由于是刚开始编写js逆向类型的文章,难免会有不详细之处,敬请谅解
本次的目标是hongshu网的小说接口,我们进入官网随意找到一篇小说后,打开网络请求,分析接口
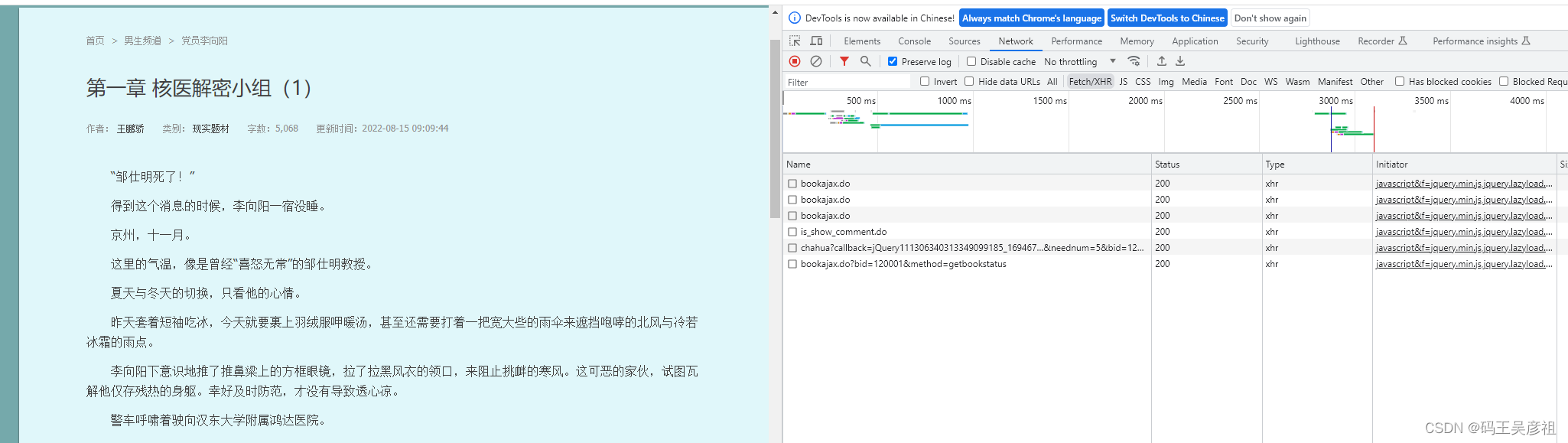
如图,可以看到有个bookajax.do 的接口让人值得怀疑,而且有三个接口,初步判断可能是接口之间进行互相调用,我们先打开接口查看一下数据
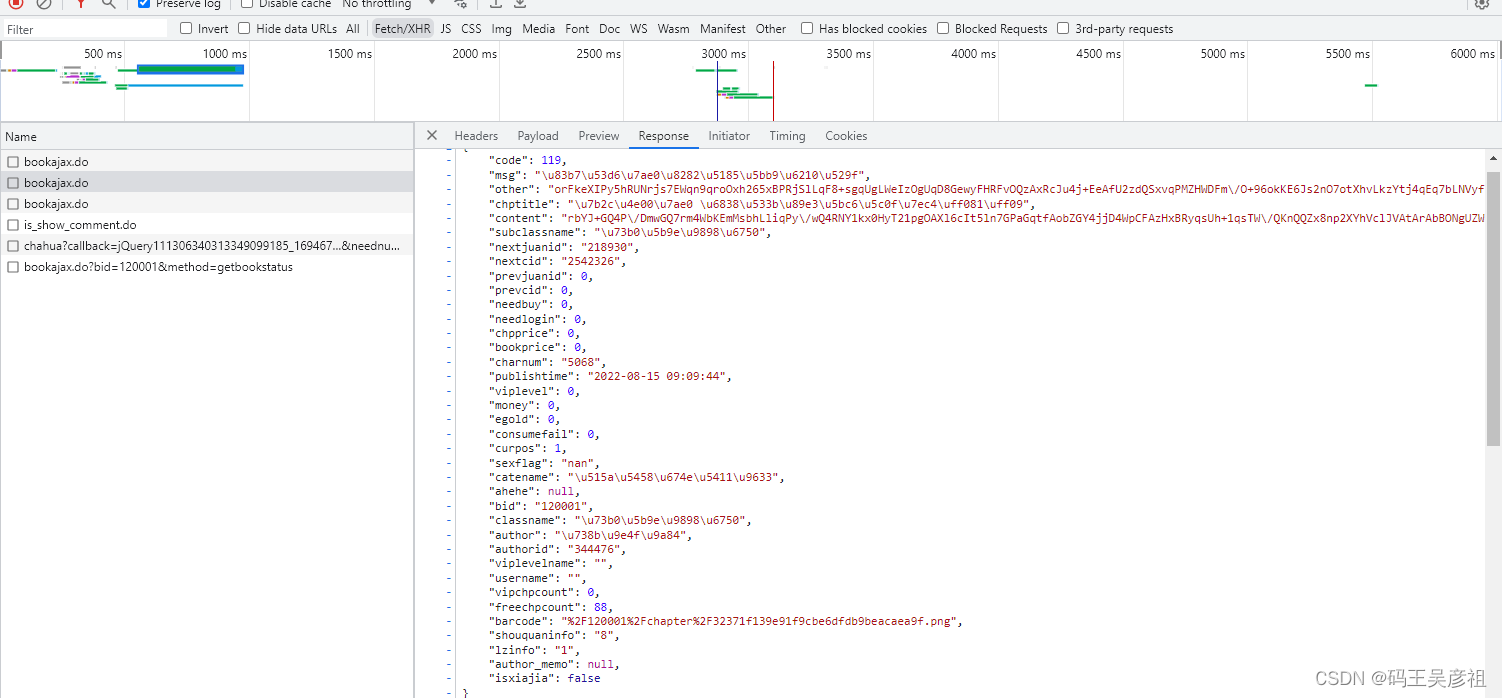
在第二个接口中看到如下数据,其中有一个字段content 是一个非常长的加密数据,有可能就是小说文章,这样一来,大概率就是前端加密了,我们首先跟栈进去看一下流程
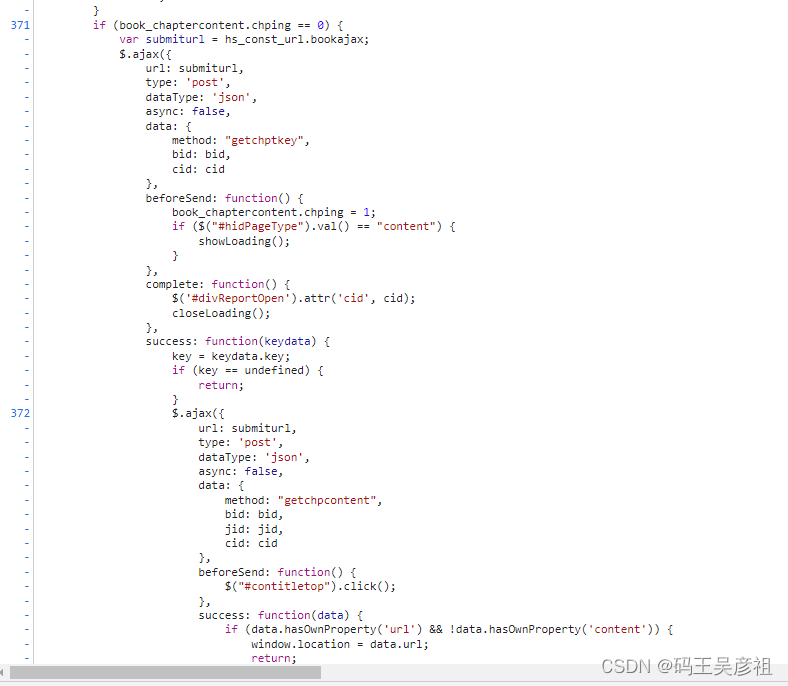
首先在接口附近,找到了其他接口调用该接口的地方,先传入getchptkey这个方法调用成功后,再传入getchpcontent这个方法调用,这证实了之前我们的猜测
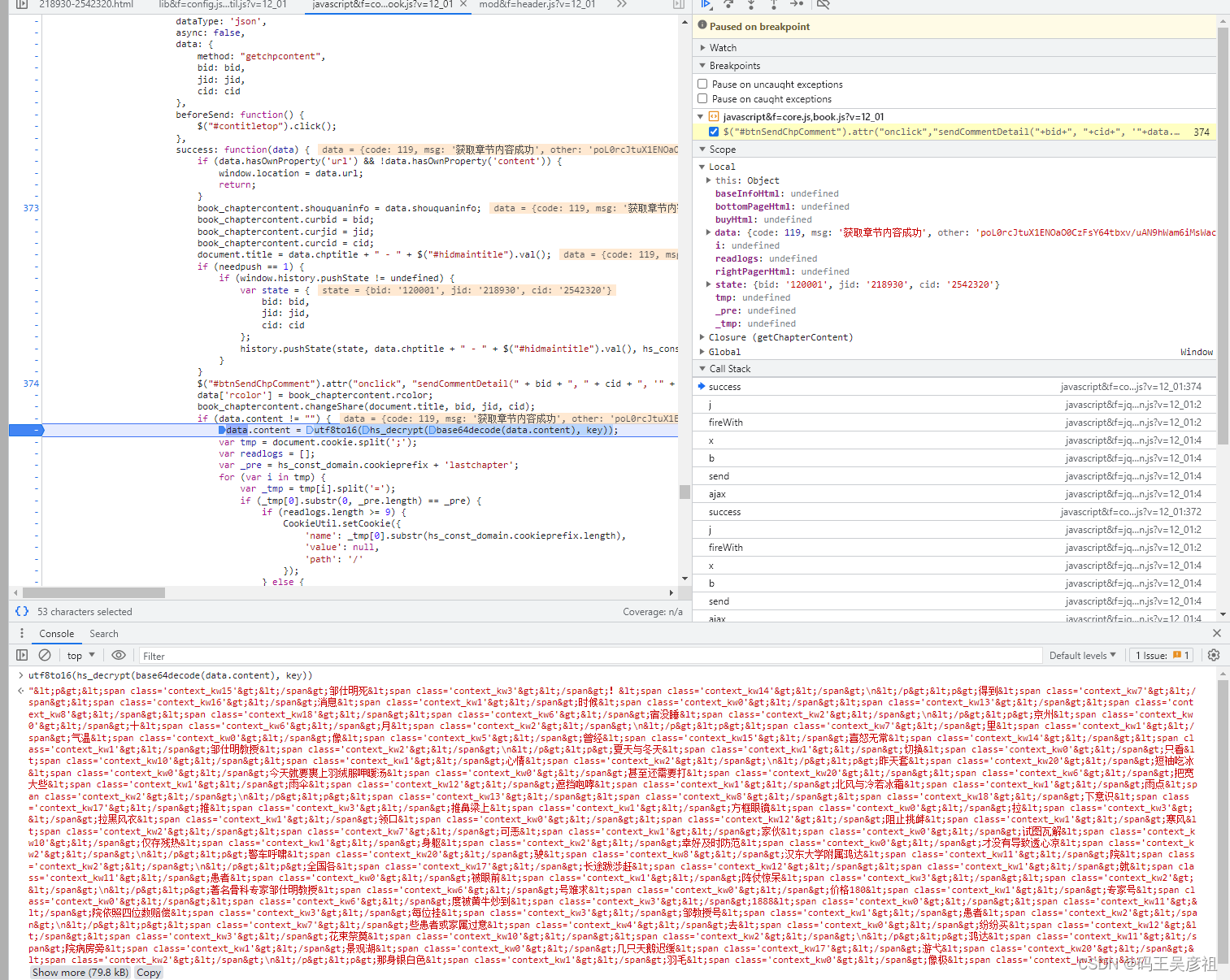
在往下跟,发现了有一个连续三次解密的地方,解密的参数刚好是data.content, 后面的参数key是第一个接口中获得的,然后我们在这里打上断点,我们将这段解密直接在控制台输出,得到一大段html标签+中文的组合,然后,查看一下解密方法
方法也很简单,直接将方法扣出来就行了,到此,第一层加密算是破解了,接着,来看第二层加密,也就是那些html标签,我们接着看一下流程下面的步骤
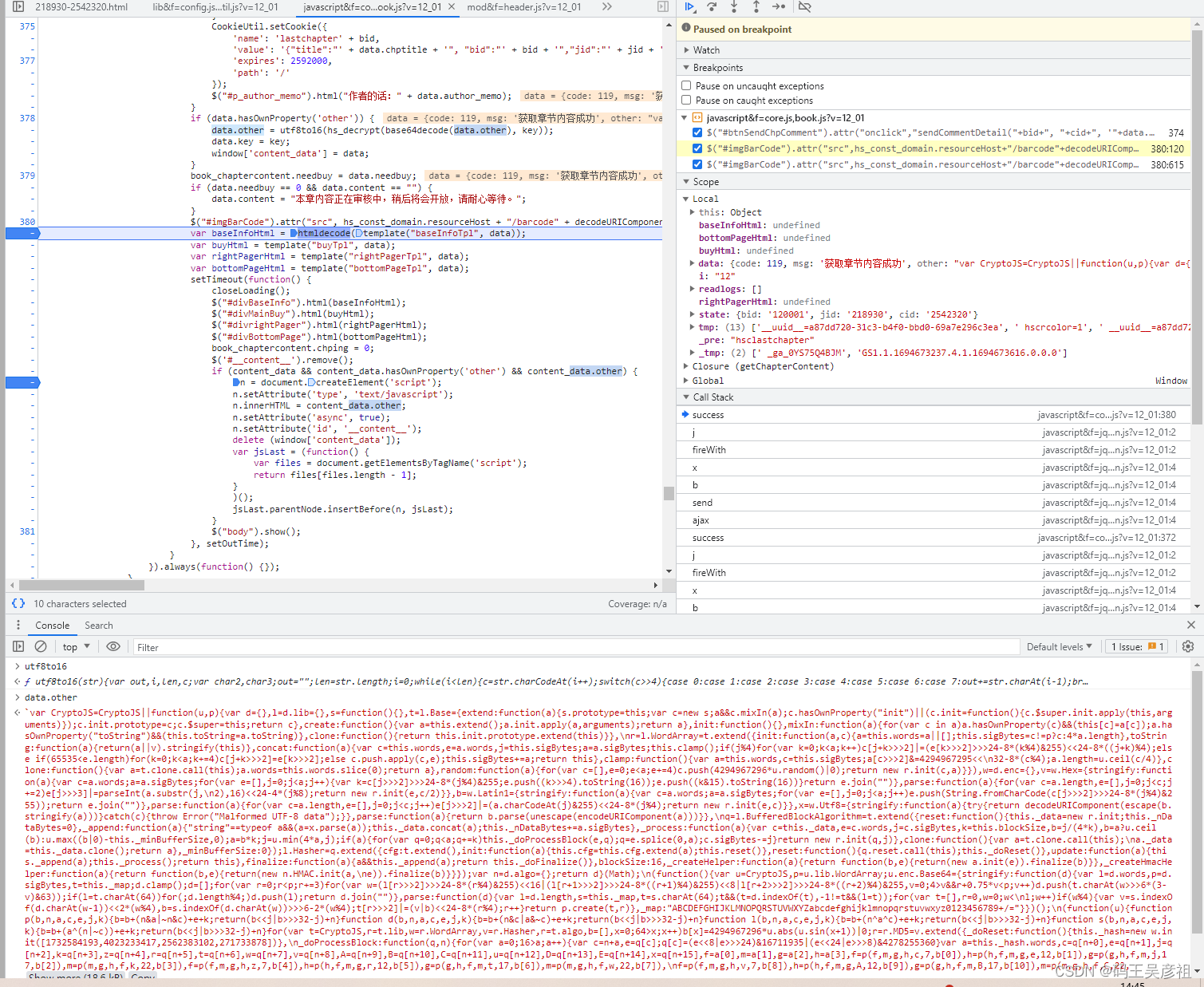
在下面,我们发现还对data.other 进行了一次解密,这里解密不再多说,与data.content 解密流程是差不多的,我们把解密出来后的data.other 打上断点后再控制台输出一下,发现是一大串js代码,接着根据下文分析,网页又调用了一个异步的js方法,这个js正是这个大串的js代码,这段js执行完成后,网页正常显示,所以我们怀疑,这段js就是前段解密的所在,我们将这段代码复制下来之后,用nodejs运行后发现缺少document环境,我们将环境补齐后,运行一切正常,这时分析了一下这段代码

代码的最后,正是还原网页文字的部分,将words这个变量依次替换成对应的标签,我们将words输出一下

这样一来,基本就真相大白了,我们将代码组合一下

成功抓取显示原文!