这是对自己的鼓励,自己的努力能看见。这是对自己热爱的行业的见证。自己的Markdown文件改的,没有认真排版,代码超链接老出错,请包涵。用的是《深入Linux内核架构》一书的总结,觉得不错可以去购买它。
0x01:简介和概述
==============================0.概述
1. 多任务、调度和进程管理
2. 物理内存的管理以及内核与相关硬件的交互
3. 用户空间的进程访问虚拟内存
4. 编写设备驱动程序
5. 模块机制以及虚拟文件系统
6. Ext文件系统属性和访问控制表的实现方式
7. 内核中网络的实现
8. 系统调用的实现方式
9. 内核对时间相关功能的处理
10. 页面回收和页交换的相关机制以及审计的实现===============================
> 参考:
>The Magic Garden Explained --- Benny Goodheart&James Cox
> Modern Operating Systems --- Andrew S. Tanenbaun
>The Magic Garden Explained --- Benny Goodheart&James Cox
> Modern Operating Systems --- Andrew S. Tanenbaun
1.1 内核的任务
> 内核是硬件与软件之间的一个中间层。
> 作用:将应用程序的请求传递给硬件,对系统中的各种设备和组件进行寻址
> 作用:将应用程序的请求传递给硬件,对系统中的各种设备和组件进行寻址
1.2 实现策略
- 宏(单)内核
- 微内核
- 微内核
1.3 内核的组成部分
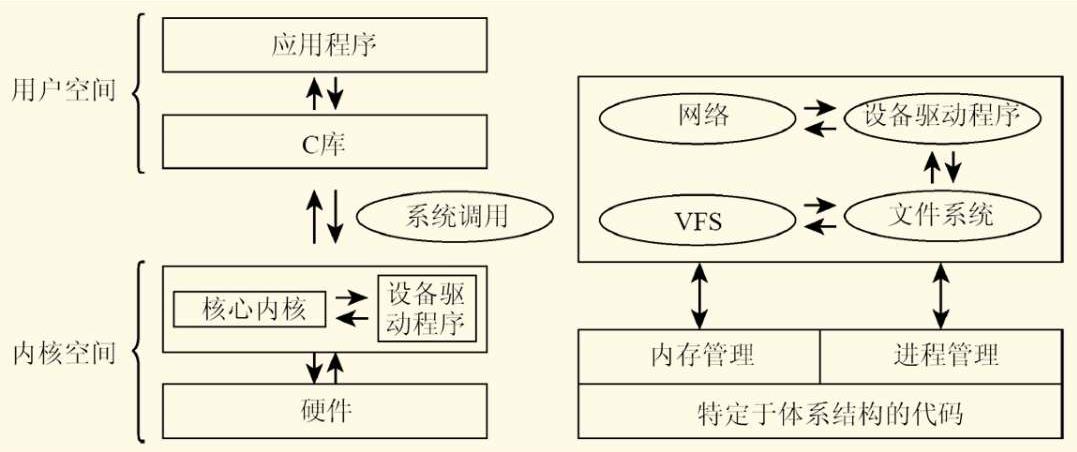
1.3.1 进程、进程切换、调度
系统中同时真正在运行的进程数目多不超过CPU数目,因此内核会按照短的时间间隔在不同的进程之间切换.
(1) 内核借助于CPU的帮助,负责进程切换的技术细节。
必须给各个进程造成一种错觉,即CPU总是可用的。通过在撤销进程的CPU资源之前保存进程所有与状态相关的要素,并将进程置于空闲状态,即可达到这一目的。在重新激活进程时,则将保存的状态原样恢复。进程之间的切换称之为进程 切换。
(2) 内核还必须确定如何在现存进程之间共享CPU时间。
重要进程得到的CPU时间多一点,次要进程得到的少一点。确定哪个进程运行多长时间的过程称为调度。
1.3.2 UNIX进程
内核启动init程序作为第一个进程,该进程负责进一步的系统初始化操作。
UNIX操作系统中有两种创建新进程的机制,分别是fork和exec。
(1) fork可以创建当前进程的一个副本,父进程和子进程只有PID(进程ID)不同。
在该系统调用执行之后,系统中有两个进程,都执行同样的操作。父进程内存的内容将被复制,至少从程序的角度来看是这样。Linux使用了一种众所周知的技术来使fork操作更高效,该技术称为写时复制(copy on write),主要的原理是将内存复制操作延迟到父进程或子进程向某内存页面写入数据之前,在只读访问的情况下父进程和子进程可以共用同一内存页。
例如,使用fork的一种可能的情况是,用户打开另一个浏览器窗口。如果选中了对应的选项,浏 览器将执行fork,复制其代码,接下来子进程中将启动适当的操作建立新窗口。
(1) fork可以创建当前进程的一个副本,父进程和子进程只有PID(进程ID)不同。
在该系统调用执行之后,系统中有两个进程,都执行同样的操作。父进程内存的内容将被复制,至少从程序的角度来看是这样。Linux使用了一种众所周知的技术来使fork操作更高效,该技术称为写时复制(copy on write),主要的原理是将内存复制操作延迟到父进程或子进程向某内存页面写入数据之前,在只读访问的情况下父进程和子进程可以共用同一内存页。
例如,使用fork的一种可能的情况是,用户打开另一个浏览器窗口。如果选中了对应的选项,浏 览器将执行fork,复制其代码,接下来子进程中将启动适当的操作建立新窗口。
(2) exec将一个新程序加载到当前进程的内存中并执行。旧程序的内存页将刷出,其内容将替换 为新的数据。然后开始执行新程序。
1. 线程
>>Linux用clone方法创建线程。
2. 命名空间
>>对命名空间的支持被集成到了许多子系统中。这使得不同的进程可以看到不同的系统视图。传统的Linux(与一般的UNIX操作系统)使用许多全局量,例如进程ID。系统中地址空间控制流的每个进程都有一个唯一标识符(ID),用户(或其他进程)可使用ID来访问进程,例如向进程发一 个信号。启用命名空间之后,以前的全局资源现在具有不同分组。每个命名空间可以包含一个特定的PID集合,或可以提供文件系统的不同视图,在某个命名空间中挂载的卷不会传播到其他命名空间中。
>>Linux用clone方法创建线程。
2. 命名空间
>>对命名空间的支持被集成到了许多子系统中。这使得不同的进程可以看到不同的系统视图。传统的Linux(与一般的UNIX操作系统)使用许多全局量,例如进程ID。系统中地址空间控制流的每个进程都有一个唯一标识符(ID),用户(或其他进程)可使用ID来访问进程,例如向进程发一 个信号。启用命名空间之后,以前的全局资源现在具有不同分组。每个命名空间可以包含一个特定的PID集合,或可以提供文件系统的不同视图,在某个命名空间中挂载的卷不会传播到其他命名空间中。
1.3.3 地址空间与特权级别
1. 特权级别
>英特尔处理器区分4种特权级别:Ring 0,1,2,3
>Linux只使用两种不同的状态:核心态和用户状态
2. 虚拟和物理地址空间
>页表来为物理地址分配虚拟地址。
>虚拟地址关系到进程的用户空间和内核空间, 而物理地址则用来寻址实际可用的内存。
物理内存页经常称作页帧。相比之下,页则专指虚拟地址空间中的页。
>英特尔处理器区分4种特权级别:Ring 0,1,2,3
>Linux只使用两种不同的状态:核心态和用户状态
2. 虚拟和物理地址空间
>页表来为物理地址分配虚拟地址。
>虚拟地址关系到进程的用户空间和内核空间, 而物理地址则用来寻址实际可用的内存。
物理内存页经常称作页帧。相比之下,页则专指虚拟地址空间中的页。
后请注意,称呼用户运行的应用程序时,有两个等价的名词可用。其中之一是用户层(userland), BSD社区更喜欢使用该术语来称呼所有不属于内核的东西。另一种说法是称某个应用程序在用户空间 运行。应该注意到,用户层这个名词总是指应用程序本身,而用户空间则不仅可以表示应用程序,还 指代了应用程序所运行的虚拟地址空间的一部分,与内核空间相对。
1.3.4 页表
用来将虚拟地址空间映射到物理地址空间的数据结构称为页表。实现两个地址空间的关联容易的方法是使用数组,对虚拟地址空间中的每一页,都分配一个数组项。该数组项指向与之关联的页帧。
||
> 虚拟地址的第一部分称为全局页目录(Page Global Directory,PGD)。PGD用于索引进程中的一 个数组(每个进程有且仅有一个),该数组是所谓的全局页目录或PGD。PGD的数组项指向另一些数 组的起始地址,这些数组称为中间页目录(Page Middle Directory,PMD)。
||> 虚拟地址中的第二个部分称为PMD,在通过PGD中的数组项找到对应的PMD之后,则使用PMD 来索引PMD。PMD的数组项也是指针,指向下一级数组,称为页表或页目录。
||> 虚拟地址的第三个部分称为PTE(Page Table Entry,页表数组),用作页表的索引。虚拟内存页和 页帧之间的映射就此完成,因为页表的数组项是指向页帧的。
||> 虚拟地址后的一部分称为偏移量。它指定了页内部的一个字节位置。归根结底,每个地址都指 向地址空间中唯一定义的某个字节。
||> 页表的一个特色在于,对虚拟地址空间中不需要的区域,不必创建中间页目录或页表。与前述使 用单个数组的方法相比,多级页表节省了大量内存。
该方法也有一个缺点。每次访问内存时,必须逐级访问多个数组才能将虚拟地址转换为物 理地址。CPU试图用下面两种方法加速该过程。
>(1) CPU中有一个专门的部分称为MMU(Memory Management Unit,内存管理单元),该单元优 化了内存访问操作。
>(2) 地址转换中出现频繁的那些地址,保存到称为地址转换后备缓冲器(Translation LookasideBuffer,TLB)的CPU高速缓存中。
无需访问内存中的页表即可从高速缓存直接获得地址数据,因而 大大加速了地址转换。
无需访问内存中的页表即可从高速缓存直接获得地址数据,因而 大大加速了地址转换。
1.3.5 物理内存的分配
1. 伙伴系统
2. slab缓存
3. 页面交换和页面回收
2. slab缓存
3. 页面交换和页面回收
1.3.6 计时
名为jiffies_64和jiffies(分别是64位和32位)的全局变量
1.3.7 系统调用
系统调用是用户进程与内核交互的经典方法。POSIX标准定义了许多系统调用,以及这些系统调用在所有遵从POSIX的系统包括Linux上的语义。传统的系统调用按不同类别分组,如下所示。
进程管理:创建新进程,查询信息,调试。
信号:发送信号,定时器以及相关处理机制。
文件:创建、打开和关闭文件,从文件读取和向文件写入,查询信息和状态。
目录和文件系统:创建、删除和重命名目录,查询信息,链接,变更目录。
保护机制:读取和变更UID/GID,命名空间的处理。
定时器函数:定时器函数和统计信息。
## 1.3.8 设备驱动程序、块设备和字符设备
## 1.3.9 网络
## 1.3.10 文件系统
## 1.3.11 模块和热插拔
## 1.3.12 缓存
## 1.3.12 缓存
1.3.13 链表处理
>内核提供的标准链表可用于将任何类型的数据结构彼此链接起来。很明确,它不是类型安全的。
加入链表的数据结构必须包含一个类型为list_head的成员,其中包含了正向和反向指针。如果有若干链表涉及同一数据结构,
这也是比较常见的情形,那么结构中就需要同样数目的list_head成员。
加入链表的数据结构必须包含一个类型为list_head的成员,其中包含了正向和反向指针。如果有若干链表涉及同一数据结构,
这也是比较常见的情形,那么结构中就需要同样数目的list_head成员。
-list_entry是查找链表元素必须使用。
初看起来,其调用语法相当复杂:list_entry(ptr,type,member)。ptr是指向数据结构中list_head成员实例的一个指针,type是该数据结构的类型,而member则是数据结构中表示链表元素的成员名。如果在链表中查找task_struct的实例,则需要下列示例调用:struct task_struct = list_entry(ptr, struct task_struct, run_list)。因为链表的实现不是类型安全的,所以需要显式 指定类型。如果数据结构包含在多个链表中,则必须指定所要查找的链表元素,才能找到正确的链表元素。
-list_add(new, head)用于现存的head元素之后,紧接着插入new元素。
-list_add_tail(new, head)用于在head元素之前,紧接着插入new元素。
如果指定head为表头,由于链表是循环的,那 么new元素就插入到链表的末尾(该函数因此而得名)。
-list_for_each(pos, head)用于遍历链表的所有元素。pos表示链表中的当前位置,而head 指定了表头。
-list_del(entry)从链表中删除一项。
-list_empty(head)检测链表是否为空,也就是链表是否没有包含元素。
-list_splice ( list, head)负责合并两个链表,把list插入到另一个现存链表的head元素之后。
## 1.3.14 对象管理和引用计数
1. 一般性的内核对象 kobject->kref
2. 对象集合 kobject->kset
3. 引用计数
1. 一般性的内核对象 kobject->kref
2. 对象集合 kobject->kset
3. 引用计数

!
[
提问码
]
(https://img-blog.csdn.net/20180508210935705?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTEyODg0ODM=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)