介绍数据工作中10个便捷的Pandas重要函数。
微信搜索关注《Python学研大本营》,加入读者群,分享更多精彩


6.合并数据帧
可以横向或纵地向合并多个数据帧。它将连接两个数据帧并返回一个合并后的数据帧。
例如:
combined_df = pd.concat([df1, df2])
可以根据一个共同的列合并两个数据帧。当想要合并共享公共标识符的两个数据框时,这种方法非常有用。
例如:
merged_df = pd.merge(df1, df2, on="common_col")
7.应用自定义函数
根据需要在行或列上应用自定义函数。
例如:
def cus_fun(x):
return x * 3
df["Sales_Tripled"] = df["SALES"].apply(cus_fun, axis=0)
这里编写了一个自定义函数,将每行的销售额值乘以3。axis=0表示本文要在列上应用自定义函数,axis=1表示本文要在行上应用该函数。
在之前的方法中,用户需要编写一个单独的函数,然后从apply()方法中调用它。Lambda函数可以帮助用户在apply()方法内部使用自定义函数。接下来看看如何做到这一点。
df["Sales_Tripled"] = df["SALES"].apply(lambda x: x * 3)
Applymap(应用映射):
还可以将自定义函数应用于数据帧中的每个元素,只需一行代码。但需要记住的一点是,它适用于数据帧中的所有元素。
例如:
df = df.applymap(lambda x: str(x))
它将把数据帧中所有元素的数据类型转换为字符串类型。
8.时间序列分析
在数学中,时间序列分析指的是对特定时间间隔内收集的数据进行分析,而Pandas具有执行此类分析的函数。
8.1 转换为DateTime对象模型
可以将日期列转换为日期时间格式,以便更容易进行数据操作。
例如:
df["ORDERDATE"] = pd.to_datetime(df["ORDERDATE"])
输出:
8.2 计算滑动平均值
使用这种方法,可以创建一个滑动窗口来查看数据。同时可以指定任意大小的滚动窗口。如果窗口大小为5,则表示该时间点上的数据窗口为5天。它可以帮助消除数据中的波动,并帮助识别随时间变化的模式。
例如:
rolling_avg = df["SALES"].rolling(window=5).mean()
输出:
9.交叉制表
可以在表格的两列之间执行交叉制表。它通常是一个显示各个类别出现频率的频率表。它可以帮助用户了解不同地区之间类别的分布情况。
例如:
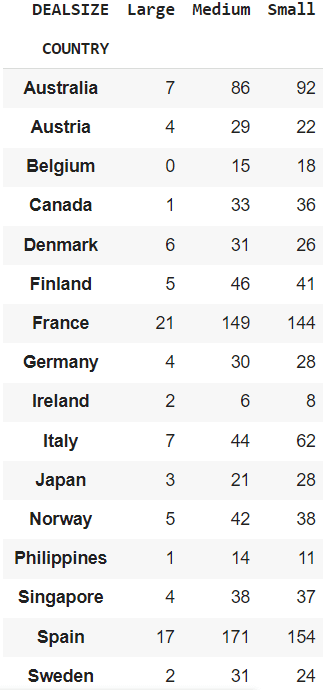
获取COUNTRY和DEALSIZE之间的交叉制表。
cross_tab = pd.crosstab(df["COUNTRY"], df["DEALSIZE"])
它可以显示不同国家订购的订单大小(DEALSIZE)。
10.处理异常值
数据中的异常值意味着某个点远远超出了平均范围。接下来通过一个例子来理解。假设有5个点,例如3、5、6、46、8。那么可以明确地说,数字46是一个异常值,因为它远远超出了其余各点的平均值。这些异常值可能会导致错误的统计结果,应该从数据集中删除。
在这种情况下,Pandas可以帮助用户找到这些潜在的异常值。可以使用一种称为四分位距(Interquartile Range,IQR)的方法来查找和处理这些异常值。如果想了解有关此方法的信息,可以阅读相关资料,也可以通过如下链接了解更多信息。
【Interquartile Range】:https://byjus.com/maths/interquartile-range/
接下来看看如何使用Pandas来做到这一点。
Q1 = df["SALES"].quantile(0.25)
Q3 = df["SALES"].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df["SALES"] < lower_bound) | (df["SALES"] > upper_bound)]
Q1是表示数据的第一四分位数,即数据的第25个百分位数,Q3是表示数据的第三四分位数,即数据的第75个百分位数。
lower_bound变量存储了用于查找潜在异常值的下界。它的值设置为Q1以下1.5倍的IQR。类似地,upper_bound计算上界,即Q3以上1.5倍的IQR。
然后,过滤掉小于下界或大于上界的异常值。
总结
Python的Pandas库使用户能够进行高级数据分析和操作。上述内容只是其中的一部分。可以在Pandas文档中找到更多工具。需要记住的重要一点是,可以根据自己的需求和使用的数据集来选择特定的技术。
【Pandas文档】:https://dataanalysispython.readthedocs.io/en/latest/
推荐书单
《Pandas1.x实例精解》
《Pandas1.x实例精解》详细阐述了与Pandas相关的基本解决方案,主要包括Pandas基础,DataFrame基本操作,创建和保留DataFrame,开始数据分析,探索性数据分析,选择数据子集,过滤行,对齐索引,分组以进行聚合、过滤和转换,将数据重组为规整形式,组合Pandas对象,时间序列分析,使用Matplotlib、Pandas和Seaborn进行可视化,调试和测试等内容。此外,该书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。《Pandas1.x实例精解》适合作为高等院校计算机及相关专业的教材和教学参考书,也可作为相关开发人员的自学用书和参考手册。
《Pandas1.x实例精解》![]() https://item.jd.com/13255935.html
https://item.jd.com/13255935.html

精彩回顾
微信搜索关注《Python学研大本营》,加入读者群,分享更多精彩
访问【IT今日热榜】,发现每日技术热点