前言
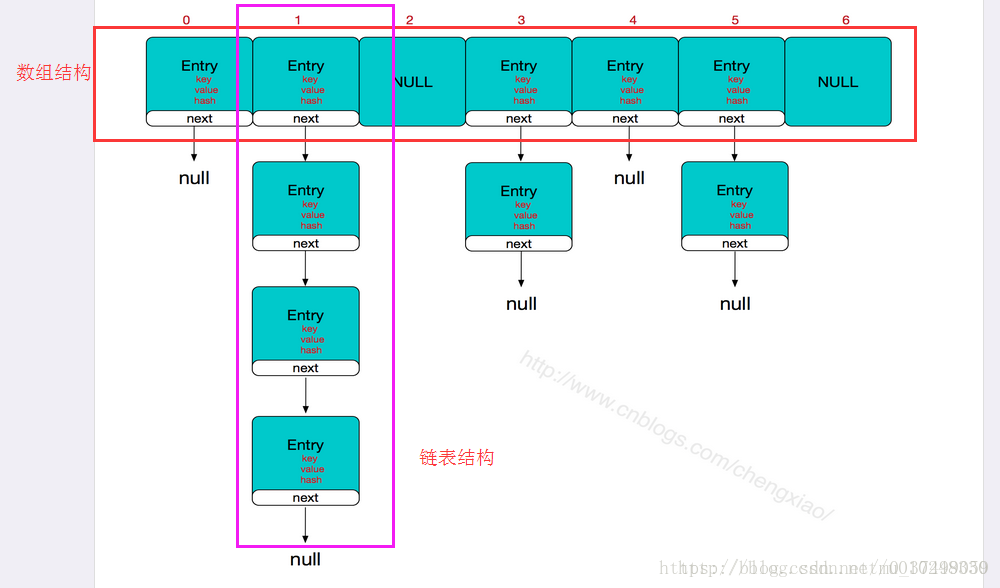
HashMap的底层实现主要是基于数组和链表来实现的,HashMap中通过key的hashCode来计算hash值的,由这个hash值计算在数组中的位置,将新插入的元素放到数组的这个位置,如果新插入的元素的hash值跟这个位置上已有元素的hash值相同,就会出现hash冲突,这时候,就在该位置通过链表来插入新的元素。
参考图:http://www.cnblogs.com/chengxiao/p/6059914.html
代码实现
- MyMap接口
- MyHashMap实现类
- MyHashMapTest测试类
1)MyMap接口
package com.cxx.map.HashMap;
/**
* @Author: cxx
* 自己实现 map接口
* @Date: 2018/6/8 11:18
*/
public interface MyMap<K,V> {
//大小
int size();
//是否为空
boolean isEmpty();
//根据key获取元素
Object get(Object key);
//添加元素
Object put(Object key,Object value);
interface Entry<k,v>{
k getkey();
v getValue();
}
}2)MyHashMap实现类
package com.cxx.map.HashMap;
import java.util.Map;
import java.util.Set;
/**
* @Author: cxx
* 自己实现HashMap
* 底层结构:数组+链表
* @Date: 2018/6/8 11:30
*/
public class MyHashMap<K,V> implements MyMap {
//默认容量16
private final int DEFALUT_CAPACITY=16;
//内部存储结构
Node[] table = new Node[DEFALUT_CAPACITY];
//长度
private int size=0;
//keySet
Set<K> keySet;
@Override
public int size() {
return this.size;
}
@Override
public boolean isEmpty() {
return size==0;
}
@Override
public Object get(Object key) {
int hashValue = hash(key);
int i=indexFor(hashValue,table.length);
for (Node node=table[i];node!=null;node=node.next){
if (node.key.equals(key)&&hashValue==node.hash){
return node.value;
}
}
return null;
}
@Override
public Object put(Object key, Object value) {
//通过key,求hash值
int hashValue=hash(key);
//通过hash,找到这个key应该放的位置
int i=indexFor(hashValue,table.length);
//i位置已经有数据了,往链表添加元素
for (Node node=table[i];node!=null;node=node.next){
Object k;
//且数组中有这个key,覆盖其value
if (node.hash==hashValue&&((k=node.key)==key||key.equals(k))){
Object oldValue=node.value;
node.value=value;
//返回oldValue
return oldValue;
}
}
//如果i位置没有数据,或i位置有数据,但key是新的key,新增节点
addEntry(key,value,hashValue,i);
return null;
}
public void addEntry(Object key,Object value,int hashValue,int i){
//如果超过了原数组大小,则扩大数组
if (++size==table.length){
Node[] newTable=new Node[table.length*2];
System.arraycopy(table,0,newTable,0,table.length);
table=newTable;
}
//的到i位置的数据
Node eNode=table[i];
//新增节点,将该节点的next指向前一个节点
table[i]=new Node(hashValue,key,value,eNode);
}
//获取插入的位置
public int indexFor(int hashValue,int length){
return hashValue%length;
}
//获取hash值
public int hash(Object key){
return key.hashCode();
}
//静态内部类:Node节点实现Entry接口
static class Node implements MyMap.Entry{
int hash;//hash值
Object key;//key
Object value;//value
Node next;//指向下个节点(单例表)
Node(int hash,Object key,Object value,Node next){
this.hash=hash;
this.key=key;
this.value=value;
this.next=next;
}
@Override
public Object getkey() {
return this.key;
}
@Override
public Object getValue() {
return this.value;
}
}
}
3)MyHashMapTest测试类
package com.cxx.map.HashMap;
import java.util.HashMap;
import java.util.Map;
/**
* @Author: cxx
* @Date: 2018/6/8 11:41
*/
public class TestMap {
public static void main(String[] args) {
MyMap map = new MyHashMap();
map.put("a1",1);
map.put("a2",2);
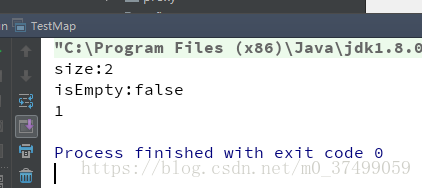
System.out.println("size:"+map.size());
System.out.println("isEmpty:"+map.isEmpty());
System.out.println(map.get("a1"));
}
}
总结
简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。