- P2P简介
P2P顾名思义,就是点对点的意思,从事网络行业的朋友应该不陌生。P2P软件就是采用P2P原理,实现高速下载的软件,例如最常用的P2P软件的有:迅雷、爱奇艺、腾讯视频等。 P2P虽然提升了下载速度,但它是以共享自己的资源为代价的,在后台会默默地上传本地的文件到网络,这样会大量占用带宽,影响其他业务。
- P2P流特征分析
对于网络开发人员,最痛苦的就是处理客户网络卡顿的问题,如果网络中有p2p软件下载,可能将带宽和连接数占满。而路由器作为控制中心,如何限制p2p流量成为了痛点。限制流量的前提是识别,常用的识别策略有基于mac、基于ip、基于payload特征(也就是常说的7层识别),数据包识别简称DPI,基于流的识别简称DFI。当然这些对于P2P的识别都没有多大效果,因为P2P下载不是单条流,并且每条流的端口号也不断在变化,payload也没有特征。通过抓包统计,下载一个BT资源,连接数达到1000条以上。
之前一段时间分析P2P时都是去看目的端口、payload信息,没有发现任何特征。后面分析发现,在所有下载流中,到达本机的端口号是不变的,这应该也是P2P能实现多条流下载一个资源的前提吧。知道了这一规则,我们识别P2P流就简单了很多,直接识别本地端口即可,但是不同P2P软件所用的端口号不是固定的,如迅雷常用的是12345,腾讯视频用的是1864等,但这也可能变化。
抓包截图如下:
- 迅雷下载
- 腾讯视频
- P2P端口识别算法
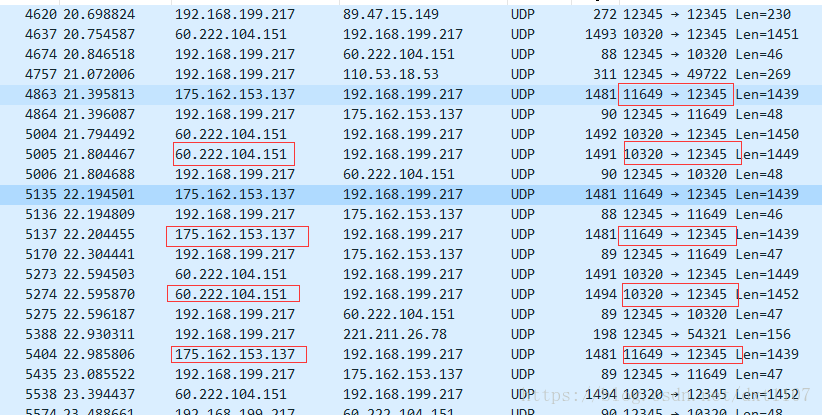
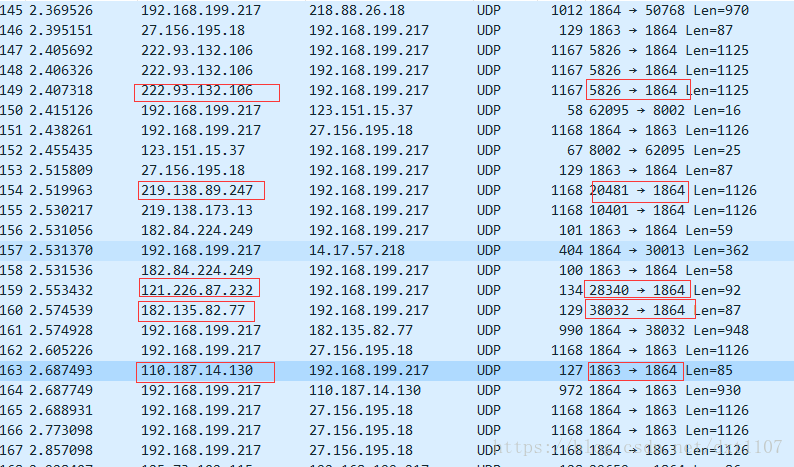
由于P2P多条流绑定同一个本地端口,可以设计一个自学习的算法,识别出哪些是P2P端口。在连接初始化时记录端口信息,如果同一个端口对应的连接超过设定的阈值,则认为是P2P端口,当下个数据包过来后直接基于端口识别即可。
识别算法流程图
详细设计思路
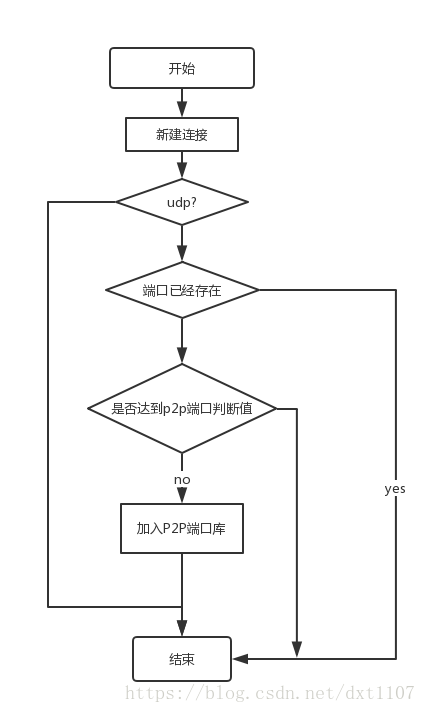
在linux系统中修改nf_conntrack_core.c,在新建连接跟踪的地方增加端口连接,在销毁连接的函数中删除端口连接,维持一张统计表。识别模块可以通过查询P2P端口表然后对P2P流识别,然后标记流信息。过滤模块、流控模块(QOS)根据标记进行过滤和流量限制处理。
更多技术开发文章,可以扫码关注wifi开发者公众号
