处于 0 到 1016 之间.这显然是一种不均匀的分配.
2.另一种散列函数如下
Index Hash2( const char *Key, int TableSize){
return( Key[0] + 27 * Key[1] + 729 * Key[2]) % TableSize;
}这个散列函数假设
至少有两个字符外加 NULL结束符,值 27 表示英文字母的个数外加一个空格.
假设我们的表的大小依旧是 10007 并且如果字符串具有随机性,由于
因此我们可以得到一个合理的均匀分配.
但是,考虑到英文不是随机的,具有三个字母的单词数目只有2851个,远小于三个英文字母的排列数.因此当散列表足够大的时候这个函数还是不合适的.
3.第三种散列函数
Index Hash3( const char *Key, int TableSize){
unsigned int HashVal = 0;
while( *Key != '\0')
HashVal = ( HashVal<<5) + *Key++;
return HashVal % TableSize;
}5.3 解决冲突的方法
5.3.1 分离链接法
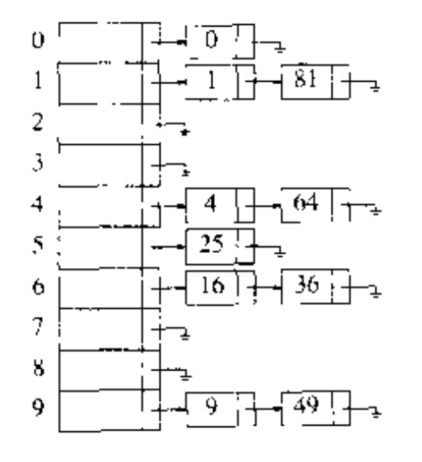
分离链接法(separate chaining):将散列到同一个值的所有元素保留到一个表中.为了方便,这些表都有表头.如下图.
- Find操作,我们使用散列函数来确定究竟是哪一个表.此时,我们通常的方式遍历该表并返回所找到的被查找项所在的位置.
- Insert操作,我们遍历整个表以检查该元素是否已经处在适当的位置.如果要插入重复元,那么通常要留出一个额外的域,这个域当重复元出现时候增加1.如果这个元素是个新元素,那么它或者被插入表的前端,或者被擦汗如到表的末尾.又是新元素插入到表的前端不仅是因为方便,而且新插入的元素可能最先被访问.
struct ListNode;
typedef struct ListNode *Position;
struct HashTbl;
typedef struct HashTbl *HashTable;
struct ListNode{
ElemeentType Element;
Position Next;
};
struct HashTbl{
int TableSize;
List *TheLists; //指向ListNode指针的指针
};
HashTable InitializeTable( int TableSize);
void DestroyTable( HashTable H);
Position Find( ElementType Key, HashTable H);
void Insert( ElementType Key, HashTable H);
ElementType Retrieve( Position P);//初始化过程
HashTable InitializeTable( int TableSize){
HashTable H;
int i;
if( TableSize < MinTableSize){
Error(" Table is so small");
return NULL;
}
H = ( HashTable)malloc( sizeof( struct HashTbl));
if( H == NULL)
FatalError(" Out of space");
H->TableSize = NextPrime( TableSize);
H->TheLists = malloc( sizeof( List) * H->TableSize);
if( H->TheLists == NULL)
FatalError(" Out of space");
for( i=0; i<H->TableSize; i++){
H->TheList[i] = ( Position)malloc( sizeof( struct ListNode));
if( H->TheList[i] == NULL)
FatalError(" Out of space");
else
H->TheLists[i]->Next == NULL;
}
}
//寻找并返回一个指针
Position Find( ElementType Key, HashTable H){
Position P;
List L;
L = H->TheLists[ Hash( key, H->TableSize)];
P = L->Next;//L是头指针
while( P!=NULL && P->Element !=Key)
P = P->Next;
return P;
}
//插入
void Insert( ElementType Key, HashTable H){
Position Pos, NewCell;
List L;
Pos = Find( Key, H);
if( Pos == NULL){
NewCell = ( Position)malloc( sizeof( struct ListNode));
if( NewCell == NULL)
FatalError(" Out of space");
else{
L = H->TheLists[ Hash( Key, H->TableSize)];
NewCell->Next = L->Next;
NewCell->Element = Key; //当是整数时,Find同.
L->Next = NewCell;
}
}
}- 装填因子(load factor) :散列表中元素的个数与散列表大小的比值.【数据结构与算法】第五章:散列
标签(空格分隔): 【数据结构与算法】
第五章:散列

- 散列表(hash table):只支持二叉查找树所允许的一部分操作.
- 散列(hashing):一种用于以常数平均时间执行插入,删除和查找的级数.
5.1 一般想法
- 理想的散列表数据结构只不过是一个包含有关键字的具体固定大小的数组.一般而言,这个关键字就是带有一个相关之的字符串.
- 我们把表的大小记作 ,并将其理解为散列数据结构的一部分而不仅仅是浮动于全局的某个变量.通常的习惯是让表从 到 变化.
- 散列函数(hash function):每个关键字映射到从 到 这个范围中的某个数,并且被放到适当额单元中.最理想的情况是,运算简单并且任何两个不同的关键字映射到不同的单元.但是这是不可能的,因为单元的数目是有限的,而关键字是用不完的.
- 冲突(collision):当两个关键字散列到同一个值的时候.
5.2 散列函数
- 当关键字是整数时,我们保证表的大小是一个素数,可以直接返回
- 当关键字是字符串时,散列函数需要仔细选择.
- 一种选择方法是可以将字符串中的字符的 ASCII 码值相加起来.如下
//将字符逐个相加来处理整个字符串
typedef unsigned int Index;
Index Hash( const char *Key, int TableSize){
unsigned int HashVal = 0;
while( *Key != '\0')
HashVal += *Key++;
return HashVal % TableSize;
}上述散列函数描述起来简单并且能够很快的算出答案.但是,如果表很大,那么函数并不能很好的分配关键字. 当 并假设所有的关键字之多 8 个字符长,那么由于 类型的变量值最多为127,因此散列函数的取值处于 0 到 1016 之间.这显然是一种不均匀的分配.
2.另一种散列函数如下
Index Hash2( const char *Key, int TableSize){
return( Key[0] + 27 * Key[1] + 729 * Key[2]) % TableSize;
}这个散列函数假设
至少有两个字符外加 NULL结束符,值 27 表示英文字母的个数外加一个空格.
假设我们的表的大小依旧是 10007 并且如果字符串具有随机性,由于
因此我们可以得到一个合理的均匀分配.
但是,考虑到英文不是随机的,具有三个字母的单词数目只有2851个,远小于三个英文字母的排列数.因此当散列表足够大的时候这个函数还是不合适的.
3.第三种散列函数
Index Hash3( const char *Key, int TableSize){
unsigned int HashVal = 0;
while( *Key != '\0')
HashVal = ( HashVal<<5) + *Key++;
return HashVal % TableSize;
}5.3 解决冲突的方法
5.3.1 分离链接法
分离链接法(separate chaining):将散列到同一个值的所有元素保留到一个表中.为了方便,这些表都有表头.如下图.
- Find操作,我们使用散列函数来确定究竟是哪一个表.此时,我们通常的方式遍历该表并返回所找到的被查找项所在的位置.
- Insert操作,我们遍历整个表以检查该元素是否已经处在适当的位置.如果要插入重复元,那么通常要留出一个额外的域,这个域当重复元出现时候增加1.如果这个元素是个新元素,那么它或者被插入表的前端,或者被擦汗如到表的末尾.又是新元素插入到表的前端不仅是因为方便,而且新插入的元素可能最先被访问.
struct ListNode;
typedef struct ListNode *Position;
struct HashTbl;
typedef struct HashTbl *HashTable;
struct ListNode{
ElemeentType Element;
Position Next;
};
struct HashTbl{
int TableSize;
List *TheLists; //指向ListNode指针的指针
};
HashTable InitializeTable( int TableSize);
void DestroyTable( HashTable H);
Position Find( ElementType Key, HashTable H);
void Insert( ElementType Key, HashTable H);
ElementType Retrieve( Position P);//初始化过程
HashTable InitializeTable( int TableSize){
HashTable H;
int i;
if( TableSize < MinTableSize){
Error(" Table is so small");
return NULL;
}
H = ( HashTable)malloc( sizeof( struct HashTbl));
if( H == NULL)
FatalError(" Out of space");
H->TableSize = NextPrime( TableSize);
H->TheLists = malloc( sizeof( List) * H->TableSize);
if( H->TheLists == NULL)
FatalError(" Out of space");
for( i=0; i<H->TableSize; i++){
H->TheList[i] = ( Position)malloc( sizeof( struct ListNode));
if( H->TheList[i] == NULL)
FatalError(" Out of space");
else
H->TheLists[i]->Next == NULL;
}
}
//寻找并返回一个指针
Position Find( ElementType Key, HashTable H){
Position P;
List L;
L = H->TheLists[ Hash( key, H->TableSize)];
P = L->Next;//L是头指针
while( P!=NULL && P->Element !=Key)
P = P->Next;
return P;
}
//插入
void Insert( ElementType Key, HashTable H){
Position Pos, NewCell;
List L;
Pos = Find( Key, H);
if( Pos == NULL){
NewCell = ( Position)malloc( sizeof( struct ListNode));
if( NewCell == NULL)
FatalError(" Out of space");
else{
L = H->TheLists[ Hash( Key, H->TableSize)];
NewCell->Next = L->Next;
NewCell->Element = Key; //当是整数时,Find同.
L->Next = NewCell;
}
}
}- 装填因子(load factor) :散列表中元素的个数与散列表大小的比值.
