本文全面探讨了知识图谱中的知识融合技术,包括基础理论、核心问题、以及基于规则、机器学习和深度学习的融合方法。通过详细的技术分析和代码示例,为专业研究人员提供了深入的技术见解和实践指南。
关注TechLead_KrisChang,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人
一、引言
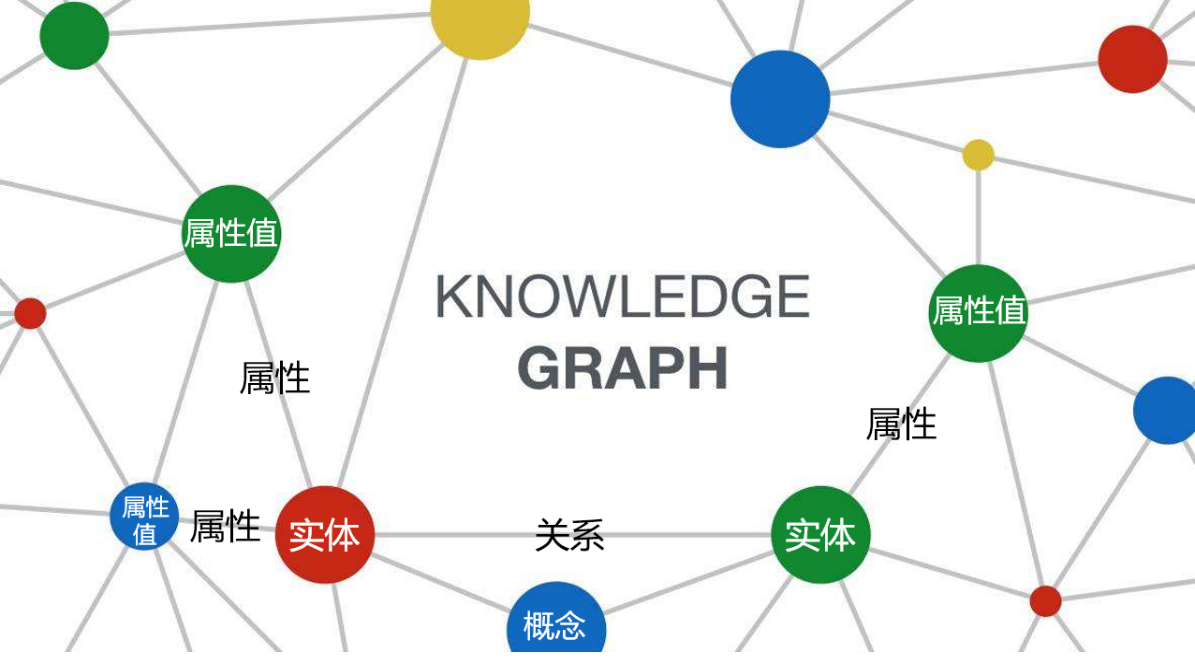
在人工智能和大数据时代,知识图谱作为连接广泛领域知识的桥梁,已经成为信息组织和智能检索的关键技术。知识图谱通过将现实世界中的实体及其相互关系以图形的形式进行结构化表示,不仅为机器提供了理解世界的方式,也极大地丰富了人机交互的可能性。随着知识图谱应用的不断深入,其在搜索引擎、推荐系统、语义搜索、智能问答等领域发挥着越来越重要的作用。
然而,构建一个高质量的知识图谱并非易事。知识来源的多样性和知识本身的复杂性给知识图谱的构建和扩展带来了巨大的挑战。特别是,从不同来源获得的知识往往存在冗余、矛盾甚至错误,如何有效地进行知识融合,以提高知识图谱的准确性和可靠性,成为了研究和实践中的一个重要课题。
知识融合技术,旨在解决知识图谱构建过程中的这一核心问题,它包括实体识别、实体链接、重复实体合并、关系融合等多个步骤。通过对不同来源的知识进行有效的整合和融合,知识融合技术不仅能够提升知识图谱的质量,还能够丰富知识图谱的内容,提高其应用价值。
二、知识图谱基础
2.1 知识表示
知识表示是知识图谱构建的基础,它决定了知识如何在图谱中被组织和表达。在知识图谱中,最常见的知识表示方法是使用三元组(Entity, Relation, Entity)形式,即将世界中的实体和实体之间的关系表达为一个个三元组,形成一个巨大的网络。除此之外,属性图也是一种常见的表示方法,它允许在实体和关系上附加属性信息,以更丰富地描述知识。
三元组
- 定义:三元组由两个实体(Entity)和一个连接这两个实体的关系(Relation)组成。
- 示例:(阿尔伯特·爱因斯坦, 出生于, 德国)。
属性图
- 定义:属性图在三元组的基础上增加了属性的概念,每个实体和关系都可以拥有属性。
- 示例:实体“阿尔伯特·爱因斯坦”可以拥有属性“出生日期:1879年3月14日”,关系“出生于”可以拥有属性“时间:1879年”。
2.2 知识抽取
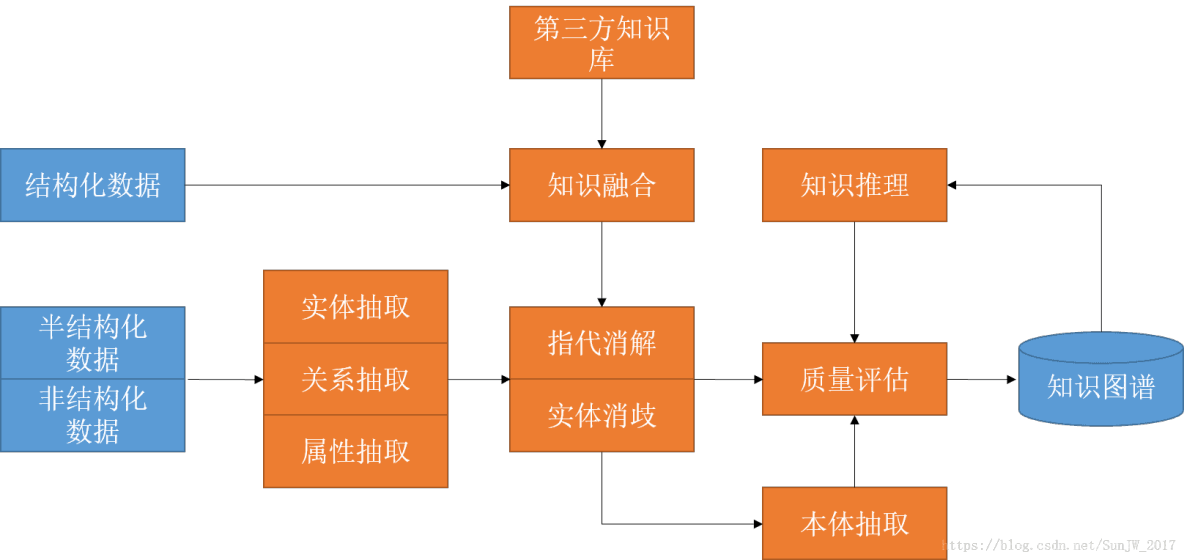
知识抽取是从各种数据源中提取知识并构建知识图谱的过程。这些数据源可以是文本(如书籍、新闻报道和科学文章)、数据库或互联网。知识抽取主要包括实体抽取、关系抽取和属性抽取三个步骤。

实体抽取
- 目的:识别文本中的具体实体,如人名、地点、组织等。
- 技术:通常使用命名实体识别(NER)技术来实现。
关系抽取
- 目的:确定实体间的关系,如“工作于”、“出生于”等。
- 技术:可以采用模式匹配、机器学习或深度学习方法来识别和分类实体间的关系。
属性抽取
- 目的:从文本中提取实体的属性信息,如人物的出生日期、公司的成立年份等。
- 技术:通常依赖于深度自然语言处理技术,通过分析句子结构来抽取属性信息。
知识抽取不仅是知识图谱构建的起点,也是确保知识图谱质量的关键步骤。随着人工智能技术的发展,知识抽取的方法和效率正在不断提高,为知识图谱的扩展和应用打下了坚实的基础。
三、知识融合的核心问题
知识融合是知识图谱构建中的一个核心环节,它涉及将来自不同来源的知识整合到一起,解决知识冲突和重复,提高知识的一致性和完整性。知识融合面临的核心问题主要包括实体识别与链接、重复实体合并和关系融合。
3.1 实体识别与链接
实体识别与链接是知识融合的第一步,目的是识别出不同数据源中的相同实体,并将它们链接起来。
实体识别
- 目的:从文本或数据源中识别出实体。
- 挑战:不同来源的数据可能使用不同的命名习惯或别名来指代同一个实体。
实体链接
- 目的:确定不同数据源中识别出的实体是否为同一实体。
- 技术:使用实体解析技术,比较实体的属性、上下文信息等,以判断是否指向相同的实体。
- 示例:将新闻报道中的“特朗普”和社交媒体上的“Donald Trump”识别并链接为同一实体。
3.2 重复实体合并
在知识图谱中,来自不同数据源的信息可能会导致重复实体的生成,重复实体合并旨在识别并合并这些实体。
方法
- 规则基础:基于预定义规则,如相同的名称和属性值来合并实体。
- 机器学习:利用训练数据学习实体合并的模式,自动识别并合并重复实体。
示例
- 场景:如果两个实体“IBM公司”和“International Business Machines Corporation”拥有相同的地址和成立年份,则可以合并为同一个实体。
3.3 关系融合
关系融合涉及识别并合并描述相同实体间关系的知识。
挑战
- 数据源多样性:不同数据源可能以不同方式描述同一关系。
- 关系歧义:相同的词语在不同上下文中可能表示不同的关系。
方法
- 上下文分析:分析关系出现的上下文,判断是否指向相同的实体关系。
- 关系映射:将不同数据源中的关系映射到统一的关系上。
示例
- 场景:如果一个数据源中有“比尔·盖茨是微软的创始人”,另一个数据源中有“比尔·盖茨创立了微软”,则这两个关系可以融合为“创始人”关系。
知识融合的核心问题处理的好坏直接影响到知识图谱的质量和应用效果。随着技术的进步,越来越多高效的算法和工具被开发出来,帮助解决知识融合中遇到的问题,提升知识图谱的构建效率和质量。
四、知识融合技术深度解析

4.1 基于规则的方法
基于规则的知识融合方法依赖于预定义的规则来识别和合并知识库中的实体和关系。这些规则通常由领域专家制定,以确保知识的一致性和准确性。规则的设计需要考虑实体的属性、关系的特性以及知识的上下文信息。
规则设计原则
- 明确性:每条规则应该明确无误地描述其适用的条件和执行的动作。
- 一致性:规则之间应保持逻辑上的一致性,避免相互冲突。
- 覆盖性:规则集应尽可能覆盖所有已知的知识融合场景。
规则应用示例
假设我们要融合两个知识库中关于“企业”实体的信息,可以定义如下规则:
- 如果两个实体的名称相似度超过90%,且它们的创立时间相差不超过一年,则认为这两个实体是同一实体。
- 如果两个实体属于同一行业,但地理位置不同,则保留为两个独立的实体,并在它们之间建立“合作伙伴”关系。
规则实施的挑战
- 规则的维护和更新随着知识库的增长和变化可能变得复杂和耗时。
- 规则可能无法覆盖所有的边缘情况,导致融合结果的不准确。
4.2 基于机器学习的方法
随着机器学习技术的发展,基于机器学习的方法在知识融合中展现了强大的能力,特别是在处理大规模知识库和复杂融合任务时。
实体匹配的机器学习方法
实体匹配是知识融合中的一个核心任务,目的是识别不同知识库中指代同一实体的记录。机器学习方法通过训练分类模型来自动识别是否两个实体是相同的。
示例:使用随机森林进行实体匹配
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import numpy as np
# 假设features为实体对的特征矩阵,labels为实体对是否匹配的标签
features = np.array([[0.9, 1, 0.1], [0.4, 0, 0.6], [0.95, 1, 0.2]]) # 示例特征
labels = np.array([1, 0, 1]) # 1 表示匹配,0 表示不匹配
# 训练随机森林模型
classifier = RandomForestClassifier(n_estimators=100)
classifier.fit(features, labels)
# 预测新实体对是否匹配
new_pairs = np.array([[0.85, 1, 0.2], [0.3, 0, 0.7]])
predictions = classifier.predict(new_pairs)
print("预测的匹配结果:", predictions)
关系融合的机器学习方法
关系融合旨在识别和合并来自不同知识库的相同或相似的关系。机器学习方法可以通过学习关系的表示和上下文,自动地进行关系识别和融合。
示例:使用支持向量机进行关系融合
from sklearn.svm import SVC
# 假设relation_features为关系的特征矩阵,relation_labels为关系的类别标签
relation_features = np.array([[0.8, 0.1], [0.5, 0.4], [0.9, 0.1]]) # 示例特征
relation_labels = np.array([1, 0, 1]) # 1 表示相同关系,0 表示不同关系
# 训练支持向量机模型
svm_classifier = SVC(kernel='linear')
svm_classifier.fit(relation_features, relation_labels)
# 预测新关系对是否为相同关系
new_relations = np.array([[0.85, 0.2], [0.4, 0.5]])
relation_predictions = svm_classifier.predict(new_relations)
print("预测的关系融合结果:", relation_predictions)
4.3 基于深度学习的实体匹配
深度学习在实体匹配任务中的应用主要依赖于其强大的特征提取能力。通过自动从原始数据中学习到的深层特征,深度学习模型能够有效地识别不同来源的知识库中相同实体的不同表示。
使用Siamese网络进行实体匹配
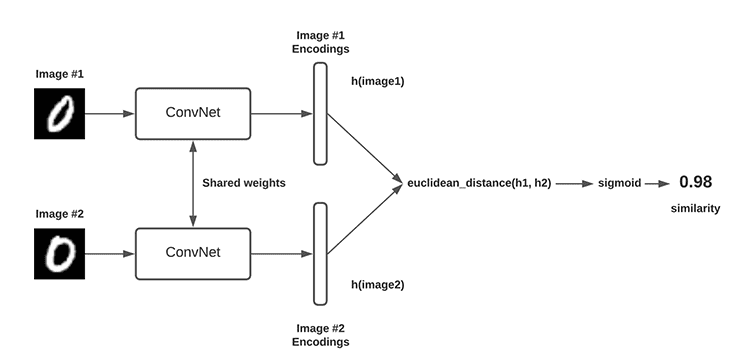
Siamese网络是一种特殊类型的神经网络,适用于度量学习。它通过训练过程中比较成对输入的相似度,来学习输入数据的有效表示。在实体匹配任务中,Siamese网络可以用来学习实体的表示,以判断两个实体是否匹配。
import torch
import torch.nn as nn
import torch.optim as optim
class SiameseNetwork(nn.Module):
def __init__(self):
super(SiameseNetwork, self).__init__()
self.fc = nn.Sequential(
nn.Linear(10, 20), # 假设实体特征的维度为10
nn.ReLU(inplace=True),
nn.Linear(20, 10),
nn.ReLU(inplace=True)
)
def forward(self, input1, input2):
output1 = self.fc(input1)
output2 = self.fc(input2)
return output1, output2
def contrastive_loss(output1, output2, label, margin=2.0):
euclidean_distance = nn.functional.pairwise_distance(output1, output2)
loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2) +
(label) * torch.pow(torch.clamp(margin - euclidean_distance, min=0.0), 2))
return loss_contrastive
# 示例数据
input1 = torch.randn(10) # 随机生成的实体特征向量
input2 = torch.randn(10) # 另一个实体的特征向量
label = torch.tensor([1], dtype=torch.float) # 假设这两个实体是匹配的
# 模型训练
model = SiameseNetwork()
optimizer = optim.Adam(model.parameters(), lr=0.001)
output1, output2 = model(input1, input2)
loss = contrastive_loss(output1, output2, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("Siamese网络的损失:", loss.item())
4.4 关系融合的深度学习方法
在关系融合方面,深度学习技术可以帮助模型学习到关系的复杂表示,从而有效地区分和融合不同知识库中的关系。
使用图神经网络进行关系融合
图神经网络(GNN)是处理图结构数据的强大工具,特别适用于知识图谱中的关系融合任务。通过在图结构上运行,GNN能够捕捉到实体和关系间复杂的依赖关系。
import torch
from torch_geometric.nn import GCNConv
class RelationFusionGNN(nn.Module):
def __init__(self, num_node_features, num_classes):
super(RelationFusionGNN, self).__init__()
self.conv1 = GCNConv(num_node_features, 16)
self.conv2 = GCNConv(16, num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = torch.relu(x)
x = self.conv2(x, edge_index)
return torch.log_softmax(x, dim=1)
# 假设data是图数据,包含节点特征和边的索引
# 训练过程省略,直接进行预测
model = RelationFusionGNN(num_node_features=3, num_classes=2) # 假设每个节点有3个特征,分类问题为2类
# data需要根据实际情况准备,这里不展示数据准备的代码
# prediction = model(data)
# print("预测结果:", prediction)
以上代码提供了使用深度学习进行知识融合的基本框架。在实际应用中,模型的结构、训练过程和参数调优都需要根据具体的任务和数据进行细致的设计和调整。深度学习方法在知识融合领域提供了强大的工具和可能性,但也带来了模型解释性、训练成本和数据需求方面的挑战。通过不断的研究和实践,我们可以期待在知识融合技术上取得更多的进步和突破。
五、知识融合效果评估
知识融合效果的评估是确保构建的知识图谱质量和应用价值的关键步骤。评估不仅涉及融合后知识图谱的准确性和完整性,还包括融合过程的效率和可扩展性。本部分将介绍用于评估知识融合效果的主要方法和指标。
5.1 准确性评估
准确性是评估知识融合效果的首要指标,它直接反映了融合后知识的正确性。
实体识别和链接准确性
- 指标:精确率(Precision)、召回率(Recall)和F1分数(F1-Score)。
- 定义:精确率是正确识别的实体链接数除以所有识别的实体链接数,召回率是正确识别的实体链接数除以应该识别的实体链接总数,F1分数是精确率和召回率的调和平均值。
- 计算方式:
- 精确率 = TP / (TP + FP)
- 召回率 = TP / (TP + FN)
- F1分数 = 2 * (精确率 * 召回率) / (精确率 + 召回率)
- 其中,TP(True Positives)是正确的正样本数,FP(False Positives)是错误的正样本数,FN(False Negatives)是错误的负样本数。
关系和属性融合准确性
- 采用与实体识别和链接相同的指标进行评估。
5.2 完整性评估
完整性指标评估了融合后知识图谱覆盖的知识范围和深度。
覆盖率(Coverage)
- 定义:融合后知识图谱中包含的实体和关系数量占原始数据源中相应实体和关系数量的比例。
- 重要性:高覆盖率意味着融合过程能够最大限度地保留原始知识,提高知识图谱的应用价值。
5.3 一致性评估
一致性评估关注融合后知识图谱中知识的逻辑一致性和无矛盾性。
逻辑一致性检验
- 方法:采用推理算法检查知识图谱中是否存在逻辑冲突,如同一实体的属性值矛盾等。
- 工具:使用OWL推理器(如Pellet、HermiT)进行自动化检验。
5.4 效率和可扩展性评估
效率和可扩展性是评估知识融合技术应用于大规模知识图谱构建的重要指标。
处理时间和资源消耗
- 指标:融合过程所需的时间和计算资源消耗。
- 评估:通过实验测量在不同规模的数据集上运行融合算法所需的时间和资源,评估算法的效率和可扩展性。
可扩展性测试
- 方法:在数据量逐渐增加的情况下,观察融合算法的性能变化,以评估其在处理大规模数据集时的可扩展性。
知识融合效果的综合评估,需要考虑上述多个方面的指标。通过这些评估方法,可以全面了解融合技术的性能和适用范围,为进一步优化知识融合过程提供科学依据。
关注TechLead_KrisChang,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人