
01 背景介绍
数据治理的第一步,也是数据中台的一个基础功能 — 即将来自各类业务数据源的数据,同步集成至中台 ODS 层。业务数据源多种多样,单单可能涉及到的主流关系型数据库就有近十种。功能更加全面的数据中台通常还具有对接非关系型数据库、消息队列、日志源、文件源等功能。
数据湖通常是 OLAP 型的数据库,虽然中台系统很少会采用多种数据仓库技术,但在技术选型时,可选项也有很多。数据集成可实现多种异构数据库间的数据同步,想要提升数据中台的易用高效性,自动表模型同步则显得至关重要。
02 数据平台整体架构
整体来看数据平台共有 3 层:业务数据源、数据平台中的数据湖仓及数据应用。
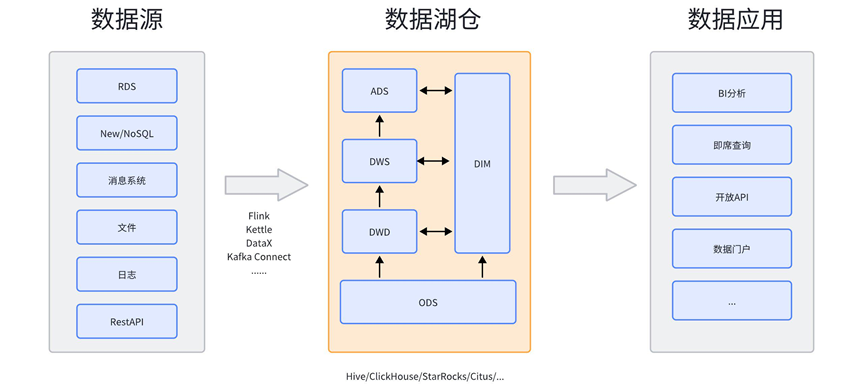
数据源可包含:
- 关系型或非关系型数据库;
- 某个消息系统如 MQTT、Kafka 或 RabbitMQ;
- 放置在文件服务器上的 CSV 、XML 或 JSON 文件;
- 非结构化日志或是类似通过 syslog 这样的协议提供的数据
- HTTP 接口,通常是 Restful API。
数据湖仓通过一系列数据处理,支撑数据应用。数据应用则包括数据 BI 分析工具、即席查询、开放 API、数据门户等功能板块。
其中,数据湖通常不是通过一步处理即可得到所需数据,所以数据湖也存在分层。比较常见的分层类别:ODS、DWD、DWS 和 ADS 层。有时也会将维度表的数据划分至 DIM 层,不同数据平台系统的分层会有所增减。
本期分享关注重点聚焦在 ODS 层。来自各数据源的数据会通过相应的数据集成技术,几乎不经过处理,直接存放至 ODS 层;数据平台对 ODS 层数据再经过多次处理即可得到数据应用所需数据。
- ODS: Operational Data Store,运营数据层,贴源层
- DWD: Data Warehouse Details,数据细节层
- DWS: Data Warehouse Service,数据服务层
- ADS: Application Data Service,应用数据层
- DIM: Dimension Data Layer,维度数据层
03 各类数据源集成方式
3.1 数据库数据源的数据集成方式
数据库数据源有两种集成方式:批量同步和实时同步。
批量同步:通过定时执行任务来集成数据。几乎所有的数据库都实现了 JDBC 接口,可借助数据库提供的 JDBC 驱动,通过全量或增量方式从这个数据库中获取数据再导入到数据仓库 ODS 层。
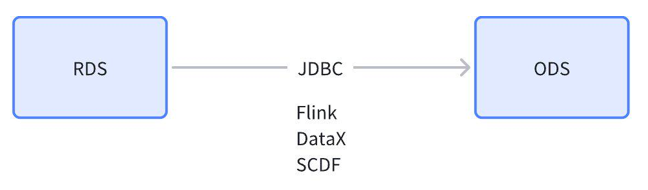
实时同步:批量同步有一个定时任务,执行完该同步任务即结束;而实时同步方式的同步任务是一直在执行,一旦数据库数据源的数据发生变化,它立刻即能获取到该数据变化情况并同步至 ODS 层。

3.2 非数据库数据源的数据集成方式
这里主要介绍文件源、API 数据源、消息源和日志源。
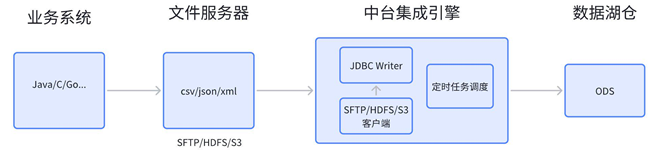
文件源:有些业务系统的数据库可能不会开放给数据平台直接连接,而是将数据定时导出为 CSV 文件或类似文件,存放到 SFTP 或者是 S3 等文件服务器。数据平台集成引擎可定时从文件服务器上获取文件,解析数据并导入到 ODS 层。
API 数据源:通常是一个 Restful 接口,调用该接口即能获取到结构化/半结构化数据,比如 JSON、XML 等格式。数据集成引擎作为 HTTP 的客户端,定时调用 API 接口获取数据,并转换成数据记录,通过 JDBC 方式写入到数据湖。

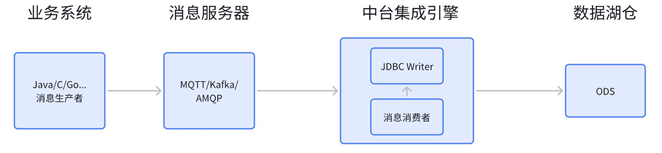
消息源:部分业务系统会选择将数据写到消息服务器中,比如 MQTT、AMQP、 Kafka 等。数据中台集成引擎作为消息的“消费者”,负责连接到消息服务器、监听消息队列或 Topic 中的消息,获取来自业务系统的消息并将其转换成数据记录,最后通过 JDBC 方式写入到数据湖。
日志源:部分业务系统看、可通过 syslog 协议方式将日志写入 syslog 服务端。数据引擎此时可以被视作服务器端,在一个端口监听客户端请求。业务系统端作为 syslog 的客户端,将日志写入到数据引擎监听的端口,数据平台集成引擎收到数据后可解析并转换成数据记录,再通过 JDBC 方式写入到数据湖。
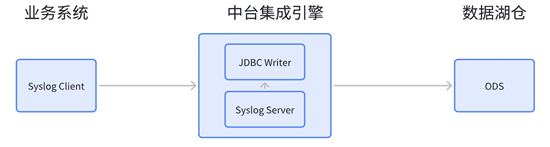
04 数据集成时模型的创建和同步
4.1 数据库数据源的模型映射
- 来自数据库的数据源,其数据模型可以直接映射;
- 字段名可以从源数据库获取;
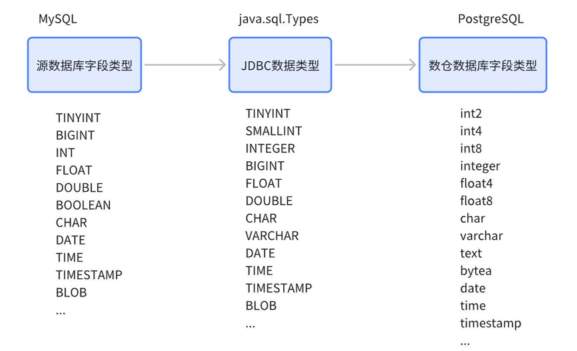
- 字段类型先通过 JDBC 驱动获取到 JDBC 的数据类型,再转换为数仓库的数据类型(这里以 PostgreSQL 为例);
- 从 JDBC 数据类型到数据库的数据类型映射是可以一对多的,可以由自定义逻辑决定;
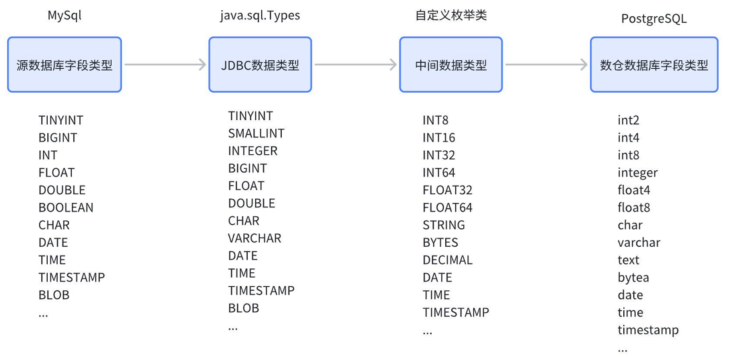
- 可将获取到的 JDBC 数据类型先转换为自定义的中间数据类型,然后映射为数仓数据库的数据类型。
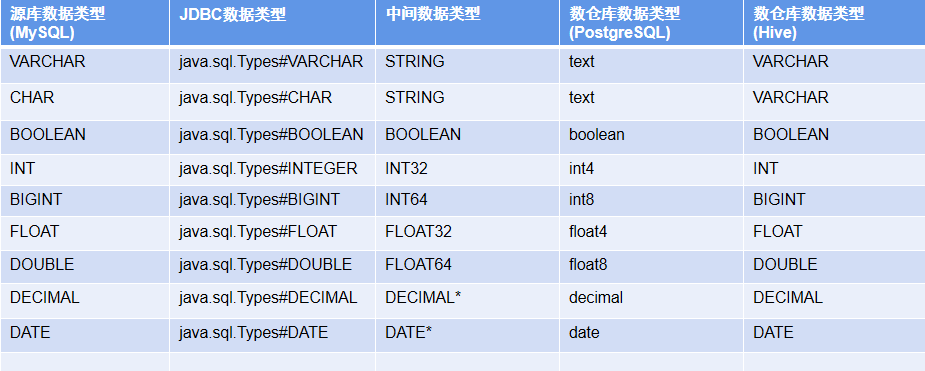
数据类型映射表:源库数据类型对应的 JDBC 数据类型由数据库对应的 JDBC 决定;JDBC 数据类型在 JDK 中的 java.sql.Types 类中定义;JDBC 数据类型对应的数仓库数据类型集成引擎决定。
4.2 非数据库数据源的模型映射
- 对于数据源本身不具备 schema 信息的,无法自动映射;
- 先手动定义模型元数据,再根据模型元数据在数据中创建表。
源数据类型可以是字符型、整形或日期型。数据仓库以 PostgreSQL 为例,字符串类型对应类型包括:text 、char、varchar 等。布尔类型在数仓中可以用 boolean 、varchar 或 bit 类型。整形可以是 int4、int8、int16。数据模型的确定取决于数据平台用户如何创建模型。
4.3 数据库数据源的数据模型的同步
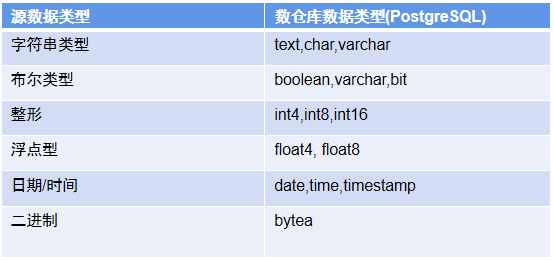
举例说明,数据源是 MySQL 数据库,其中有一个 nation 表,包括了四个字段,字段类型有:int、char、varchar。此处示例表中的一条数据。
情景1:那么该数据模型如何同步至数据中台呢?
在数据集成时,数据集成引擎读取源表的数据,并在生成的每一条同步数据里面均包含模型信息。左侧为源数据库中的数据,它在生成的同步数据时将输出如右侧的 JSON 数据。它本身含有模型信息,包括表名、所有字段及字段类型。
图中采用的是中间数据类型,比如源库中 nationkey 字段是 int 类型,对应的中间类型是 int32;name 字段在源库中是 char(25) 类型,对应中间数据类型是 string 外加一个表示长度的 size 参数。该条同步数据也包含数据本身信息,在 payload 字段中。
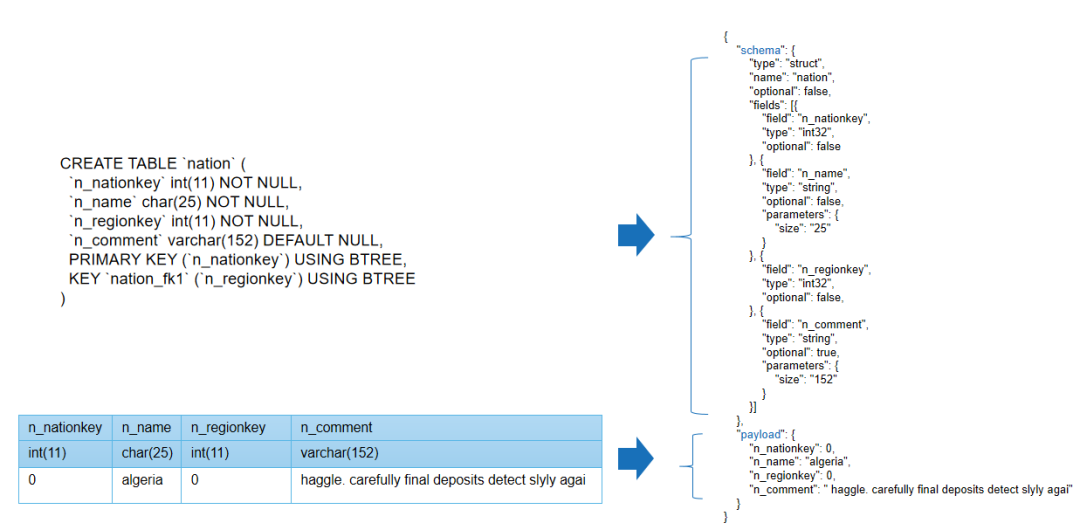
数据平台集成引擎可以从同步数据中提取到源表模型信息,用于在数据仓库中创建该表的模型信息。数据平台集成引擎可根据该模型生成一个在数据库创建表的 DDL 语句。注意这里表名需添加数据源的前缀标识,因为 ODS 层可能有来自不同数据源的数据,表名可能重复。因此,在 ODS 层中创建表的时需加前缀来避免重复,同时还添加了部分控制字段。
从数据中提取模型信息示例:
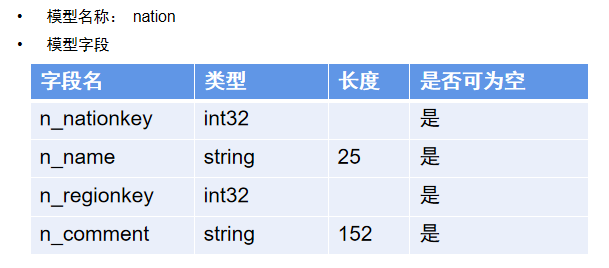
生成建表语句示例:

情景2:在后续数据源模型发生变化时如何处理呢?
可将数据中的模型信息与数据中台中的模型进行对比,如果模型增加了字段,会生成一个表变更语句。表字段类型变化,可根据用户设定的策略做表变更或者保持不变,取决于用户的同步策略。如果字段删除了通常是不会删除的。在获取到的数据写入 ODS 之前,先执行这个建表语句或是表变更语句。数据仓库 ODS 层的模型同步完成以后,再把需要同步的数据写入到数仓的表里面。
4.4 非结构化数据源的数据模型的同步
这里以 API 接口获取到的数据为例:
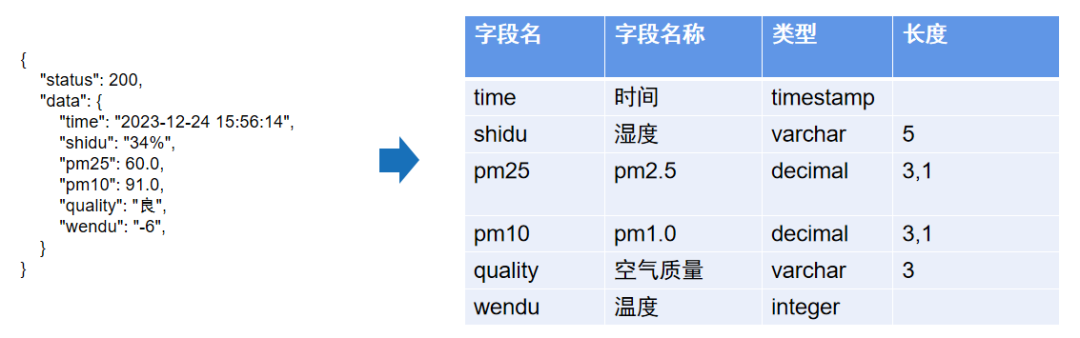
当获取到类似左边这样的数据,我们无法直接从数据获取到它的数据类型信息。此时只能由数据平台的使用者手动来创建模型。有了模型后就可根据该模型来生成一条 DDL 语句,然后根据 DDL 语句在数据中台中创建该表。
4.5 数据模型创建的时机
以 KDP(数据服务平台) 所使用的 Kafka Connect JDBC 框架为例:使用 JDBC-reader 插件读取源数据库;数据记录转换为消息写入 Kafka 的 Topic 中;使用 JDBC-Writer 插件读取 Topic 中的消息,写入数仓数据库。
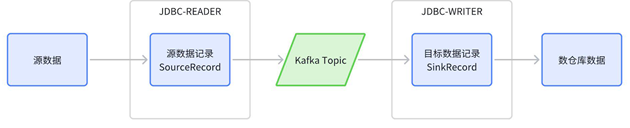
在 Writer 端解析数据模型,进行数仓中表的创建和变更:Writer 端获取到一条数据后,从数据中解析出模型信息;将模型和数仓库中的表结构比对;如果不存在,则创建;如果不一致则修改。
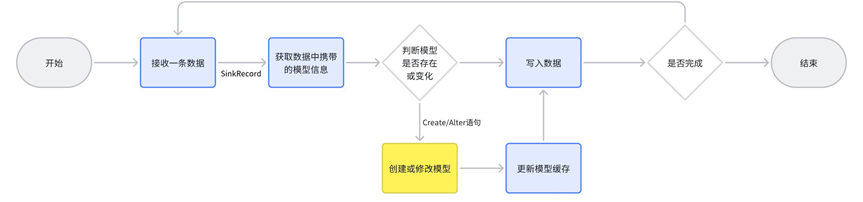
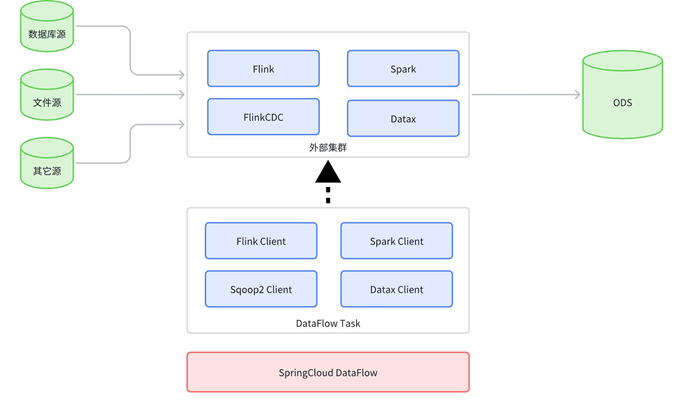
4.6 KDP 中的数据集成架构
KDP 使用 Kafka Connect 框架实现了数据库源、API 源、文件源、日志源的数据集成:使用各种 Kafka Connect 组件对接各种数据源,将获取的数据转换为统一 SourceRecord;ODS 层使用的是基于 Citus 插件的分布式 PostgreSQL,所以 sink 端可以使用 Kafka Connect JDBC 从 Kafka Topic 消费数据,写入 ODS 层;整个集成任务流由 SpringCloud DataFlow 调度执行。
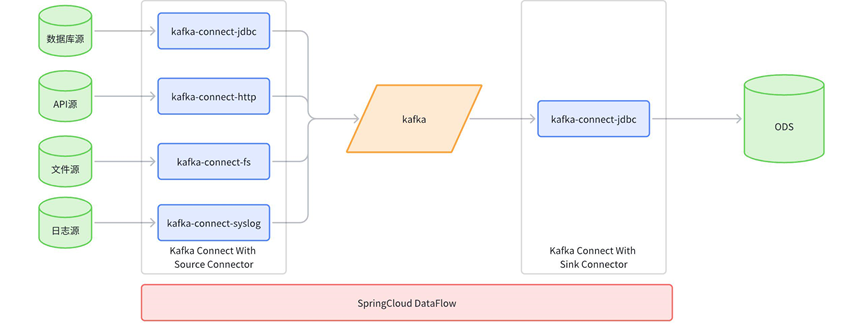
KDP 使用 Debezium Connector 实现基于 CDC 的数据库源实时同步Debezium 提供的连接器对接各支持 CDC 的数据库;Debezium 本身是基于 Kafka Connect,将 CDC 事件转换为 SourceRecord 写入 Kafka Topic;Sink 端同样使用 Kafka Connect JDBC 消费数据,写入 ODS 层。
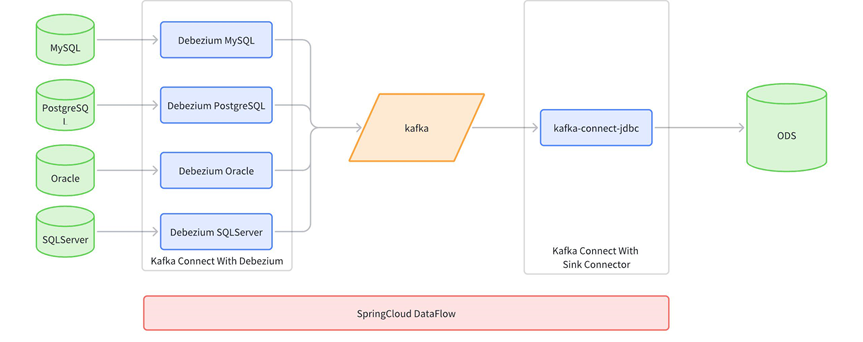
KDP 支持调用大数据组件如 Flink、Spark、Sqoop2 等,使用外部计算资源实现海量数据的同步:基于 SpringCloud Dataflow 框架;各 Task 作为大数据组件客户端提交任务到外部集群;外部集群执行数据集成任务。
05 数据集成时常见问题及方案
1、业务库中表模型增加、删除字段、字段类型长度变更时,数据仓库中表模型的变更如何处理 答:数据记录中携带表模型信息,检测到表模型不一致时,生成并执行表变更语句。
2、数仓数据库中存在多种类似的字段类型时如何选择? 答:由数据中台的集成引擎的逻辑来决定选择字段类型的策略。
3、Restful API 数据源等无法自动确定源数据模型的场景如何处理? 答:手动定义数据模型信息,一键生成并执行表创建/变更语句。
4、数据仓库中各层之间模型如何同步? 答:除了 ODS 层外,其它层的模型都是由中台用户定义。需要手动修改模型信息,可一键生成并执行表/创建变更语句。
Rust 编写的 Zed 编辑器正式开源 原魅族副总嘲讽华为花上万亿建设鸿蒙生态 Oracle 的 2024 年 Java 工作规划 逆天神机 —— 17 寸的 64 核 AMD EPYC 工作站 ioGame17 文档或将强制收费,netty java 游戏服务器 网易云音乐第三方开源 API 因侵权被要求删除 ChatGPT 官方中文页面上线 FreeBSD 也要“锈化”?团队称考虑在基础系统采用 Rust AI 工具正在导致代码质量的下降 贾扬清最新开源项目 —— 500 行代码构建的 AI 搜索工具