数据仓库与数据挖掘小结
企业开发
2024-01-08 22:15:11
阅读次数: 0
更加详细的只找得到pdf版本
| 填空10分
判断并改错10分
计算8分
综合20分
|
| 客观题 |
|
| 填空10分
判断并改错10分--错的要改 |
mooc中的--尤其考试题 |
| |
|
|
| 名词解释12分 |
|
| 简答题40分 |
|
| 综合 |
|
| C1 |
| 什么是数据挖掘?概念是什么? |
哪些操作属于数据挖掘操作,哪些操作不属于
数据:海量、多源异构 操作:从大量的数据中提取出有趣的(重要、隐含、以前未知、潜在有用)模式或知识。 数据分析与数据挖掘有区别
数据挖掘AKA知识发现KDD |
| 数据挖掘的流程 |
在数据管理的视角下,数据挖掘的流程是什么?有哪些环节?一定要注意是一个迭代反馈的过程
| 数据集成 |
不同数据源中描述同一条数据对象《变成一个比较统一的数据信息 |
| 数据清理 |
错误、异常、冗余、缺失 |
| 进入数据仓库 |
按主题存储数据 |
| 选择、变换 |
把数据仓库中的数据变成与数据挖掘任务相关的数据集
选择:选择相关数据、属性特征
变换:格式可能不满足算法要求、数据量纲;特征转换--相乘相除etc… |
| 得到和任务相关的数据集,可供我们使用算法 |
|
| 数据挖掘 |
设计或选择合适的模型,用于任务相关的数据上,得到模式 |
| 知识评估 |
若不满足,考虑到之前所有步骤--哪个或哪几个步骤不合适 |
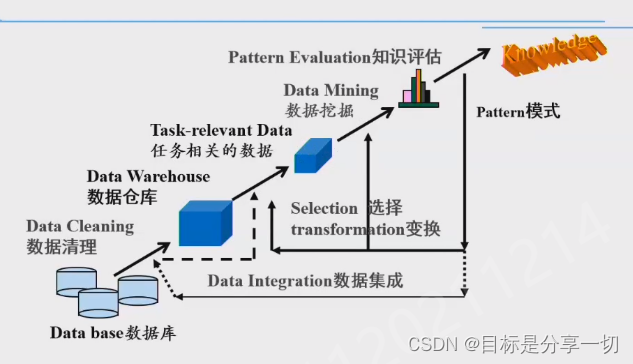
反复试验的过程
|
| 数据挖掘的任务 |
| 分类回归 |
利用历史记录预测未来的值--预测问题 |
| 聚类 |
|
| 相关性分析与关联分析-关联规则挖掘 |
|
| 异常检测 |
|
| 预测性任务 |
|
| 描述性任务 |
关联规则挖掘-物品之间共线关系 |
|
|
| C2 |
| 数据集的主要特征 |
维度、分辨率、稀疏性 |
| 识别数据属性值中的异常的方法 |
画图【箱线图】、统计的3σ原则 |
| 标称【标称属性中的二分属性->对称二分与不对称二分】、序数、数值,如何计算这些数据类型的相似度?如果数据的属性是混合类型的数据类型的相似度怎么计算?【核心】 |
| 数据对象的相似性度量问题【两个行的相似性】【属性之间的相似性是两个列】 |
| 相似性和相异性此涨彼消 |
|
| 标称 |
| 
p为属性个数,m是两个对象属性取值相等的个数,p-m两个对象取值不相等的个数 |
| 二分
需要四个指标
非对称:
取0的可能性更高:尽管差异性很大但是因为取0概率高导致差异性不准


|
|
| 序数 |
取值转换为数值类型--把级别从低到高排序;
取值按公式转换

|
| 数值 |
用距离衡量

常用距离
| 闵氏距离 |


曼哈顿距离-出租车距离-沿着街道走走折线--高维

上确界距离 |
|
| 文档 |
余弦相似度

|
| 混合类型 |

f:每个属性
dij(f):在f属性上的相异度
前面为权重 |
|
| 属性之间的相关性 |
| 单相关和复相关 |
|
| 正相关和负相关 |
|
| 线性相关和非线性相关 |
|
| 不相关、完全相关、不完全相关 |
|

画散点图
相关系数 线性:
最大信息系数MIC:用于度量高维数据中属性变量之间强相关性
|
|
| 属性和属性间的计算属于相关性分析--方法 |
|
|
| C3 |
| 数据预处理主要包括哪些步骤? |
数据清理、数据集成、数据转换、数据约减

|
| 简述数据清理的主要任务、常用方法、流程 |
处理缺失数据、平滑噪声、识别或移除异常(属性值的异常)、解决数据不一致的问题…
常用方法
| 缺失值 |
删除;
插补

|
| 异常值 |

|
| 噪音 |
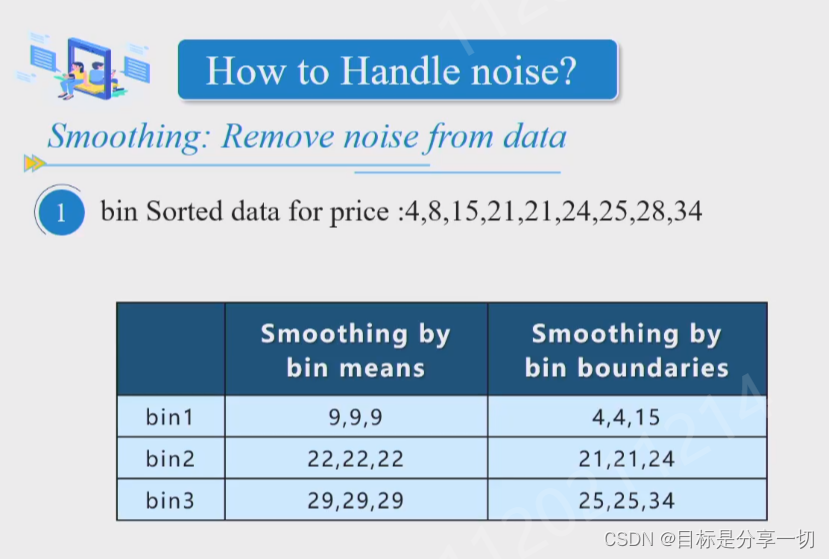
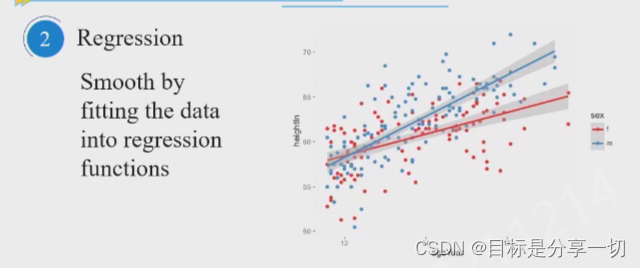

|
| 不一致 |
实体识别技术 |
| |
|
流程
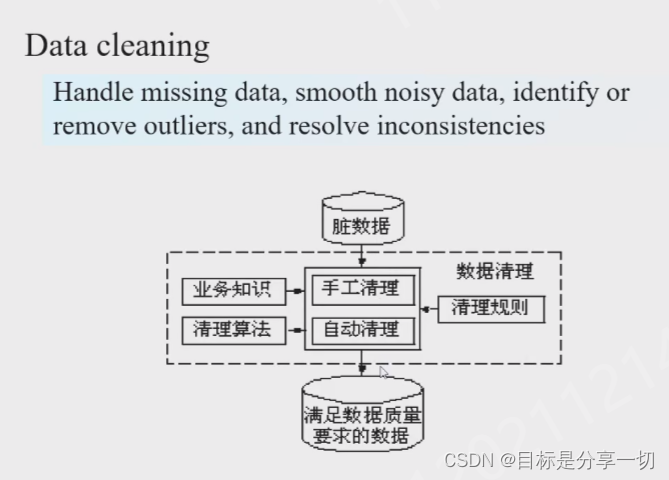
流程: 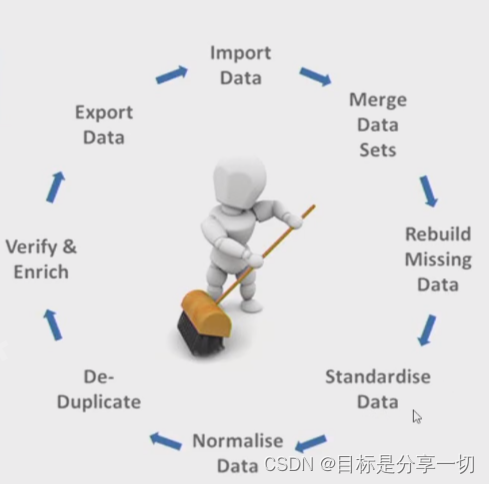
右侧是数据清理的过程,首先import data导入数据,集中相关数据,处理缺失值,标准化【max-min这种,目标是统一特征维度的量纲】、规范化【变换后吻合一个分布zscore】,重复性检测、修正错误与丰富,导出 |
| 常用离散化方法有哪些?【看下游任务】 |
| 无监督 |
|
| 有监督--类标签指导下 |
| 基于熵的方法 |


不断离散化 |
|
|
| 如何识别冗余属性? |
通过相关性分析发现冗余属性

数值属性:相关系数、协方差
标称类型:卡方检验


|
| 常用的约减方法--前三个对数据量压缩,PCA是无监督的降维 |
| 数据量的压缩 |
| 有参 |
| 回归 |

只保留参数wb,想生成数据集的时候直接在x上随机采样生成y值 |
| |
|
|
| 无参 |
| 聚类 |
对每个簇抽样 |
| 抽样 |

有放回、无放回、分层 |
|
|
| 维度压缩 |
| 无监督pca |
把原始的属性描述的特征空间映射为正交矩阵空间,尽可能多的保留原始数据信息
消除冗余--维度彼此独立
pca通过做正交矩阵分解,得到主成分,选前k个重要特征作为新的空间中的特征,把所有数据对象由前k个特征的线性组合表示 |
| 属性子集选择 |
Method1:删除冗余属性、删除不重要的…得到子集
Method2:添加最重要的、次重要的…得到子集
|
| Vs |
属性选择得到的特征有具体含义,PCA没有【黑箱】-可能可以得到非常好的特征提取但是可解释性差 |
|
|
|
| olap |
| 数仓的基本架构 |
|
| 简述数仓的数据模型及各模型特点 |
|
| 数据仓库与数据库的区别 |
|
|
| 关联规则挖掘 |
| 方法与评估指标
|
|
| |
|
| 两阶段 |
频繁项集的产生--关联规则的产生 |
| 频繁项集的实现 |
用了性质缩小频繁项集的空间 |
| 关联规则挖掘的内容 |
|
| 评估指标--常用支持度和置信度,并不一定是一个有意义的关联规则, |
提升度 |
|
| 聚类 |
| 聚类和分类的区别 |
|
| kmeans和DBSCAN的原理和流程和优缺点特点,对kmeans的缺点有哪些办法可以解决 |
| k值需要确定 |

设置不同k值求sse,考虑拐点附近的k值 |
| 初始聚类中心的选择 |

第一个随机选,下一个选离当前选择的最远的 |
| 对噪声点和异常敏感【因为均值敏感】 |
使用k-medoids用真实数据对象作为中心-复杂度高-由簇中的数据对象替代;用k中位数 |
| 球形簇【基于距离】 |
|
| 空簇 |
选sse贡献最大的点作为簇中心,从簇中选一个对sse贡献最大的点,

|
| 
|
尺寸: 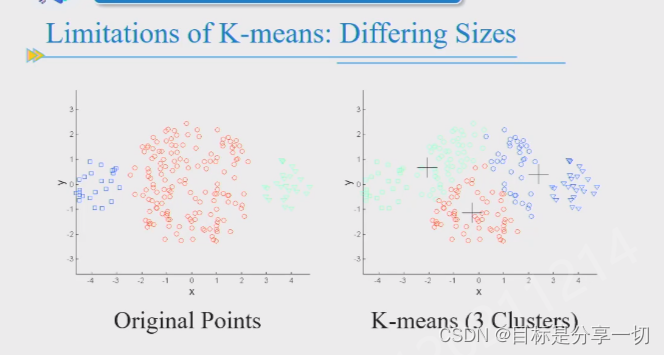
密度:
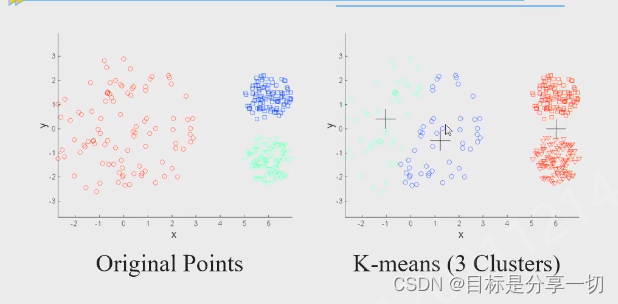
非凸:
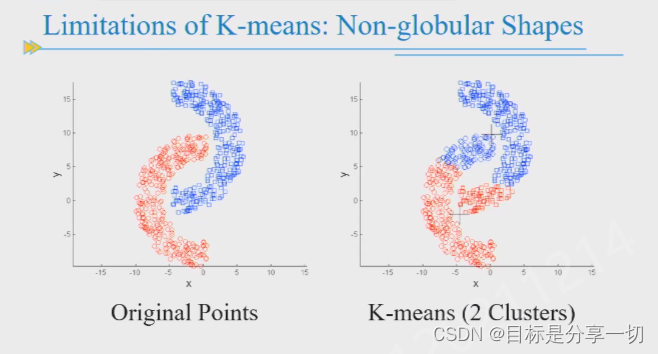
解决:

k取较大值分为多个小簇再合并 |
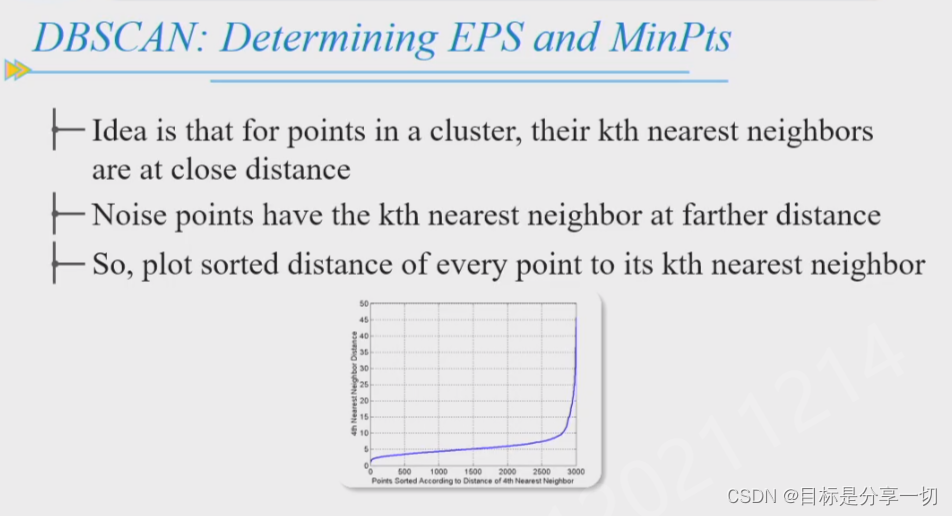
纵轴:第k个最近邻距离的变化范围
横轴:数据对象按最近邻距离编码
大部分数据对象的第k个最近邻的变化变化幅度不大,拐点飙升-异常点,当k取大,距离大
由此判断k |
| 聚类的评估指标--有监督【和分类一样】和无监督【规范化的互信息与轮廓系数】 |

标准化的互信息-Y是聚类标签,C是真实标签-I(Y,C)互信息=H(C )-H(Y|C)yc依赖性越高越好 
|
|
| 分类 |
| roc怎么画 |

tpr是召回率
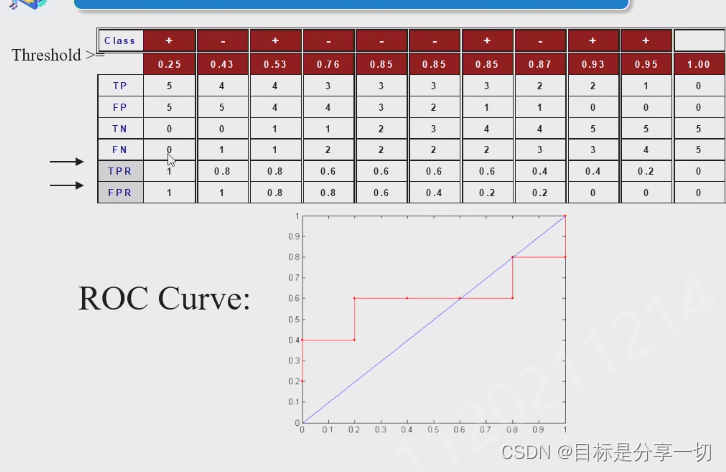
|
| 评估指标--精度召回率fscore |

|
| 决策树、贝叶斯、集成 |
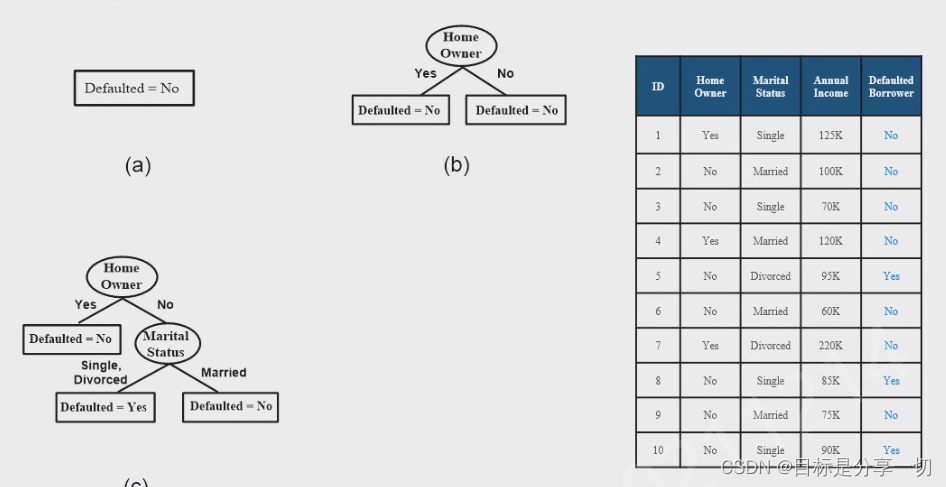
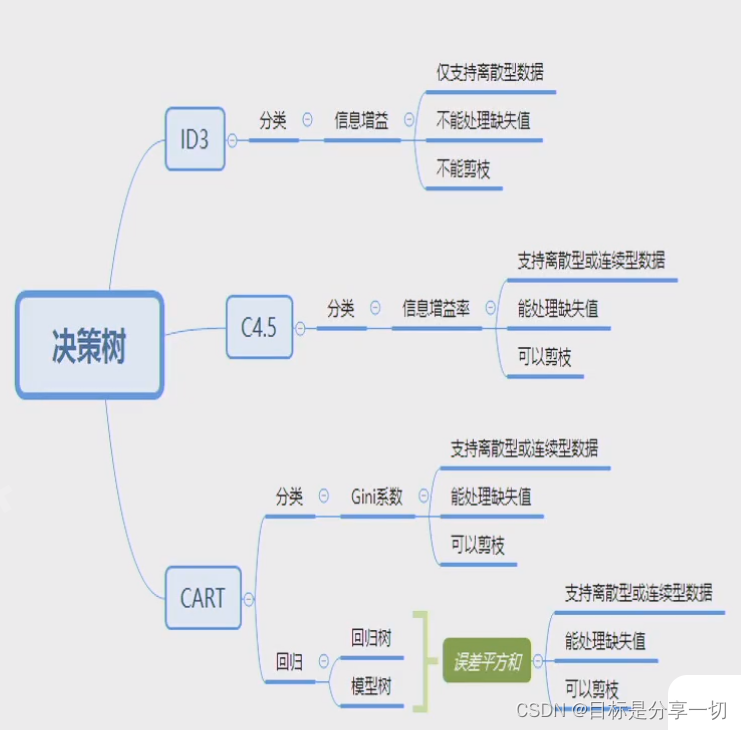

贝叶斯:易于实现,结果比较好,鲁棒的
有可能有依赖
集成

对于不稳定的分类器才有提升效果 |
| 评估框架--bootstrap cosostation??交叉验证的bootstrap |
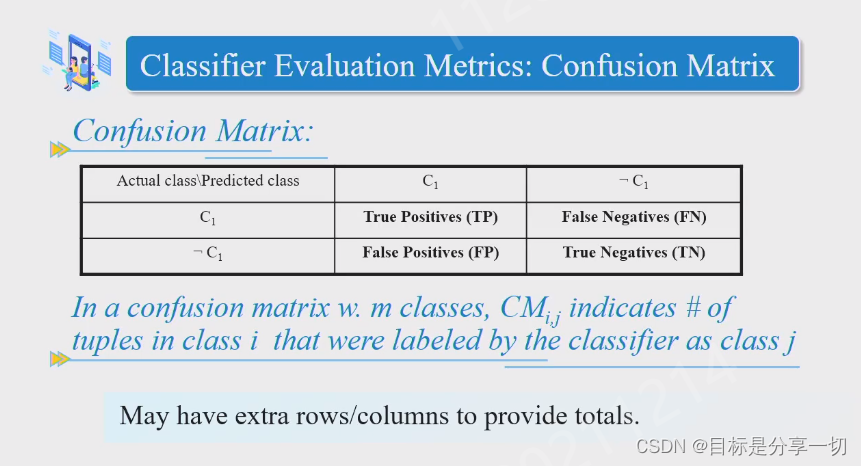
二分类问题 
正事例

|
|
| 异常 |
|
转载自blog.csdn.net/m0_62153438/article/details/135048873


