
近年来,向量搜索大赛 BigANN 一直是行业关注的焦点。原因在于,BigANN 不仅是在向量搜索领域具有强大影响力的比赛,开发者在赛后贡献出的相关解决方案更是行业进步与发展的重要动力。
向量检索大赛 BigANN 旨在提升大规模 ANN 的研究创新和生产环境中的落地应用。BigANN 分设四条赛道,问题来自实际应用场景。作为 BigANN 曾经的赛道冠军得主、最新一届参与赛题设计的组织方,Zilliz 始终走在向量搜索场景探索的前列。
尤其是最新一届大赛,Zilliz 虽然未参赛,但团队工程师们在赛后对 BigANN 的 4 大赛题都提出了自己的解法。在所有赛道上,Zilliz 给出的解决方案均超过拿到最好结果的参赛队伍,获得了最多 2.5 倍的性能提升,同时也超越了所有其他厂商的方案。本文将带大家一起回顾 BigANN 大赛及详解 Zilliz 提出的算法问题解决方案。
01.
为什么要在赛后给出解决方案?
ANN benchmark(https://ann-benchmarks.com/)是业界最为权威和知名的向量搜索算法 benchmark。不过,开始由于数据集太小且场景过少,其对解决实际生产问题的指导意义较弱。BigANN 在 2021 年带来了更大的数据集和更复杂的场景,对于整个向量检索行业而言都意义非凡。2023 年,BigANN 更是带来了 4 个更加贴合当下向量搜索研究和发展趋势的场景。
2023 年,Zilliz 则作为大赛的组织方,参与了此次赛题的设计。比赛结束后,Zilliz 的算法工程师团队对于题目中设置的向量搜索难题产生了浓厚的兴趣,在此前获奖工程师方案的基础上不断优化和提升,最终形成了一套 SOTA(state of the art) 方案。
不止如此,Zilliz 认为 BigANN 此次的赛道设置非常具有生产指导价值,无论是支持 Filters、Sparse 这样多元化的搜索方式,解决 OOD 这个场景提出的“如何提高搜索质量”的问题,还是优化 Streaming 的生产常见场景,都是团队现阶段积极探索的方向。因此,尝试解决这些算法问题同样可以反哺于 Zilliz 的产品,帮助其在向量搜索领域走得更远。
02.
传说中的 BigANN 2023 赛题
BigANN 2023 赛题是什么样的?不妨一起感受一下:
1. Filters 赛道: 本赛道使用了 YFCC 100M 数据集,要求参赛者处理从该数据集中选取的 1000 万张图片。具体任务要求为提取每张图片的特征并使用 CLIP 生成 Embedding 向量,且需包含图像描述、相机型号、拍摄年份和国家等元素的标签(元素均来自于词汇表)。本赛道的主要挑战是参赛者需要成功地将 10 万个查询与数据集中的相应图像和标签匹配,每个查询都包含一个图像向量和特定的标签。
2. Out-Of-Distribution(OOD) 赛道: 本赛道使用了 Yandex Text-to-Image 10M 数据集,强调跨模态数据的整合。基础数据集包括来自 Yandex 视觉搜索数据库的 1000 万张图像 Embedding 向量,这些向量由 Se-ResNext-101 模型生成的,但查询向量是基于文本搜索和不同的模型生成的。参赛者需要有效地弥合这些不同模态数据之间的差异。
3. Sparse 赛道: 本赛道以 MSMARCO passage retrieval 数据集为核心,处理大量的文章(超过 880 万个),所有文章都通过 SPLADE 模型编码成稀疏向量。这些虽然维度高,但本质上是稀疏向量。查询数量近 7000个,且查询也通过相同的模型处理,但长度较短、非零元素较少。本赛道的主要挑战是选手需准确检索给定查询的 Top 结果,重点是查询向量和数据库向量之间的最大内积。
4. Streaming 赛道: 本赛道基于 MS Turing 数据集中的一部分,包含 1000 万个数据。参与者的任务是遵循提供的“操作手册”(该手册详细说明了一系列数据插入、删除和搜索操作),并在 1 小时内完成操作。此外,选手们还有 8GB DRAM 的限制。赛道的重点是优化处理这些操作的过程,并保持数据集的索引流畅。
在 BigANN 大赛中,每条赛道都针对算法排名设置了具体的评分标准:
对于 Filters、 OOD 以及 Sparse 赛道,大赛根据 QPS 对算法进行排名,且算法需要至少 90% recall@10 • 对于 Streaming 赛道,大赛根据 recall@10 对算法进行排名,且算法 runbook 需要在 1 小时以内完成。
所有比赛都基于 Azure D8lds_v5 (8 vCPUs and 16 GiB 内存) 的资源来评估,Zilliz 提出的方案也是如此。目前,Zilliz 还未将所有解决方案开源,但是已将可执行的 binary 放在 BigANN's repo(https://github.com/harsha-simhadri/big-ann-benchmarks/pulls?q=Zilliz+Solution+author%3Ahhy3)中,方便大家获取和复现性能测试结果。
03.
Zilliz 的解决方案及成果
Filters 赛道
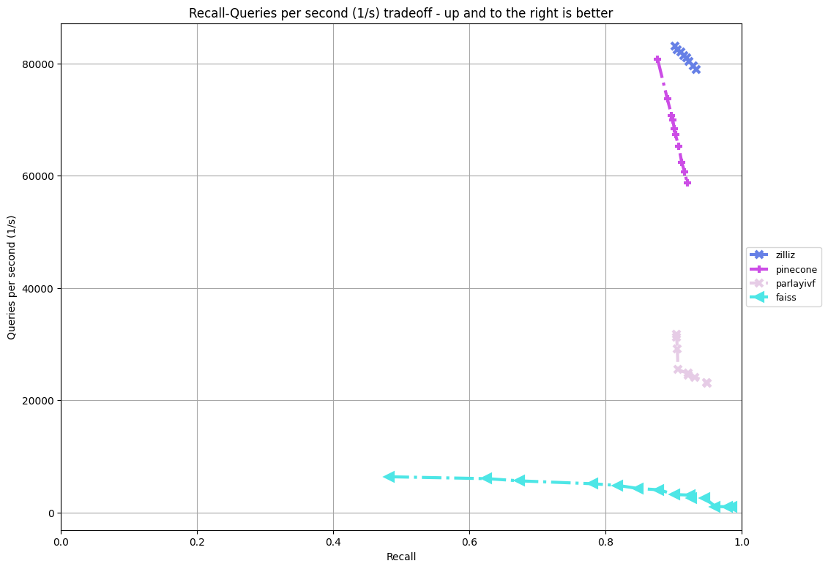
在private数据集上当 90% recall的情况下我们的解决方案达到了 ~82k qps,是baseline faiss (~3.2k) 的 25 倍,是赛道胜者 parlayivf (~32k) 的 2.5 倍,高于 pinecone 的解决方案 (~68k)
Zilliz 解决方案是基于图算法和 tag 分类。
Build 时,会对每种可能出现的 tag 组合进行 cardinality 分析;对于较包含向量较多的组合建图,其他的组合建立倒排索引;搜索时则根据不同的组合选取对应的搜索方式。
同时,团队对 query 按所属的 tag 进行分类,搜索时分别对每个 tag 所对应的 query 依次进行搜索。这样做的好处有两个,一是可以最大化 cache 利用率,二是在爆搜时可以使用矩阵乘法计算进行加速。当然,为了加速计算,我们使用了对数据进行量化,并利用 SIMD 优化相关的距离计算。
OOD 赛道

由于 ood track 没有 private 数据集,因此我们在 public 数据集下进行比较。在90%recall下我们的解决方案达到了 ~33k qps,是 baseline diskann (~4k qps) 的 8 倍,超过了赛道胜者 pyanns (~23k qps) 和 pinecone 的解决方案 (~26k qps)。
Zilliz 的解决方案基于图算法以及高度优化的搜索过程。
在计算方面,用不同精度的量化进行搜索和 refine,并使用 SIMD 进行计算加速。
搜索开始前,先对 query 向量进行聚类。在图搜时,对分属不同的聚类的 query 分配不同的初始点,并且对每个聚类进行依次搜索。通过聚类可以体现两大优势,一是对不同聚类依次搜索优化了 cache 利用率,二是由于对不同聚类分配自适应的初始点一定程度上缓解了向量不同分布的问题。
值得关注的是,Zilliz 使用了多级的 bitset 数据结构。在图搜的过程中,一般需要一个数据结构来标记哪些点被访问过,传统的方法是使用一个 bitset 或者哈希表,bitset 的缺点是其中大部分的内存并不会被使用到,使得每次读取时会有大概率的 cache miss;哈希表的缺点是糟糕的常数导致性能低下。受内存中多级页表的启发,Zilliz 设计出了多级 bitset 的数据结构,将上层 bitset 缓存在 cpu cache 中,使得读写性能得到大幅提升。
Sparse 赛道
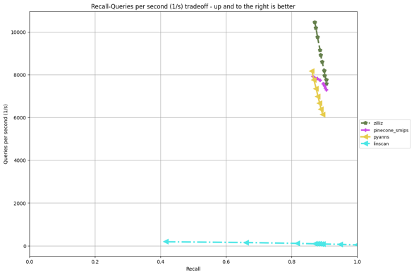
在 private 数据集上当90% recall 的情况下我们的解决方案达到了~8200 qps,是baseline linscan (~100 qps) 的 82 倍,超过了赛道胜者 pyanns (~6000 qps) 和 pinecone 的解决方案 (~7400 qps)。
Zilliz 的解决方案是基于图算法和一些基于稀疏向量的优化。
每个稀疏向量通过 (data[float32], index[int32]) 元组的列表进行表示,团队对 data 进行多精度量化,分别用户图搜时的计算和最后的 refine。同时 index 也可以用 int16 表示,以降低内存带宽使用。
本赛道的题目为最大内积搜索。内积计算有一个重要特性即绝对值较大的值有更大的重要性,而绝对值较小的值有较小的重要性。可以根据这一特性设计剪枝策略,即在图搜过程中将绝对值较小的值裁剪掉,并在图搜结束后使用完整向量进行 refine。根据实验结果,可以在不大幅降低 recall 的前提下将 query 向量中超过 80% 的数据裁剪掉。
此外,团队还用 SIMD 进行快速的有序列表求交集,进而实现高效的稀疏向量内积计算。
Streaming 赛道
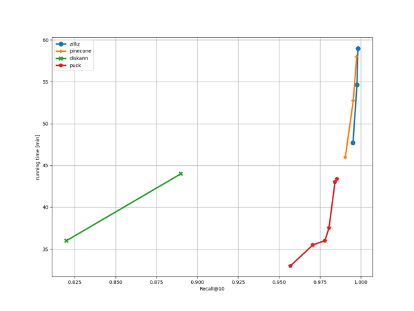 在 final_runbook 上我们的解决方案获得了 0.9982 的 recall,超过了赛道胜者 puck (0.986 recall) 以及 pinecone 的解决方案 (0.9975 recall)。
在 final_runbook 上我们的解决方案获得了 0.9982 的 recall,超过了赛道胜者 puck (0.986 recall) 以及 pinecone 的解决方案 (0.9975 recall)。
Zilliz 的解决方案是基于图算法以及 SQ 量化。
对于删除操作,Zilliz 采用了惰性删除策略,即对被删除的向量我们只是将它标记为已删除,并不改变图的结构。等到删除操作累积到一定数量时才进行真正的图结构改变。
搜索中,对向量进行不同精度的量化分别用以图搜和 refine。粗略分为三个步骤:第一步是使用低精度量化后的向量进行图搜。由于使用惰性删除策略,搜索得到的一些向量已经被删除了,因此在第二步使用后置过滤的策略将被删除的向量过滤掉。最后一步,用更高精度的量化向量进行 refine 得到最终结果。
04.
Make Something Different!
随着 AI 的快速发展,向量搜索也不再仅仅局限于传统意义上简单的 KNN 搜索,对于复杂的生产场景的支持变得越来越关键。因此,BigANN 2023 对于多场景的涵盖让它能更加具有现实意义。
Zilliz 一直致力于创造世界上最好用的向量数据库,利用向量搜索的力量解决实际问题。为此,Zilliz 也从未停止过对不同场景的探索,包括 BigANN 提出的场景及其他前沿场景。在这条道路上,我们需要有更多志同道合的朋友来 join efforts。无论你是对向量搜索、数据库还是对高性能优化感兴趣,无论是在哪个国家和地区,欢迎大家一起来 make something different!



本文分享自微信公众号 - ZILLIZ(Zilliztech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。