opentelemetry
简介
OpenTelemetry,简称OTel,是一个与供应商无关的开源可观测性框架,用于检测、生成、收集和导出
遥测数据,如轨迹、度量、日志。OTel的目标是提供一套标准化的供应商无关SDK、API和工具,用于接
收、转换数据并将数据发送到可观测系统(监控系统)后端(开源或商业)
OpenTelemetry 是以解决观测性为初衷的项目,观测性包含链路,监控,日志。主要解决的问题是观测性领域模型的统一,观测性数据收集的统一,观测性数据输出的统一。这些统一性主要体现在 API 规范,SDK 实现规范,接口规范等。OpenTelemetry 不会负责观测数据的存储,需要存储这些观测数据的 backend。OpenTelemetry 定义来数据输出的规范,由各大厂商自行完成数据的持久化。
OpenTelemetry 也提供了很多开发语言的 SDK,开发者需要使用自己熟悉的语言的 SDK 完成应用程序的观测性能力。目前不同的开发语言的支持程度不一样。
主要组成:
Specification:这个组件是语言无关的,主要是定义了规范,如 API 的规范,SDK 的开发规范,数据规范。使用不同开发源于开发具体 SDK 的时候会按照标准开发,保证了规范性。
Proto:这个组件是语言无关的,主要是定义了 OpenTelemetry 的 OTLP 协议定义,OTLP 协议是 OpenTelemetry 中数据传输的重要部分。如 SDK 到Collector,Collector 到 Collector,Collector 到 Backend这些过程的数据传输都是遵循了 OTLP 协议。
Instrumentation Libraries:是根据 SDK 的开发规范开发的支持不同语言的 SDK,如 java,golang,c 等语言的 SDK。客户在构建观测性的时候,可以直接使用社区提供的已经开发好的 SDK 来构建观测能力。社区也在此基础上提供了一些工具,这些工具已经集成了常见软件的对接。
Collector:负责收集观测数据,处理观测数据,导出观测数据。
架构
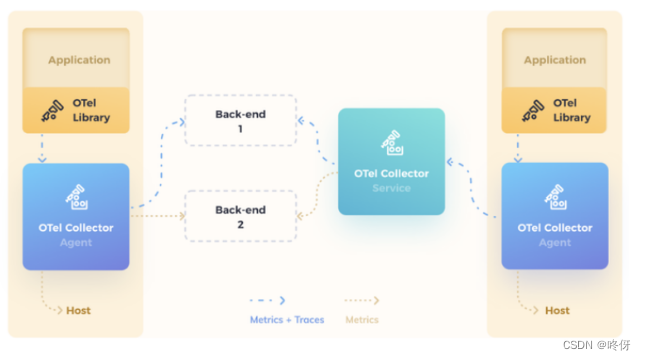
Application: 一般的应用程序,同时使用了 OpenTelemetry 的 Library (实现了 API 的 SDK)。
OTel Libraty:也称为 SDK,负责在客户端程序里采集观测数据,包括 metrics,traces,logs,对观测数据进行处理,之后观测数据按照 exporter 的不同方式,通过 OTLP 方式发送到 Collector 或者直接发送到 Backend 中。
OTel Collector:负责根据 OpenTelemetry 的协议收集数据的组件,以及将观测数据导出到外部系统。这里的协议指的是 OTLP (OpenTelemetry Protocol)。不同的提供商要想能让观测数据持久化到自己的产品里,需要按照 OpenTelemetry 的标准 exporter 的协议接受数据和存储数据。同时社区已经提供了常见开源软件的输出能力,如 Prometheus,Jaeger,Kafka,zipkin 等。图中看到的不同的颜色的 Collector,Agent Collector 是单机的部署方式,每一个机器或者容器使用一个,避免大规模的 Application 直接连接 Service Collector;Service Collector 是可以多副本部署的,可以根据负载进行扩容。
Backend: 负责持久化观测数据,Collector 本身不会去负责持久化观测数据,需要外部系统提供,在 Collector 的 exporter 部分,需要将 OTLP 的数据格式转换成 Backend 能识别的数据格式。目前社区的已经集成的厂商非常多,除了上述的开源的,常见的厂商包括 AWS,阿里,Azure,Datadog,Dynatrace,Google,Splunk,VMWare 等都实现了 Collector 的 exporter 能力。
观测性方案
观测性常见方案主要总结:
日志方案:filebeats->elasticsearch->kibana;filebeats->kafka->logstash->elasticsearch->kibana; fluentd->elasticsearch->kibana;fluentd->kafka->fluentd->elasticsearch->kibana 。
监控方案:比较统一的都在使用 prometheus,prometheus-operator,thanos,grafana。
链路方案:主要方案有开源的 skywalking,jaeger,zipkin,还有商业的方案,如 dynatrace 等。
opentelemetry解决方案就是为了统一Trace, metrics, loggingd 标准
数据流
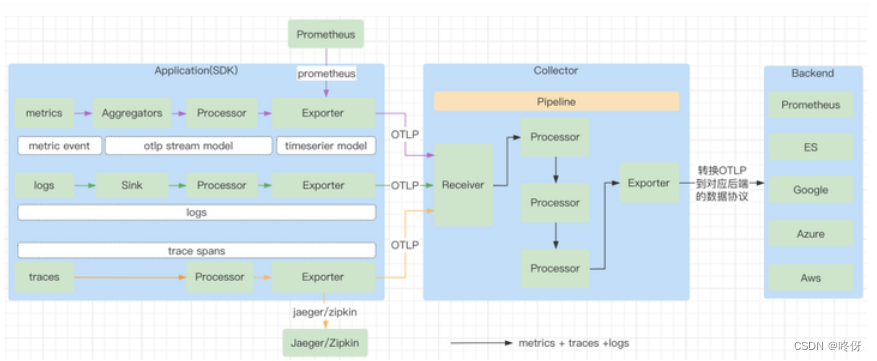
概念
Traces
TracerProvider
是Tracer的工厂。在大多数应用程序中,Tracer提供程序初始化一次,其生命周期与应用程序的生命周
期相匹配。Tracer Provider初始化还包括Resource和Exporter初始化。这通常是使用OpenTelemetry进
行跟踪的第一步
Tracer
Tracer(跟踪程序)用于创建span,其中包含有关给定操作(例如服务中的请求)所发生情况的更多信
息。跟踪程序是从跟踪程序提供程序创建的
Trace Exporters
跟踪导出器将跟踪发送给消费者。此使用者可以是调试和开发时的标准输出、OpenTelemetry收集器或
您选择的任何开源或供应商后端
Context Propagation (上下文传播)
- 上下文传播是实现分布式跟踪的核心概念。使用上下文传播,跨域可以相互关联并组装到跟踪中,而不
管跨域是在哪里生成的 - 上下文(Context)是一个对象,它包含发送和接收服务的信息,以便将一个跨度与另一个跨度相关联,
并将其与整个跟踪相关联 - 传播(Propagation)是在服务和流程之间移动上下文的机制。它序列化或反序列化上下文对象,并提供
要从一个服务传播的相关跟踪信息
spans(重要)
跨度表示一个工作或操作单元。跨度是痕迹的组成部分。在OpenTelemetry中,它们包括以下信息:
- Name(名称)
- Parent span ID (empty for root spans)(父跨度ID,为空则表示根跨度)
- Start and End Timestamps 开始与结束的时间戳
- Span Context (跨度上下文)
- Attributes(属性)
- Span Events (事件)
- Span Links (链接)
- Span Status(状态)
Span Context
span context 是每个跨度上的一个不可变对象,包含以下内容:
Trace ID表示跨度所属的跟踪
Span ID 跨度的跨度ID
Trace Flags,一种包含跟踪信息的二进制编码
Trace State,可以携带特定于供应商的跟踪信息的键值对列表
span context 是与分布式上下文和Baggage一起序列化和传播的跨度的一部分。
由于“span context”包含跟踪ID,因此在创建“span link”时会使用它
Attributes
属性是包含元数据的键值对,您可以使用这些元数据对跨度进行注释,以携带有关其正在跟踪的操作的
信息。
例如,如果跨度跟踪在电子商务系统中将商品添加到用户购物车的操作,则可以捕获用户的ID、要添加到购物车的商品的ID和购物车ID。
属性具有每个语言SDK实现的以下规则:
键必须是非空字符串值
值必须是非空字符串、布尔值、浮点值、整数或这些值的数组
此外,还有语义属性,这是常见操作中通常存在的元数据的已知命名约定。尽可能使用语义属性命名有
助于跨系统标准化常见类型的元数据。语义约定详见文档:https://github.com/opentelemetry/semantic-conventions
Span Events
跨度事件可以被认为是跨度上的结构化日志消息(或注释),通常用于表示跨度持续时间内的一个有意义的奇异时间点。
例如,考虑web浏览器中的两种情况:
- 跟踪页面加载
- 表示页面何时变为交互式
- 跨度最适合用于第一种情况,因为它是一个有开始和结束的操作。
- 跨度事件最好用于跟踪第二个场景,因为它代表了一个有意义的奇异时间点
Span Links
链接的存在使您可以将一个跨度与一个或多个跨度相关联,从而暗示因果关系。例如,假设我们有一个分布式系统,其中一些操作由跟踪跟踪。作为对其中一些操作的响应,额外的操作排队等待执行,但其执行是异步的。我们也可以通过跟踪来跟踪此后续操作。我们希望将后续操作的跟踪与第一个跟踪相关联,但我们无法预测后续操作何时开始。我们需要将这两个轨迹关联起来,所以我们将使用跨度链接。
您可以将第一个跟踪中的最后一个跨度链接到第二个跟踪的第一个跨度。现在,它们是因果关联的。
链接是可选的,但也是将跟踪跨度相互关联的好方法
Span Status
span的状态可选值:Unset,Ok,Error。当应用程序代码中存在已知错误(例如异常)时,可将状态可以设置为“Error”
Spand Kind(span 类型)
创建跨度时,它是客户端(Client)、服务器(Server)、内部(Internal)、生产者(Producer)或消费者(Consumer)之一。这种span类型为跟踪后端提供了一个关于应该如何组装跟踪的提示。根据OpenTelemetry规范,服务器跨度的父跨度通常是远程客户端跨度,而客户端跨度的子跨度通常是服务器跨度。类似地,消费者跨度的父代始终是生产者,生产者跨度的子代始终是消费者。如果未提供,则假定跨度类型为内部
- SERVER:表示跨度涵盖同步RPC或其他远程请求的服务器端处理。此跨度通常是预期等待响应的远程CLIENT跨度的子跨度。
- CLIENT:表示跨度描述对某个远程服务的请求。此跨度通常是远程SERVER跨度的父跨度,在收到响应之前不会结束。
- PRODUCER:表示跨度描述异步请求的发起方。此父跨度通常会在相应的子“消费者”跨度之前结束,甚至可能在子跨度开始之前结束。在使用批处理的消息传递场景中,跟踪单个消息需要为每个要创建的消息创建一个新的生产者跨度。
- CONSUMER:表示跨度描述异步生产者请求的子级
- INTERNAL:默认值。指示跨度表示应用程序中的内部操作,而不是具有远程父级或子级的操作。
metrics
度量是在运行时捕获的关于服务的度量。从逻辑上讲,捕获其中一个测量的时刻被称为度量事件,它不仅包括测量本身,还包括捕获它的时间和相关的元数据。
应用程序和请求度量是可用性和性能的重要指标。自定义指标可以深入了解可用性指标如何影响用户体验或业务。收集的数据可用于警告停机或触发调度决策,以在高需求时自动扩大部署规模
Meter Provider
是 Meters的工厂。在大多数应用程序中,Meter Provider初始化一次,其生命周期与应用程序的生命周期相匹配。Meter Provider初始化还包括资源和导出程序初始化。这通常是使用OpenTelemetry进行测量的第一步
Meter
Meter创建度量仪表,在运行时捕获有关服务的测量值。meter 是从Meter Provider 创建的
Metrics Exporter
Metric Exporter 向消费者发送度量数据。此使用者可以是调试和开发时的标准输出、OpenTelemetry收集器或您选择的任何开源或供应商后端
Metrics Instruments
在OpenTelemetry中,测量由公制仪器捕获。这种公制仪器由名称、种类、可选单位和可选说明定义。这种工具的名称、单元和描述由开发人员选择,或通过常见的语义约定(如请求或过程度量)进行定义。语义约定详见文档:https://github.com/open-telemetry/semantic-conventions
仪器类型为以下六种之一:(类似promethues里的指标)
Counter
一个随着时间积累的值——你可以把它想象成汽车上的里程表;它只会上升
Asynchronous Counter
与Counter相同,但每次导出都会收集一次。如果您不能访问连续增量,而只能访问聚合值,则可以使用
UpDownCounter
一种随着时间的推移而积累的值,但也可能再次下降。例如,队列长度会随着队列中工作项的数量而增加或减少
Asynchronous UpDownCounter
与UpDownCounter相同,但每次导出都会收集一次。如果您不需要访问连续更改,而只能访问聚合值(例如,当前队列大小),则可以使用
(Asynchronous)Gauge
测量读取时的当前值。一个例子是车辆中的燃油表。仪表总是异步的
Histogram
直方图是客户端值的集合,例如请求延迟。如果你有很多值,并且不是对每个单独的值都感兴趣,而是对这些值的统计数据感兴趣,那么直方图可能是一个不错的选择
Aggregation
除了度量工具之外,聚合的概念也是一个需要理解的重要概念。聚合是一种技术,通过该技术,将大量测量值组合成关于在时间窗口期间发生的度量事件的精确或估计统计数据。OTLP协议传输这样的聚合度量。OpenTelemetry API为每个仪器提供了一个默认聚合,可以使用视图覆盖这些聚合。OpenTelemetry项目旨在提供可视化工具和遥测后端支持的默认聚合
与请求追踪不同,metrics旨在提供汇总的统计信息。例如:
- 报告每个协议类型的服务读取的字节总数。
- 报告读取的字节总数和每个请求的字节数。
- 报告系统调用的持续时间。
- 报告请求大小以确定趋势。
- 报告进程的CPU或内存使用情况。
- 报告帐户的平均余额值。
- 报告正在处理的当前活动请求
Views
视图为SDK用户提供了自定义SDK输出的度量的灵活性。他们可以自定义要处理或忽略的Metrics。他们可以自定义聚合以及要在度量上报告的属性
Baggage
-
Baggage提供了一种统一的方式来存储和传播轨迹和其他信号中的信息。在OpenTelemetry中,Baggage是跨段之间传递的上下文信息。它是一个键值存储,位于跟踪中的span上下文旁边,使在该跟踪中创建的任何span都可以使用值。例如,假设您希望在跟踪中的每个跨度上都有一个CustomerId属性,该属性涉及多个服务;但是,
-
CustomerId仅在一个特定服务中可用。为了实现您的目标,您可以使用OpenTelemetry Baggage在系统中传播此值。
-
OpenTelemetry使用上下文传播来传递Baggage,每个不同的库实现都有传播程序,可以解析并使Baggage可用,而无需显式实现它Baggage不属于span属性的子集,因此不会自动出现在子系统span的属性中,需要明确的将信息从baggage中取出并附加到span的属性。
Resources
资源是一种特殊类型的属性,适用于流程生成的所有跨度。这些应该用于表示关于非临时进程的底层元数据,例如,进程的主机名或其实例ID。资源应该在初始化时分配给跟踪程序提供程序,并且创建时与属性非常相似
logs
无go版本
日志是一种带有时间戳的文本记录,可以是结构化的(推荐的),也可以是非结构化的,带有元数据。在所有遥测信号日志中,具有最大的遗留问题。大多数编程语言都有内置的日志记录功能或众所周知的、广泛使用的日志记录库。尽管日志是一个独立的数据源,但它们也可以连接到跨度。在OpenTelemetry中,任何不属于分布式跟踪或度量的数据都是日志。例如,事件是一种特定类型的日志。
日志通常包含详细的调试/诊断信息,例如操作的输入、操作的结果以及该操作的任何支持元数据对于跟踪和度量,OpenTelemetry采用了一种干净的设计方法,指定了一个新的API,并在多语言SDK中提供了此API的完整实现OpenTelemetry使用日志的方法不同。由于现有的日志记录解决方案在语言和操作生态系统中广泛存
在,OpenTelemetry充当了这些日志、跟踪和度量信号以及其他OpenTelemetrys组件之间的“桥梁”。事实上,由于这个原因,日志的API被称为“Logs Bridge API”
Log Appender / Bridge
作为应用程序开发人员,您不应该直接调用Logs Bridge API,因为它是为日志库作者提供的,用于构建日志附加程序/桥。相反,您只需使用首选的日志记录库,并将其配置为使用能够将日志发送到OpenTelemetry LogRecordExporter的日志附加器(或日志桥)
Logger Provider
记录器提供程序(有时称为LoggerProvider)是记录器的工厂。在大多数情况下,Logger Provider只初始化一次,其生命周期与应用程序的生命周期相匹配。Logger Provider初始化还包括Resource和Exporter初始化是Logs Bridge API的一部分,仅当您是日志库的作者时才应使用
Logger
Logger创建日志记录。记录器是从日志提供程序创建的
是Logs Bridge API的一部分,仅当您是日志库的作者时才应使用
Log Record Exporter
日志记录导出器将日志记录发送给使用者。此使用者可以是调试和开发时的标准输出、OpenTelemetry收集器或您选择的任何开源或供应商后端
Log Record
日志记录表示事件的记录。在OpenTelemetry中,日志记录包含两种字段:
- 具有特定类型和含义的命名顶级字段
- 任意值和类型的资源和属性字段
日志记录顶部字段:
Timestamp 事件发生的时间
ObservedTimestamp 观察到事件的时间
TraceId 请求跟踪ID
SpanId 请求跨度ID
TraceFlags W3C跟踪标志
SeverityText 严重性文本(也称为日志级别)
SeverityNumber 严重程度的数值
Body 日志记录的正文
Resource 描述日志的来源
InstrumentationScope 描述发出日志的作用域
Attributes 有关该事件的其他信息
详见文档:https://opentelemetry.io/docs/specs/otel/logs/data-model/
Trace(跟踪)原理
- 开始一个span
- 当app想要记录一次trace,需要在代码里调用对应start方法,这个方法会返回一个span。后续span可以调用span的end接收这次的trace
- 开始初始化span,保存span 的 TraceID,SpanID,以及 span 的attributes,events,links,以及处理 span 限制的 spanLimits,以及 span 的 startTime,span的parent span,span 的 name 等span 需要的相关属性。
- 初始化处理 span 的所有类型的 processors,根据定义的 processor 去处理 span,目前只支持 simple 和 batch 两种,simple 是不推荐在生产环境用,因为是同步的 call,而且是一条一条的生产上推荐使用 batch,性能好。
- 根据配置的所有 span 的 processors,使用每一个 processor 的 OnStart 的去处理 span,这里的 OnStart 其实是空实现。不管是 simple 类型的,还是 batch 类型的,目前都是一个是个空的方法,这个方法的定义的作用就是在开始处理 span 的时候,做一些处理。最后返回一个初始化后的 span 给到客户 (注意,要想让这个 span 真正的进入到整个 trace 里,还要调用 span 对象的 End 方)。
- 由 tracer 返回开始的 span。
- 当 call span 的 End 方法时候就会对 span 做一下快照,这里的快照只是将可读写的 span,复制到只读的 ReadOnlySpan 对象,通过 processor 的 OnEnd 方法放到 processor 的 queue 中,可见放到 queue 中等待发送出去的 span 都是只读的 sp.sp.OnEnd(s.snapshot()))。
- 从 queue 获取 span 放到 batch 中,当 batch 的数量满了,或者到达了固定时间,都会将已经处于 end 状态的 span 通过 exporter 发送出去。
- 从 queue 获取 span 放到 batch 中,当 batch 的数量满了,或者到达了固定时间,都会将已经处于 end 状态的 span 通过 processor 的 exportSpans 方法发送出去。
- exportSpans 方法处理,只会去拿 processor 的 batch 字段的数据去处理,每次 exportSpans 时都是一次处理一个 batch 的数据。
- 使用一个 batch 里的数据,进行转换成 collector 能接受的 trace 数据。
- 使用 exporter 的 client,upload trace 数据到 collector。
- 循环所有的 trace 数据,封装成 tracepb.Span, 由 Spans 方法再封装成 tracepb.ResourceSpans。
- 定义一个 traces 发送的请求。
- 进行发送 traces。
- 在发送 traces 的时候,在 send 中 call singleSend 去发送数据,会有失败重试。
- 使用 http 或者 grpc 的client,发送 tracepb.ResourceSpans 数据到 collector。
- 将 batch 的数据处理完之后,清空一下 batch 字段,用于继续从 queue里面拿 span,用于下一个发送时机要去处理的 span 数据。