SyncNavigator 做数据同步时所支持的数据库类型:
支持sqlserver 2000-2014所有版本,全兼容,和MYsql 4.x 、MYsql 5.x 、MYsql 6.x版本。
来源数据库和目标数据库可以版本不同,比如:来源数据库是sqlserver 2012 目标数据库是mysql 5.5 ,都是可以的, SyncNavigator 支持跨数据库版本,无缝传输数据。
只需要能连接上数据库, SyncNavigator 可以安装在第三方电脑上,来源数据库和目标数据库电脑上可以不用安装程序。
需要同步的两种数据
把需要同步的数据,根据数据写入后是否会发生变化,分为不会发生变化的数据(一般是日志数据)和会变化的数据(人员表,比如说人员的状态会发生变化)。
示例说明
针对以上两种数据场景,需要设计不同的同步策略。这里以把业务RDS数据库的数据同步到MaxCompute为例做一些说明,其他的数据源的道理是一样。
根据等幂性原则(一个任务多次运行的结果一样,则该任务支持重跑调度,因此该任务若出现错误,清理脏数据会比较容易),每次导入数据都是导入到一张单独的表/分区里,或者覆盖里面的历史记录。
本文定义任务测试时间是2016-11-14,全量同步是在14号做的,同步历史数据到ds=20161113这个分区里。至于本文涉及的增量同步的场景,配置了自动调度,把增量数据在15号凌晨同步到ds=20161114的分区里。数据里有一个时间字段optime,用来表示这条数据的修改时间,从而判断这条数据是否是增量数据。
不变的数据进行增量同步
这个场景,由于数据生成后就不会发生变化,因此可以很方便地根据数据的生成规律进行分区,较常见的是根据日期进行分区,比如每天一个分区。
数据准备
drop table if exists oplog;create table if not exists oplog(optime DATETIME,uname varchar(50),action varchar(50),status varchar(10));Insert into oplog values(str_to_date('2016-11-11','%Y-%m-%d'),'LiLei','SELECT','SUCCESS');Insert into oplog values(str_to_date('2016-11-12','%Y-%m-%d'),'HanMM','DESC','SUCCESS');
这里有2条数据,当成历史数据。需先做一次全量数据同步,将历史数据同步到昨天的分区。
操作步骤
步骤一:创建MaxCompute表
--创建好MaxCompute表,按天进行分区create table if not exists ods_oplog(optime datetime,uname string,action string,status string) partitioned by (ds string);
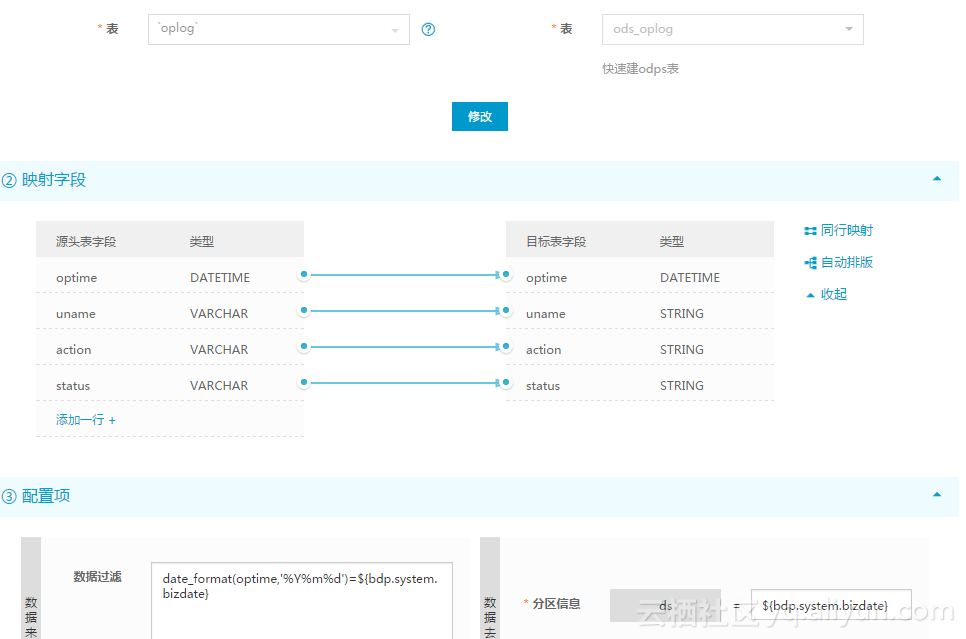
步骤二:配置同步历史数据的任务:
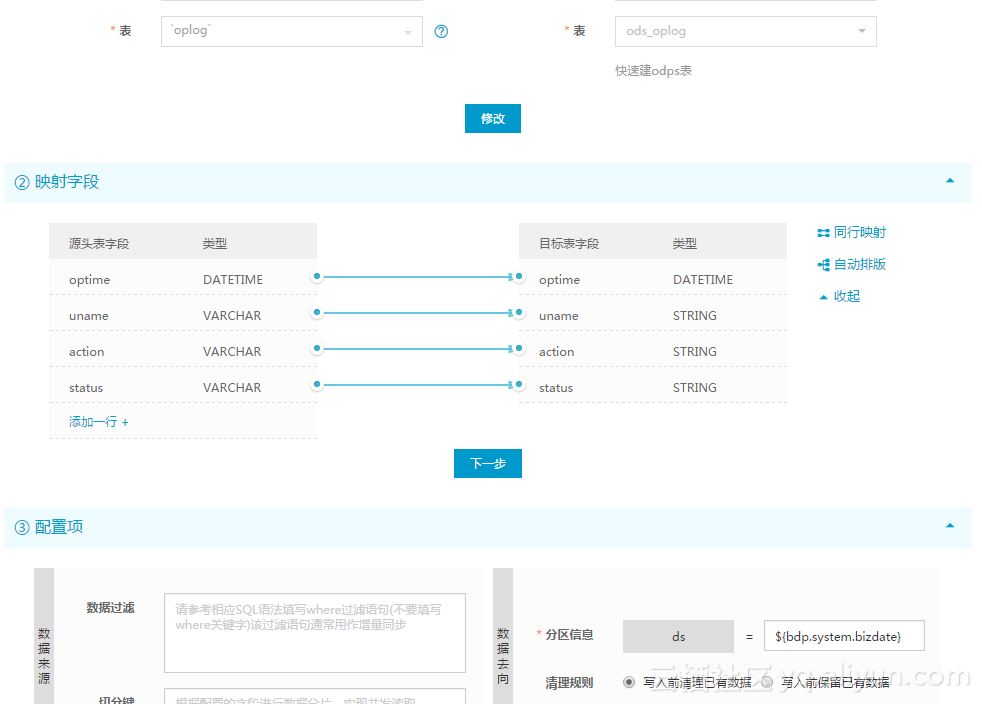
因为只需要执行一次,所以只需操作一次测试即可。测试成功后,到”数据开发”模块把任务的状态改成暂停(最右边的调度配置里)并重新提交/发布,避免任务自动调度执行。
查看MaxCompute表的结果:
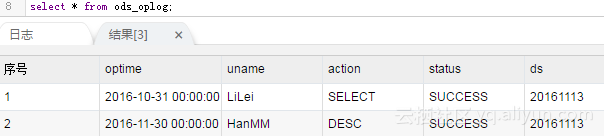
步骤三:往RDS源头表里多写一些数据作为增量数据:
insert into oplog values(CURRENT_DATE,'Jim','Update','SUCCESS');insert into oplog values(CURRENT_DATE,'Kate','Delete','Failed');insert into oplog values(CURRENT_DATE,'Lily','Drop','Failed');
步骤四:配置同步增量数据的任务。注意,通过配置“数据过滤”,在15号凌晨进行同步的时候,把14号源头表全天新增的数据查询出来,并同步到目标表增量分区里。