本人纯python小白一枚!目前刚自学python爬虫三个礼拜(python语法一个礼拜,爬虫两星期),以后还会继续深入,因为它真的是一门“面向小白”、容易入门而且还十分有趣的脚本语言。
废话不多说,先介绍代码功能
支持输入小说名或者作者名两种方式进行爬取,因为网站排行榜小说数目比较庞大,使用单一主线程爬取速度过慢,所以import了threading模块进行多线程crawl,实测排行榜上小说两分钟可以找完。
先上链接:https://m.37zw.net/top/allvisit_1/
贴上效果图



扫描二维码关注公众号,回复:
11468703 查看本文章

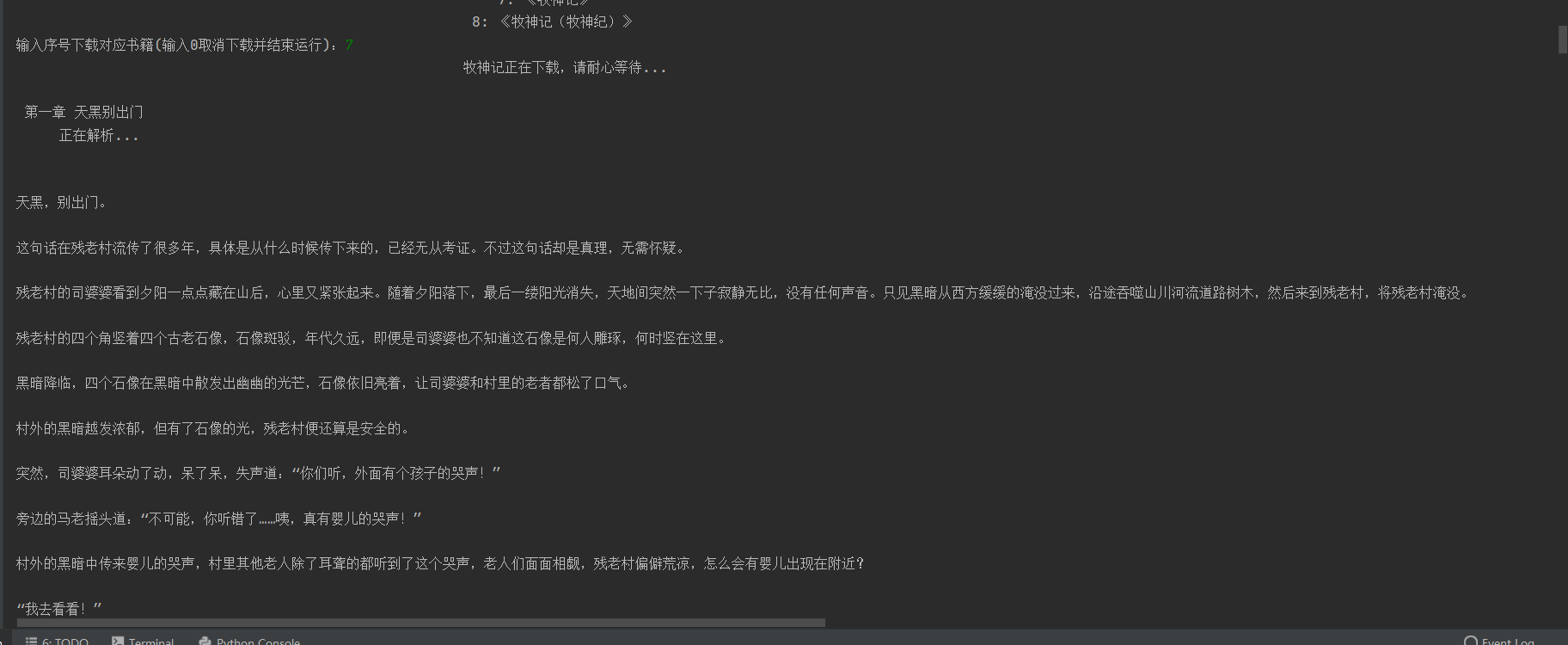
还支持通过输入书名查找,就不演示了,原理相似,代码附上,有兴趣欢迎互相交流!!
1 import requests 2 import re 3 from queue import Queue 4 from threading import Thread 5 from bs4 import BeautifulSoup 6 7 # 创建队列存储所有网页信息 8 def creatqueue(): 9 queue_page = Queue() 10 # 初始链接 11 start_url = '这里是链接' 12 response = requests.get(start_url) 13 response.encoding = response.apparent_encoding 14 pattern = re.compile('第1/(.*?)页') 15 pages = int(pattern.search(response.text).group(1)) 16 # 随机排页 17 # set_page = set() 18 # for page in range(1, pages+1): 19 # set_page.add(str(page)) 20 # for i in range(len(set_page)): 21 # queue_page.put(set_page.pop()) 22 23 # 顺序排页 24 for page in range(1, pages+1): 25 queue_page.put(str(page)) 26 27 return queue_page 28 29 # 重写线程对象,通过书名查找书籍 30 class Search_By_Name(Thread): 31 def __init__(self, name, tname, queue_page, stop_thread, print_once): 32 super(Search_By_Name, self).__init__() 33 self.name = name 34 self.tname = tname 35 self.queue_page = queue_page 36 self.book_url = '' 37 self.stop_thread = stop_thread 38 self.print_once = print_once 39 40 def run(self): 41 print('%s上线了, 拼命搜刮中...' % self.tname) 42 while(1): 43 if len(self.stop_thread) >0: 44 break 45 try: 46 page = self.queue_page.get(True, 5) 47 except: 48 break 49 url = 'https://m.37zw.net/top/allvisit_'+page 50 print('正在查找第%d页...' % int(page)) 51 if self.search_name(url) ==True : 52 print(('%s在第%d页被%s找到了!' % (self.name, int(page), self.tname)).center(120, '-')) 53 self.down_book() 54 break 55 if self.queue_page.empty() and len(self.print_once) == 0: 56 self.print_once.append(1) 57 break 58 print('搜刮完毕,%s下线了' % self.tname) 59 60 def search_name(self, url): 61 r = requests.get(url) 62 r.encoding = r.apparent_encoding 63 pattern = re.compile('<a href="#">.*?</a><a href="(.*?)" class="blue">%s</a>' % self.name) 64 result = pattern.search(r.text) 65 if result !=None: 66 self.stop_thread.append(1) 67 self.book_url = 'https://m.37zw.net'+result.group(1)+'index_1.html' 68 print(self.book_url) 69 return True 70 71 def down_book(self): 72 # body > div:nth-child(6) > span.middle > select > option:nth-child(1) 73 print("{:^120}".format("%s正在下载,请耐心等待..." % self.name)) 74 url = self.book_url 75 r = requests.get(url) 76 r.encoding = r.apparent_encoding 77 soup = BeautifulSoup(r.text, 'lxml') 78 pages = soup.select('body > div:nth-child(6) > span.middle > select > option') 79 80 for page in pages: 81 start_url = 'https://m.37zw.net'+page['value'] 82 s = requests.Session() 83 r_1 = s.get(start_url) 84 r_1.encoding = r_1.apparent_encoding 85 h = BeautifulSoup(r_1.text, 'lxml') 86 chapters = h.select('body > div.cover > ul > li > a') 87 88 for chapter in chapters: 89 url = 'https://m.37zw.net' + chapter['href'] 90 r_2 = s.get(url) 91 r_2.encoding = r_2.apparent_encoding 92 h2 = BeautifulSoup(r_2.text, "lxml") 93 title = h2.select_one('div#nr_title') 94 print(title.text, '\t', '正在解析...') 95 ch = h2.select_one('div#nr1') 96 ch_new = re.sub('三七中文 www.37zw.net', '', ch.text).replace('o','。').replace('()','').replace(' ',' ').replace(' ', '\n\n').replace('[三七中文手机版 m.37zw.c。m]', '') 97 print(ch_new) 98 99 with open('D:\迅雷下载\书籍类\%s.txt' % self.name, 'a+', encoding='utf-8') as f: 100 str1 = title.text.center(30, ' ') 101 f.write(str1) 102 f.write(ch_new) 103 print('下载完毕!') 104 f.close() 105 106 107 class Search_By_Author(Thread): 108 def __init__(self, aname, tname, queue_page, book_url, book_name): 109 super(Search_By_Author, self).__init__() 110 self.aname = aname 111 self.tname = tname 112 self.queue_page = queue_page 113 self.book_url = book_url 114 self.book_name = book_name 115 def run(self): 116 print('%s上线了, 拼命搜刮中...' % self.tname) 117 while (1): 118 try: 119 page = self.queue_page.get(True, 10) 120 except: 121 break 122 url = 'https://m.37zw.net/top/allvisit_' + page 123 print('正在查找第%d页...' % int(page)) 124 self.search_author(url, int(page)) 125 126 127 print('搜刮完毕,%s下线了' % self.tname) 128 129 def search_author(self, url, page): 130 r = requests.get(url) 131 r.encoding = r.apparent_encoding 132 # <p class="line"><a href="#">.*?</a><a href="(.*?)" class="blue">(.*?)</a>/%s</p> 133 pattern = re.compile('<p class="line"><a href="#">.*?</a><a href="(.*?)" class="blue">(.*?)</a>/%s</p>' % self.aname) 134 result = pattern.findall(r.text) 135 if len(result) >0: 136 for res in result: 137 bok_url, bok_name = res 138 self.book_url.append('https://m.37zw.net' + bok_url + 'index_1.html') 139 self.book_name.append(bok_name) 140 print('------%s在第%d页找到%s的——《%s》------' %(self.tname, page, self.aname, bok_name)) 141 142 143 def down_book(self, n): 144 # body > div:nth-child(6) > span.middle > select > option:nth-child(1) 145 print("{:^120}".format("%s正在下载,请耐心等待..." % self.book_name[n])) 146 url = self.book_url[n] 147 r = requests.get(url) 148 r.encoding = r.apparent_encoding 149 soup = BeautifulSoup(r.text, 'lxml') 150 pages = soup.select('body > div:nth-child(6) > span.middle > select > option') 151 152 for page in pages: 153 start_url = 'https://m.37zw.net' + page['value'] 154 s = requests.Session() 155 r_1 = s.get(start_url) 156 r_1.encoding = r_1.apparent_encoding 157 h = BeautifulSoup(r_1.text, 'lxml') 158 chapters = h.select('body > div.cover > ul > li > a') 159 160 for chapter in chapters: 161 url = 'https://m.37zw.net' + chapter['href'] 162 r_2 = s.get(url) 163 r_2.encoding = r_2.apparent_encoding 164 h2 = BeautifulSoup(r_2.text, "lxml") 165 title = h2.select_one('div#nr_title') 166 print(title.text, '\t', '正在解析...') 167 ch = h2.select_one('div#nr1') 168 # ch_new = re.sub(r'<div id="nr1">|三七中文 www.37zw.net|</div>', '', str(ch)).replace(r'<br/>', '\n').replace('o','。').replace('()','').replace(' ',' ') 169 ch_new = re.sub('三七中文 www.37zw.net', '', ch.text).replace('o','。').replace('()','').replace(' ',' ').replace(' ', '\n\n').replace('[三七中文手机版 m.37zw.c。m]', '') 170 print(ch_new) 171 with open('D:\迅雷下载\书籍类\%s.txt' % self.book_name[n], 'a+', encoding='utf-8') as f: 172 str1 = title.text.center(30, ' ') 173 f.write(str1) 174 f.write(ch_new) 175 print('下载完毕!') 176 f.close() 177 178 179 def creatS_B_Nthread(name, queue_page): 180 tname = [] 181 # 设置线程数,cpu允许且网站不设限的情况下调高可以增加爬虫效率 182 tnum = 66 183 for i in range(1, tnum + 1): 184 tname.append('%d号搜书虫' % i) 185 stop_thread = [] 186 print_once = [] 187 tlist = list() 188 for name_t in tname: 189 t = Search_By_Name(name, name_t, queue_page, stop_thread, print_once) 190 tlist.append(t) 191 t.start() 192 for t in tlist: 193 t.join() 194 end_print(queue_page, print_once) 195 196 197 def creatS_B_Athread(aname, queue_page): 198 tname = [] 199 # 设置线程数,cpu允许且网站不设限的情况下调高可以增加爬虫效率 200 tnum = 66 201 for i in range(1, tnum + 1): 202 tname.append('%d号搜书虫' % i) 203 book_url = [] 204 book_name = [] 205 tlist = list() 206 for name_t in tname: 207 t = Search_By_Author(aname, name_t, queue_page, book_url, book_name) 208 tlist.append(t) 209 t.start() 210 for t in tlist: 211 t.join() 212 213 if queue_page.empty(): 214 if len(book_name) == 0: 215 print('------Too low!!! 这个网站没有%s的书------' % aname) 216 else: 217 print(('搜书虫们共为你找到%d本%s的书' % (len(book_name), aname)).center(120, '-')) 218 for i in range(len(book_name)): 219 s = '%d: 《%s》' % (i + 1, book_name[i]) 220 print(s.center(120, ' ')) 221 for i in range(len(book_name)): 222 n = int(input('输入序号下载对应书籍(输入0取消下载并结束运行):')) 223 if n == 0: 224 break 225 Search_By_Author(aname, name_t, queue_page, book_url, book_name).down_book(n - 1) 226 227 228 229 def end_print(queue_page, print_once): 230 if len(print_once) > 0: 231 print('------Too low!!! 这个网站没有这部小说------'.center(120, '-')) 232 233 def main(): 234 # 创建队列存储所有网页信息 235 queue_page = creatqueue() 236 # 选择搜书方式 237 way = int(input('输入数字选择对应搜书方式:(按书名查找: 1 ; 按作者方式: 2)')) 238 if way == 1: 239 name = input('输入要查找的书名:') 240 # 创键书名查找线程 241 creatS_B_Nthread(name, queue_page) 242 if way == 2: 243 aname = input('输入要查找的作者:') 244 # 创键作者查找线程 245 creatS_B_Athread(aname, queue_page) 246 247 print('结束') 248 249 if __name__ == '__main__': 250 main()