
补充讲解链接
pandas常用函数,个人常用的
1.重命名列名
#用rename函数对数据进行重命名
import pandas as pd
df=pd.DataFrame(data=[
['x1','张三',177,92,1.5,'2019/3/23'],
['x2','李四',151,84,2.3,'2019/3/24']],columns=['学号','姓名','身高','语文成绩','学分','日期'])
df=df.rename(columns={
'语文成绩':'成绩'})
print(df)

2.增加列,删除列
import pandas as pd
df=pd.DataFrame(data=[
['x1','张三',177,92,1.5,'2019/3/23'],
['x2','李四',151,84,2.3,'2019/3/24']],columns=['学号','姓名','身高','语文成绩','学分','日期'])
#增加列
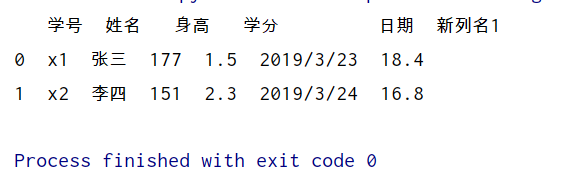
df['新列名']=[1,2]
df['新列名1']=df['语文成绩']*0.2
#删除列
df=df.drop(columns=['语文成绩'])#方法1
del df['新列名'] #方法2
print(df)
3.子集选择
import pandas as pd
df=pd.DataFrame(data=[
['x1','张三',177,92,1.5,'2019/3/23'],
['x2','李四',151,84,2.3,'2019/3/24'],
['x3','王五',167,80,3.2,'2019/3/25'],
['x4','韩六',175,77,1.2,'2019/3/26'],
['x5','赵七',153,87,1.6,'2019/3/27']
],columns=['学号','姓名','身高','语文成绩','学分','日期'])
#子集选择时,采用loc或ioc函数,loc读取 的是索引 ,而iloc读取的行数,相当于重新命名索引为 0,1,2...
print('读取索引范围[2,4]的数据\n',df.loc[2:4])
print('选择第2到第4行\n',df.iloc[1:4])
print('选择身高>160且成绩>80的数据,只要 姓名 学分 日期 \n',df.loc[(df['身高']>160) &(df['语文成绩']>80),['姓名','学分','日期']])
print('选择身高>160且成绩>80的数据, \n',df.loc[(df['身高']>160) &(df['语文成绩']>80)])

4.排序
import pandas as pd
df=pd.DataFrame(data=[
['x1','张三',177,92,1.5,'2019/3/23'],
['x2','李四',151,84,2.3,'2019/3/24'],
['x3','王五',167,80,3.2,'2019/3/25'],
['x4','韩六',175,77,1.2,'2019/3/26'],
['x5','赵七',153,87,1.6,'2019/3/27']
],columns=['学号','姓名','身高','语文成绩','学分','日期'])
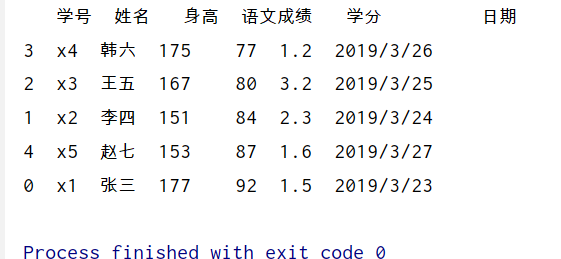
#排序 ,根据语文成绩排序,ascending=True 表示升序,False 表示降序
print(df.sort_values(by=['语文成绩'],ascending=True))
5.缺失值处理,缺失值处理一般使用fillna
import pandas as pd
import numpy as np
df=pd.DataFrame(data=[
['x1','张三',177,92,1.5,'2019/3/23'],
['x2','李四',151,84,2.3,'2019/3/24'],
['x3','王五',167,80,3.2,'2019/3/25'],
['x4','韩六',175,77,1.2,'2019/3/26'],
['x5','赵七',153,87,1.6,'2019/3/27']
],columns=['学号','姓名','身高','语文成绩','学分','日期'])
#缺失值处理
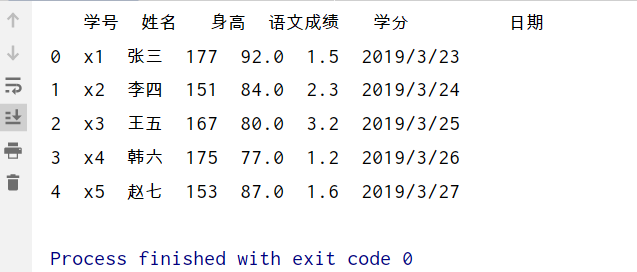
#先将张三的成绩设为nan
df.loc[(df['姓名']=='张三'),'语文成绩']=np.NaN
df['语文成绩']=df['语文成绩'].fillna(80)
print(df)
6.异常值处理
import pandas as pd
import numpy as np
df=pd.DataFrame(data=[
['x1','张三',177,92,1.5,'2019/3/23'],
['x2','李四',151,84,2.3,'2019/3/24'],
['x3','王五',167,80,3.2,'2019/3/25'],
['x4','韩六',175,77,1.2,'2019/3/26'],
['x5','赵七',153,87,1.6,'2019/3/27']
],columns=['学号','姓名','身高','语文成绩','学分','日期'])
#异常值处理
#将大于 "均值+2倍标准差“ 认为是异常值,用"均值+2倍标准差”替代
abnormal=df['语文成绩'].mean()+2*df['语文成绩'].std()
df.loc[df['语文成绩']>abnormal,'语文成绩']=abnormal
print(df)
7.分组统计
pandas的分组统计使用groupby函数参数as_index=False 表示统计后返回DataFrame类型的结果,否则返回Series类型的统计结果
import pandas as pd
import numpy as np
df=pd.DataFrame(data=[
['x1','张三',177,92,1.5,'2019/3/23','男','1'],
['x2','李四',151,84,2.3,'2019/3/24','男','2'],
['x3','王五',167,80,3.2,'2019/3/25','女','2'],
['x4','韩六',175,77,1.2,'2019/3/26','女','1'],
['x5','赵七',153,87,1.6,'2019/3/27','女','1']
],columns=['学号','姓名','身高','语文成绩','学分','日期','性别','班级'])
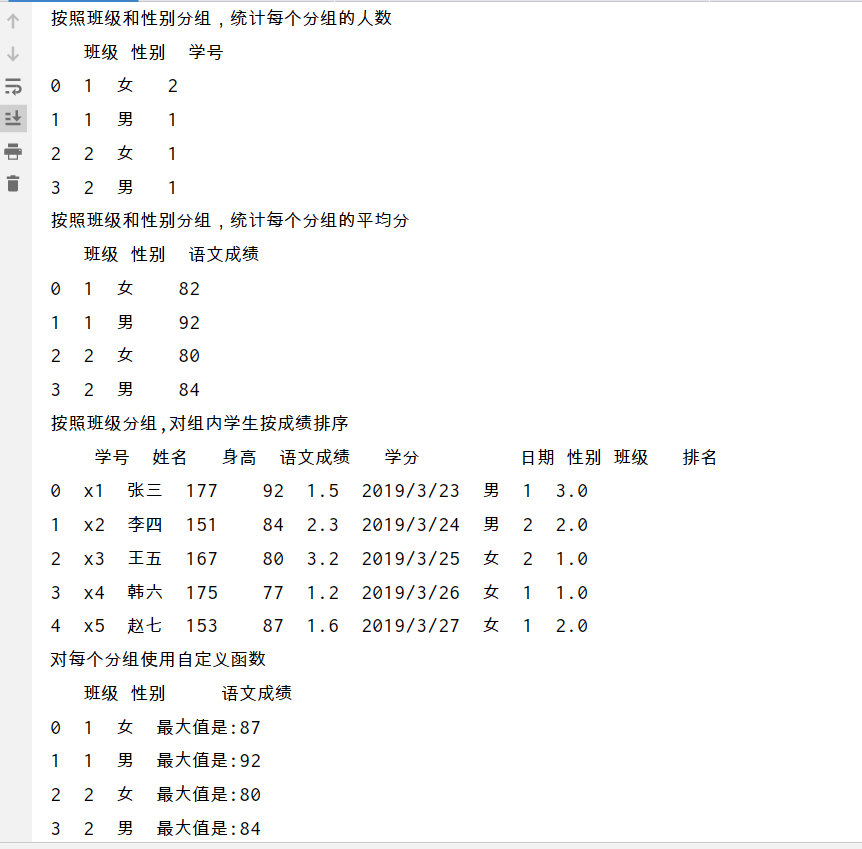
print('按照班级和性别分组,统计每个分组的人数\n',df.groupby(by=['班级','性别'],as_index=False)['学号'].count())
print('按照班级和性别分组,统计每个分组的平均分\n',df.groupby(by=['班级','性别'],as_index=False)['语文成绩'].mean())
rank=df.groupby(by=['班级'],as_index=False)['语文成绩'].rank()
df['排名']=rank
print('按照班级分组,对组内学生按成绩排序\n', df)
#对每个分组使用自定义函数
#agg 或者apply函数
def myfunc(series):
return '最大值是:'+str(series.max())
print('对每个分组使用自定义函数\n',df.groupby(by=['班级','性别'],as_index=False)['语文成绩'].agg(myfunc))
8.apply
对于apply函数,其作用是对目标集合中的每个元素执行相同的操作
import pandas as pd
import numpy as np
df=pd.DataFrame(data=[
['x1','张三',177,92,1.5,'2019/3/23','男','1'],
['x2','李四',151,84,2.3,'2019/3/24','男','2'],
['x3','王五',167,80,3.2,'2019/3/25','女','2'],
['x4','韩六',175,77,1.2,'2019/3/26','女','1'],
['x5','赵七',153,87,1.6,'2019/3/27','女','1']
],columns=['学号','姓名','身高','语文成绩','学分','日期','性别','班级'])
#对姓名这一列的每个元素加字幕xm
def myfunc(x):
return 'xm'+x
df['姓名']=df['姓名'].apply(myfunc)
print('对姓名这一列的每个元素加字幕xm\n',df)
#对姓名这一列的每个元素删除字幕xm
df['姓名']=df['姓名'].apply(lambda x:str(x).replace('xm', ''))
print('对姓名这一列的每个元素删除字幕xm\n',df)
#对于语文成绩这一列,如果有小于90分的,则该为90分
def myfunc1(x):
if x<90:
return 90
else:
return x
df['语文成绩']=df['语文成绩'].apply(myfunc1)
print('对于语文成绩这一列,如果有小于90分的,则该为90分\n',df)
#分组应用apply
def myfunc2(series):
return series.max()
df2=df.groupby(by=['班级'],as_index=False)['语文成绩'].apply(myfunc2)
print(df2)


作者:电气 余登武…
